

12 月 3 日、4日,2022 Apache IoTDB 物联网生态大会在线上圆满落幕。大会上发布 Apache IoTDB 的分布式 1.0 版本,并分享 Apache IoTDB 实现的数据管理技术与物联网场景实践案例,深入探讨了 Apache IoTDB 与物联网企业如何共建活跃生态,企业如何与开源社区紧密配合,实现共赢。
我们邀请到天谋科技高级开发工程师,Apache IoTDB PMC 田原参加此次大会,并做主题演讲——《大规模并行处理与边缘计算在 Apache IoTDB 中的实践》。以下为内容全文。
大家好,我是来自天谋科技的数据库内核研发工程师田原,今天我将为大家带来《大规模并行处理与边缘计算在 Apache IoTDB 中的实践》。
01 IoTDB MPP 架构概览
我今天的演讲内容会从以下四个方面进行展开。第一部分的内容是 Apache IoTDB MPP 架构的概览。
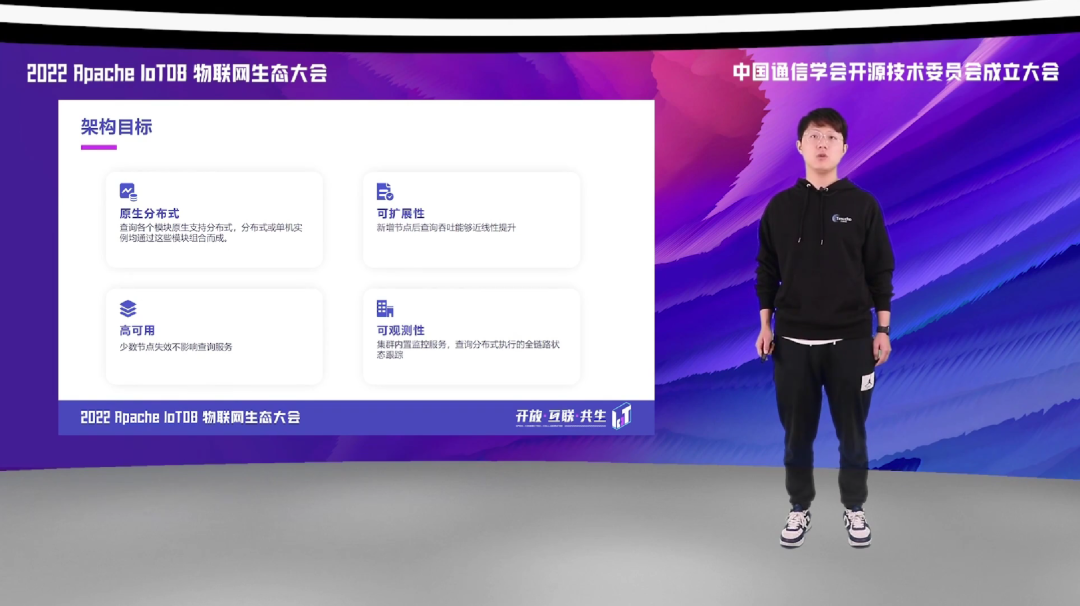
一句话说的好,叫“没有最好的架构,只有最合适的架构”,所以我们要想了解一个架构设计的目的,就需要了解它最开始设计的目标是什么。在设计之初,我们给这一次的查询架构定下了四个目标。
第一是原生分布式。查询各个模块需要原生支持分布式,也就是单机只是分布式的一个特殊情况,而单机和分布式都可以通过查询各个模块组合而成。
第二是可扩展性。我们希望随着新节点的加入,集群的整体 QPS 能够得到线性的提升。这对于用户是很关键的,因为可能用户在一开始时并没有那么大的业务量,而随着业务的发展,数据量也在不断的提升,这时需要新增节点,我们就需要提供 scale out 的能力。
第三点是高可用,也就是集群在部分节点宕机的情况下,查询依旧可以对外提供服务。
第四点是可观测性,这对于 DBA 的运维,以及查询研发人员的 debug 工作是非常重要的。
那集群节点角色,在之前同事的介绍当中,大家也应该都了解到,新版分布式 IoTDB 当中,节点主要分为两种角色,第一是 DataNode,第二是 ConfigNode。DataNode 主要存放了数据和元数据的分片,而 ConfigNode 主要存放集群的管理信息,如系统的分区表等。
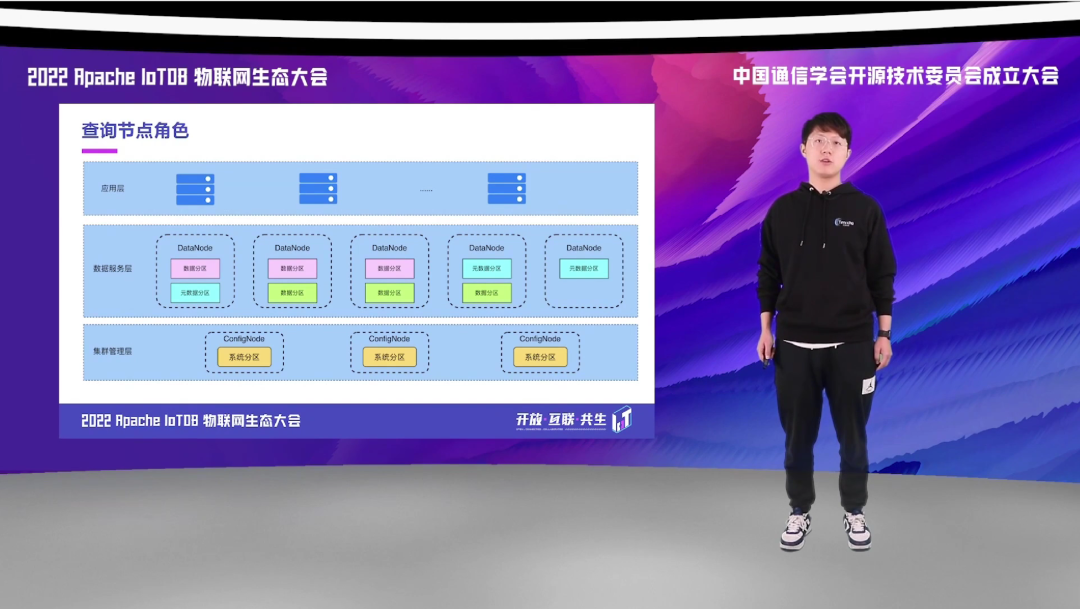
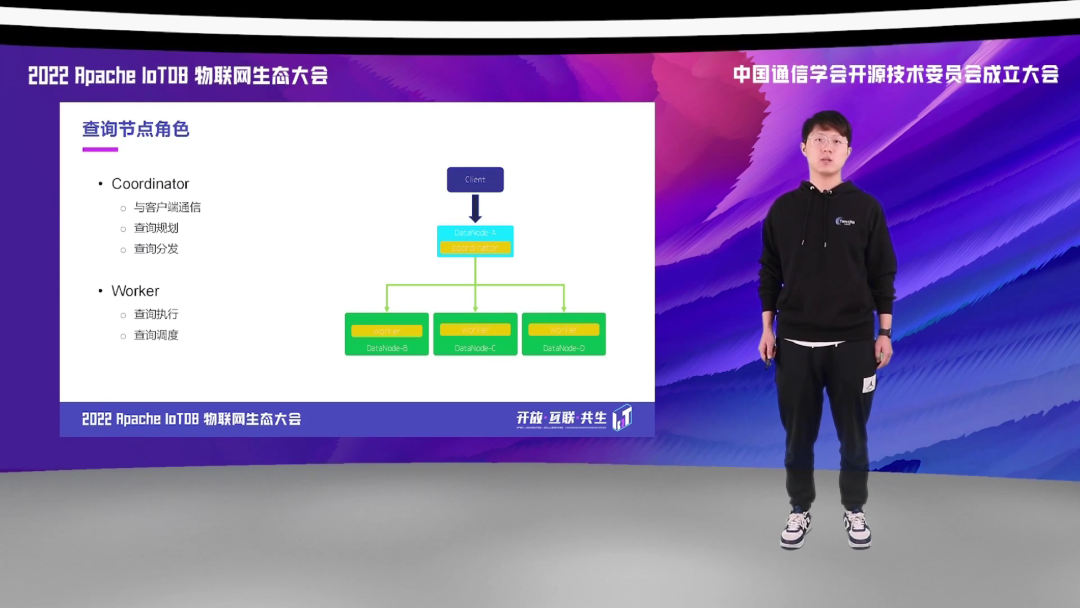
而在于查询整个执行过程中,DataNode 是充当了比较重要的角色,因为查询无论是执行和规划,都是在 DataNode 上面做的。而 DataNode 这个时候又会分为两种,第一种与客户端直连的 DataNode 我们称它为 Coordinator,它主要负责与客户端通信以及查询规划,还有查询的分发工作。而真正负责执行查询的分片的 DataNode 我们称作 Worker,它主要负责查询的执行以及后续的查询的调度。
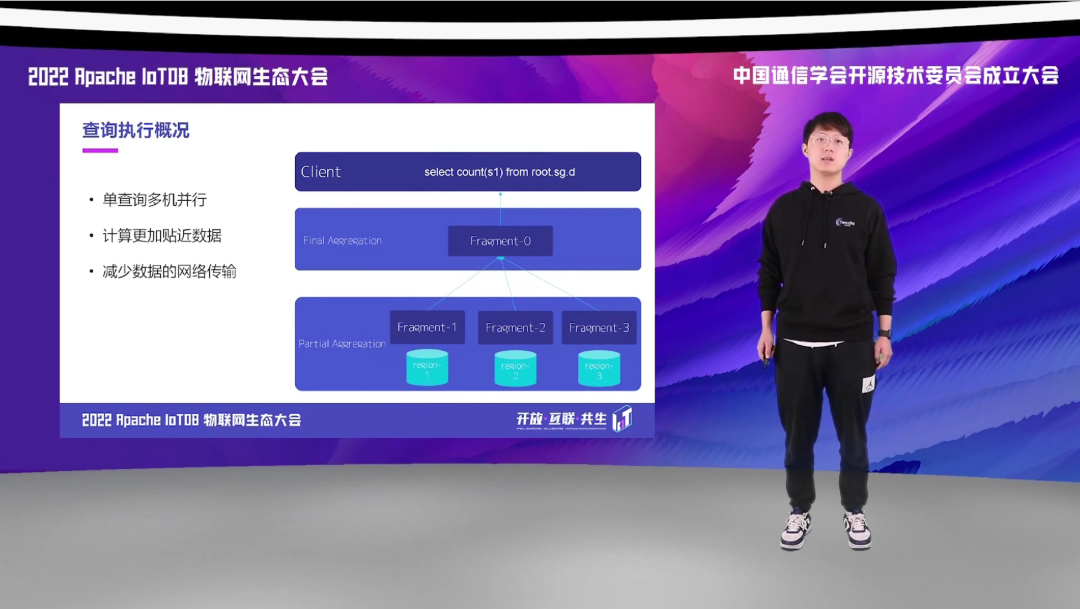
那通过一个简单而又常见的例子,我们可以让大家对 IoTDB 新版的分布式查询有一个直观的感受。一条 SQL 被 Coordinator 接收后,会将该 SQL 转化为多个子分片,这些分片被分发至数据 Region 所在的 DataNode 上面执行。对于聚合查询来讲,这些分片会先预计算出一个聚合结果,最后会由一个 Root 分片负责汇总,对聚合计算进行汇总后,会将该计算结果分发给用户。所以大家可以看到,新版的 IoTDB 分布式架构充分利用了多机并行,以及让计算更加贴近数据,减少数据的网络传输。
02 查询规划
第二个大的部分,我会为大家仔细介绍一下我们查询规划的内容。
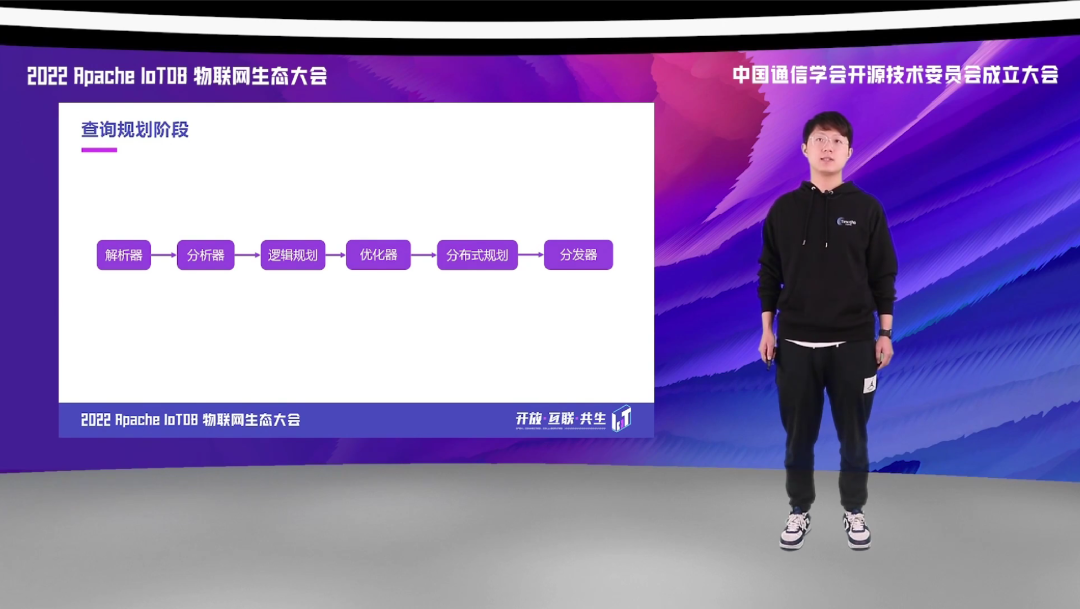
查询规划主要分为六个阶段,首先解析器,经过解析器后再到分析器,然后再生成逻辑计划,最后经过优化器,再经过分布式规划器之后生成分布式执行计划,最后由分发器分发到对应的 Worker 上进行执行。
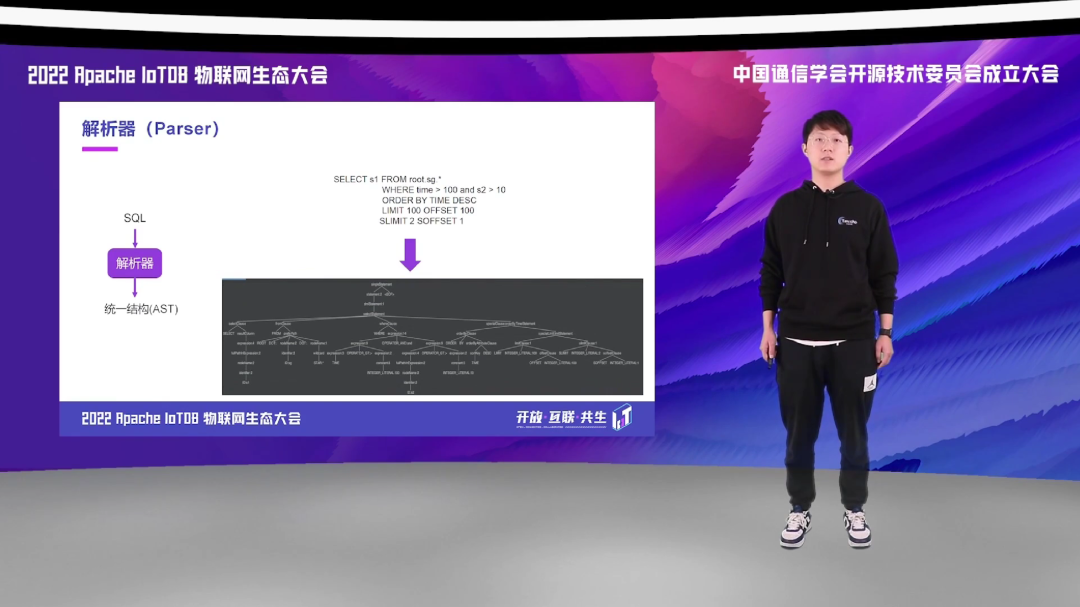
解析器主要的工作是将字符串类型的 SQL 语句解析成树型结构的抽象语法树,也就是我们通常所说的 AST,便于后续的语义解析以及查询计划的生成与优化。IoTDB 的 Parser 利用的是 Antlr,而 Antlr 也是目前主流的一个语法解析框架,有很多大数据的计算引擎如 Spark、Hive、Presto、Trino 等都将其作为自己的语法解析器。
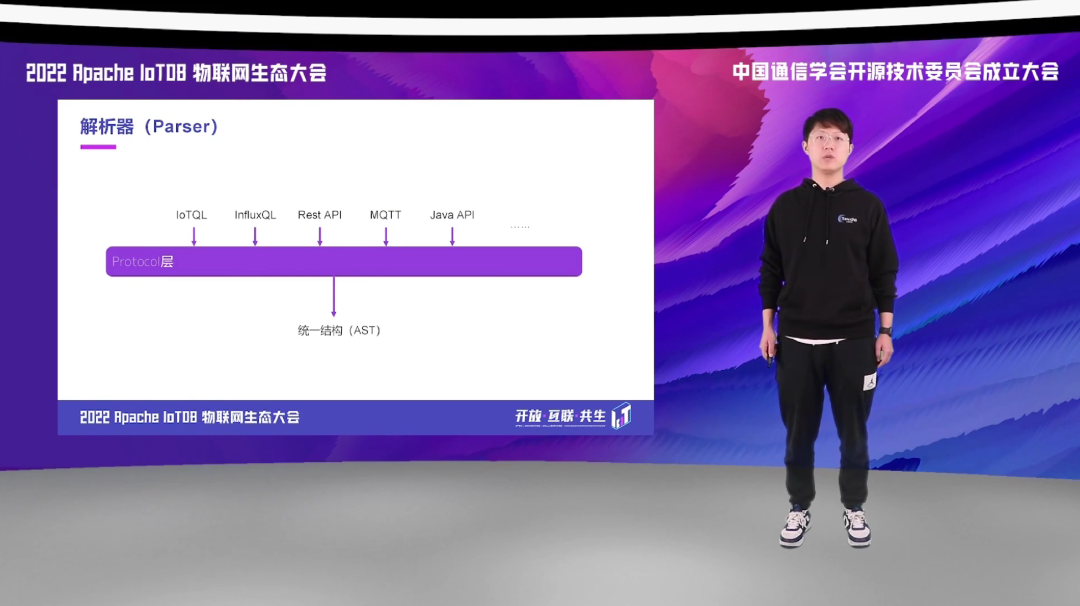
我们将 Parser 抽象出一个统一的协议层,我们支持多种协议的解析,经过相应的 Parser 后,会生成一个统一的、能够被 IoTDB 后续流程所识别的统一结构,也方便用户从其他产品迁移过来。
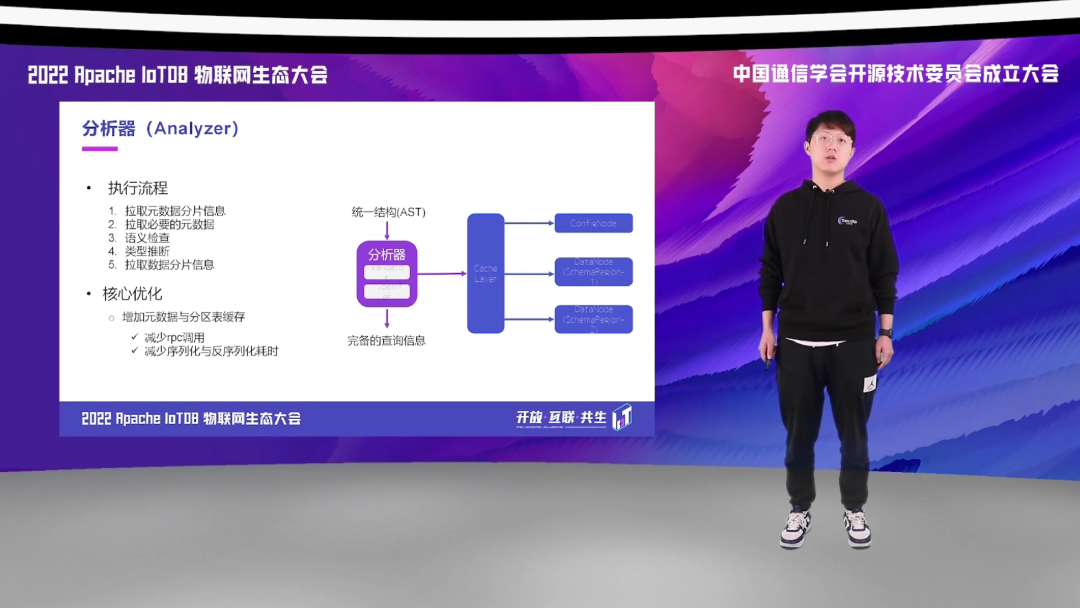
Parser 能够判断出用户的 SQL 中是否存在词法和语法错误,但无法分辨出有没有语义错误,因为这些语义错误或者类型推断,都需要有相应的元数据信息。在分析器阶段,就要负责从 ConfigNode 处拉取对应元数据的分片信息,有了元数据的分片信息后我们就知道需要去哪个 DataNode 上面去拉取对应的元数据。拉取到元数据后再进行相应的语义校验和类型推断的工作。
所以,大家可以看到,在这一阶段过程中可能涉及多次的跨节点或者跨进程的 RPC 通信,这一点对于查询的延迟影响是会很大的,所以在 IoTDB 中我们做了这样一个缓存的优化,我们会缓存数据的分片信息以及元数据信息,减少 RPC 的调用,减少序列化和反序列化的耗时。
经过语义解析后我们得到了一个完备的查询信息,通过这个完备的查询信息,我们再经过逻辑规划生成一个逻辑计划,而逻辑计划是由一棵 PlanNode 组成的树。这个 PlanNode 是一个朴素的执行计划,它只是表意的作用,我们无法通过这个 PlanNode 进行执行。并且,这个 PlanNode 所表现出来的执行方式也并不一定是最优的,比如说图中展示的这一个方式,它的执行方式是会扫全表的,而这个扫全表的操作代价是昂贵的,并且我们也不知道需要发送到哪个 Worker 上实行,缺少了数据的分区信息。
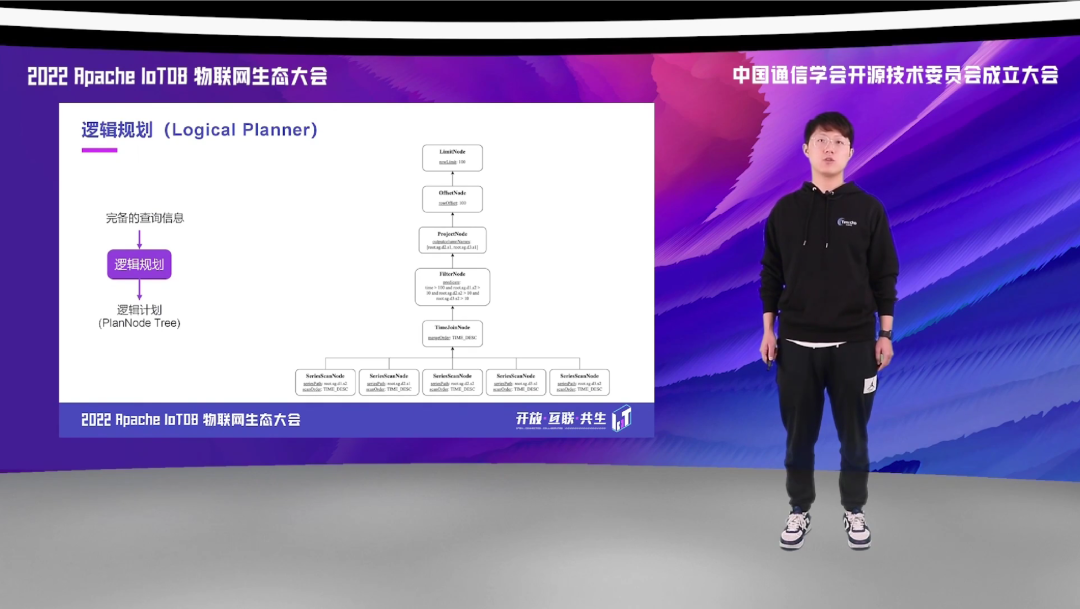
优化器就是对上一阶段生成的朴素的逻辑计划,进行传统关系型数据库的优化工作。那经过优化器之后我们就会得到优化后的逻辑计划,这里面会有很多优化的方式,比如说 rule based 和 cost based。这里我简单介绍两个关于 rule based 的,第一个是,我们可以将 limit 和 offset 下推,这样的话可以节省不必要的数据的网络传输,去节省我们的网络流量。我们还能够将谓词下推,也就是 filter 的 push down工作,利用 IoTDB 存储层的索引信息,我们可以对数据进行提前的过滤,那在很小的选择率的情况下,就能够大幅度节省我们的 IO 以及 CPU 反序列化的耗时。
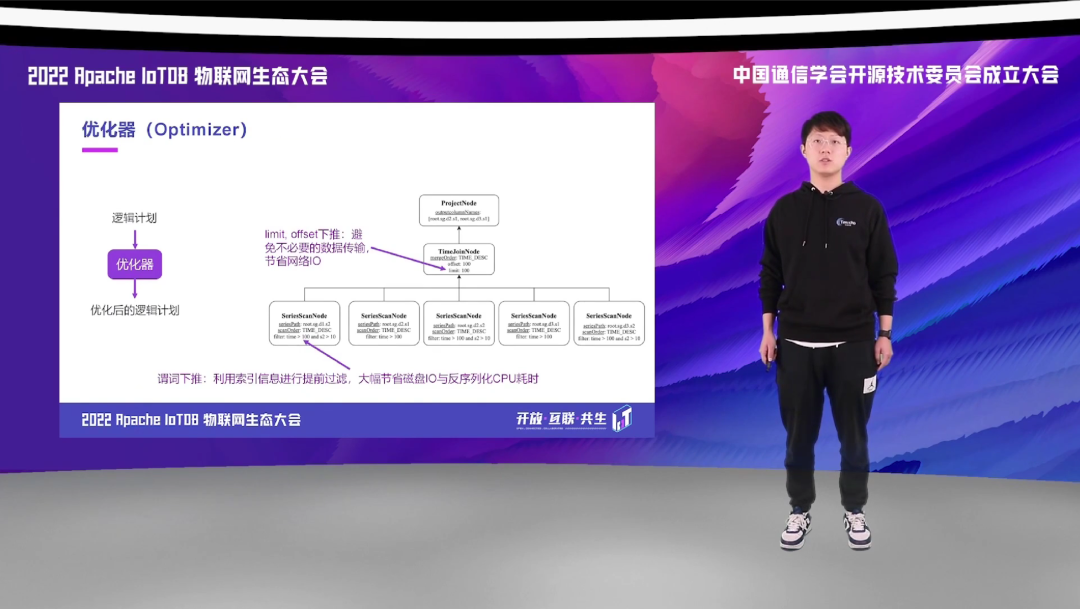
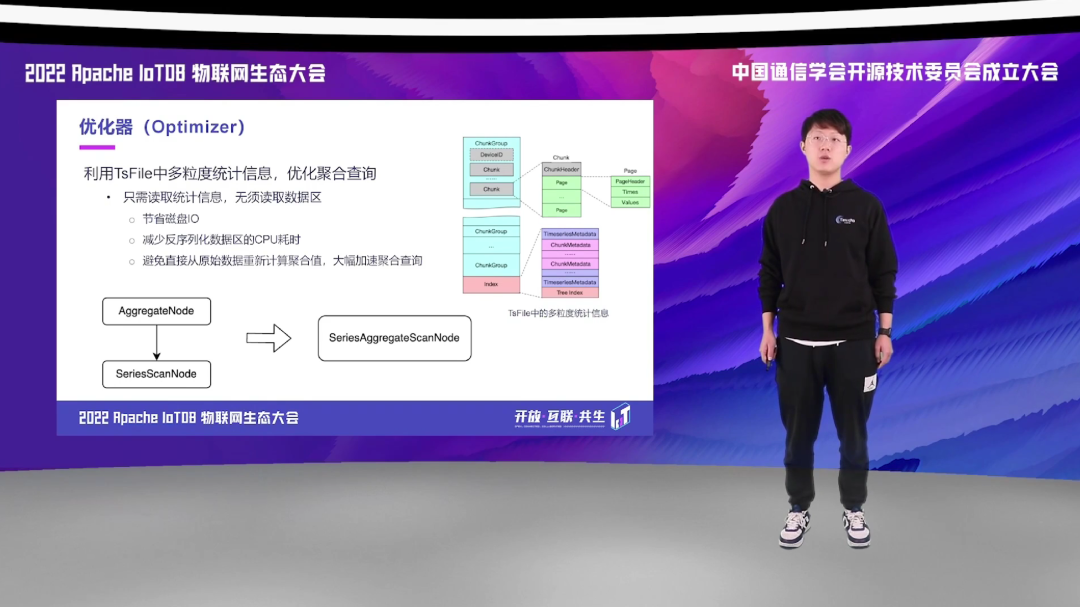
优化器也可以利用 TsFile 中多粒度的统计信息,优化聚合查询。将原先需要读取所有原始数据到内存,再进行聚合计算,优化成将聚合计算下推到 Scan 算子,只需要读取原统计信息,无需读取数据区,大幅节省磁盘 IO,减少了反序列化原始数据的 CPU 耗时,避免直接从原始数据重新计算聚合值,大幅降低聚合查询的延迟。
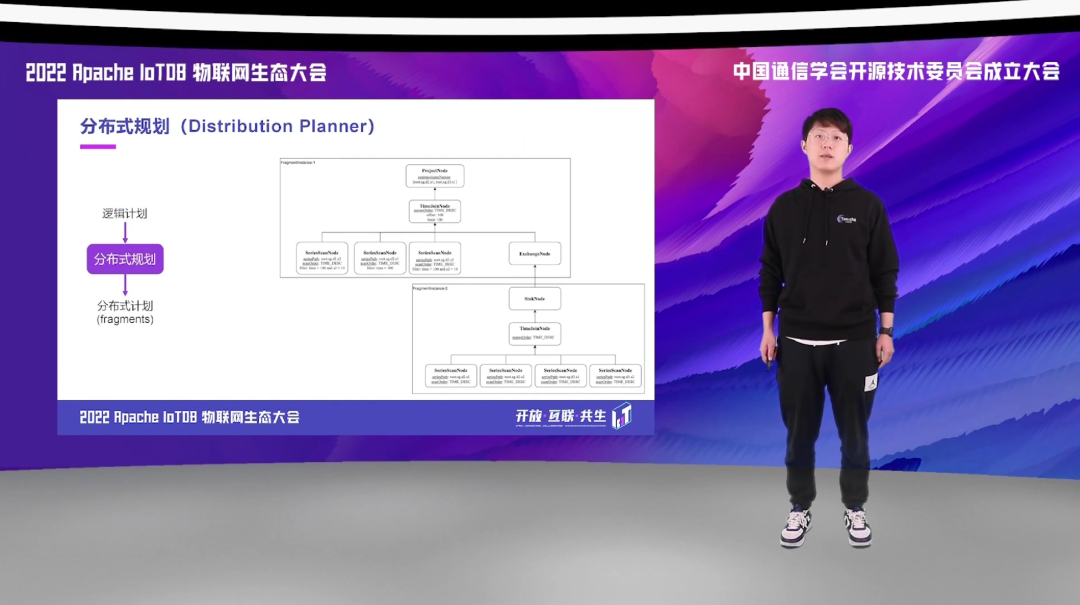
经过优化得到逻辑计划后,Distribution Planner,也就是我们的分布式规划器,会根据数据的分区情况,将逻辑计划切分成不同的部分。
查询框架是具有容错的,整个集群是高可用的,也就是说部分节点宕机或发生网络分区并不会影响正常的查询服务。当然,这里剩余几个副本查询依旧能够对外提供服务,取决于用户所配置的一致性。查询框架内部会做负载均衡,在选择可用副本时也会对节点负载较低的选择执行,而不是选择负载较高的副本执行。
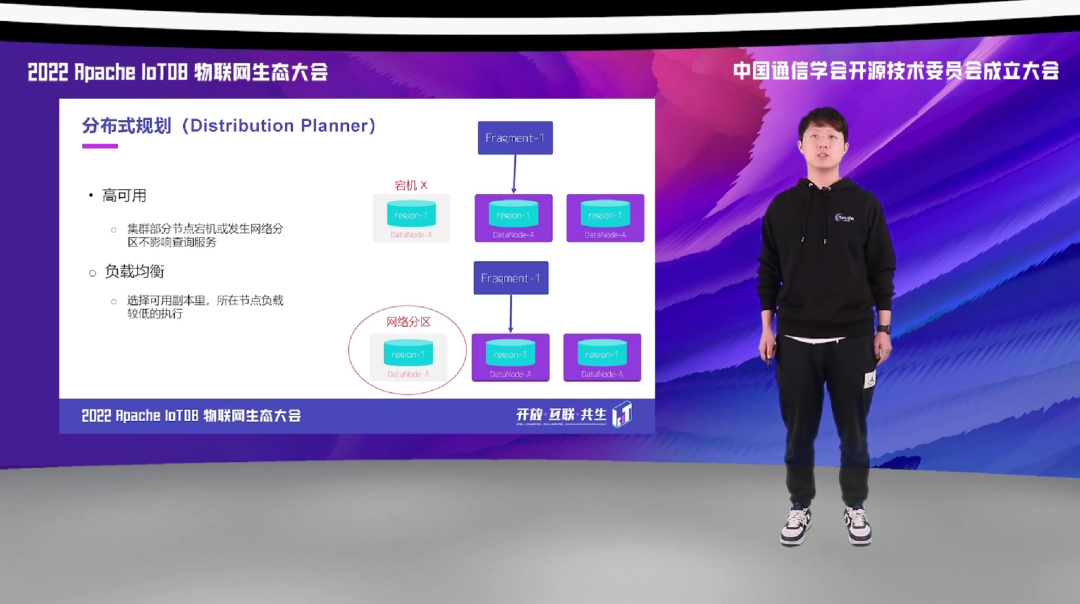
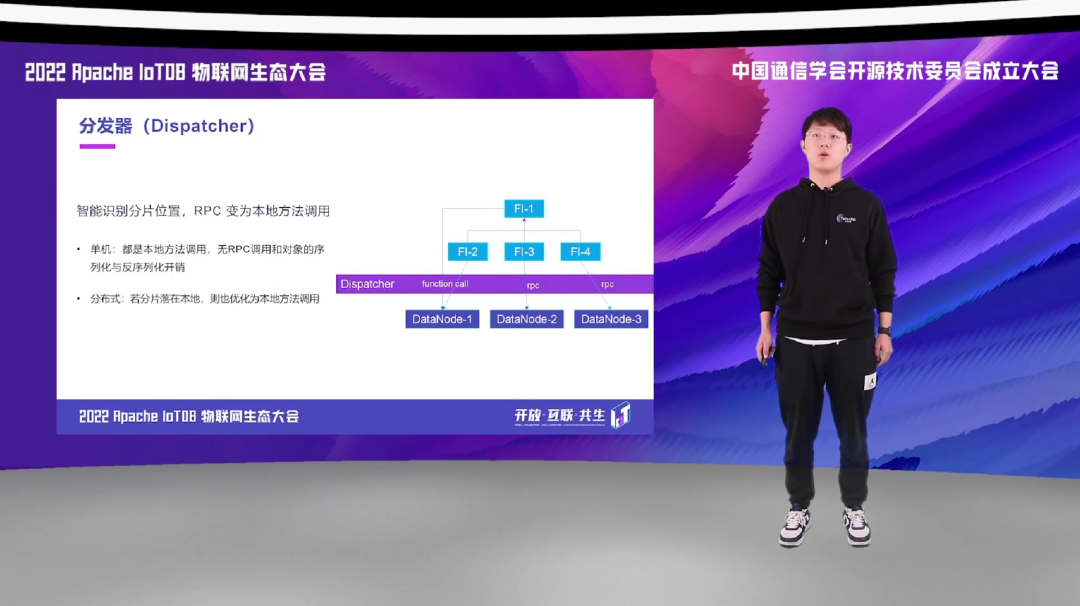
一个逻辑计划被 Distribution Planner 切分成不同的 fragment 后, 会由 Dispatcher 分发到对应的 DataNode。这里的 Dispatcher 会做相应的优化操作,比如说如果目标节点就是当前进程,就可以不用经过 RPC 调用,也不用经过序列化和反序列化,而是直接进程内的一个 function call 就可以了。对于单机就全是本地的方法调用,就无 RPC 调用和对象的反序列化和序列化开销。而对于分布式的,如果分片在本地,就可以直接优化为本地方法的调用。
03 查询执行
接下来是第三章的内容,我会和大家介绍一下我们执行阶段的内容以及优化。
执行层收到的是一个查询的分片,我们需要将表意的 PlanNode Tree 转化为实际可运行的 Operator Tree。IoTDB 的查询执行模型是一个经典的 pull based 的火山模型,当然我们是做了向量化的优化的。这里提到的 Operator 主要的三个执行方法就是 hasNext、next 以及 close 方法。
next 返回一批数据,这里的一批数据是以 TsBlock 的内存形式,它是我们为时序数据场景优化的一个向量化的结构。并且,我们在不同 Operator 之间传输时,是用这样一个 TsBlock 结构进行传输的,能够有效减少 CPU 虚函数调用的开销。我们再返回给客户端时也是分批去返回我们的计算结果,这样能够大量地减少大数据量查询下的内存的压力。

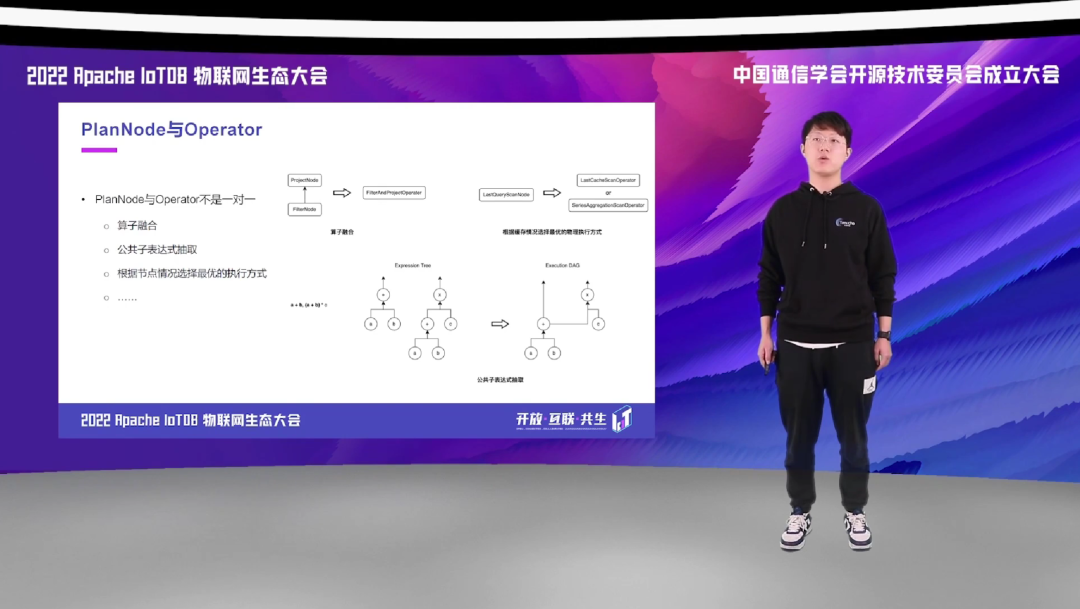
逻辑计划的 PlanNode 到物理执行计划的 Operator 并不是一个简单的一对一的映射关系。这里我们举了三个例子。
一个是我们可能会将多个 PlanNode 生成一个 Operator, 比如说 FilterNode 和 ProjectNode 会映射成 FilterAndProjectOperator。
二是我们可以根据当时执行节点的状态,为同一个 PlanNode 选取不同的物理执行的 Operator。比如说,对于时序查询场景比较常见的最新点查询,如果最新点缓存在内存中,我们是可以直接读取缓存的;而如果最新点缓存不在内存中,我们可以复用聚合查询的算子,从磁盘中读取,并用查询出来的最新点更新我们的缓存。
最后,对于表达式部分,在这一部分,我们也可以做一些公共子表达式的抽取。
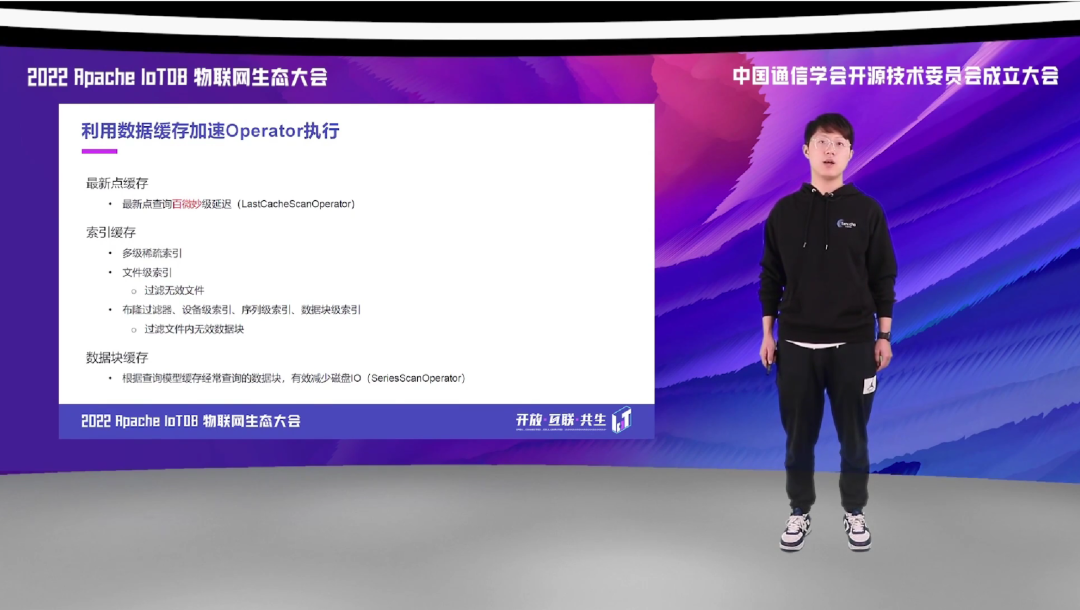
我们都知道,从内存中读取数据,要比从磁盘中读取数据要快很多个数量级,所以 IoTDB 内置了很多数据缓存,用于加速 Operator 的执行,降低查询延迟。如最新点查询,利用缓存,我们可以达到微妙级的查询延迟。还有用来过滤的索引缓存,IoTDB 有很多级的稀疏索引,如文件级别的索引,用来过滤无效的文件。文件内还有我们的索引信息,如布隆过滤器、设备级别的索引,还有序列级别的索引,甚至包括数据块级别的索引,用来过滤文件内无效的数据块。
有了这些数据块,我们再通过结合 filter push down 的工作,可以过滤掉大部分不需要读取的数据块,节省大量的 IO 操作。那在上一阶段,如果真的命中了,也就是说这个数据块真的符合我们的 filter,我们就真的需要去从磁盘中读取,这一步其实也是比较耗时的。所以 IoTDB 不依赖 OS 的这个 buffer cache,自己做了数据块的缓存,那这样即使命中了这个数据块,我们也可以从缓存中读取,而不是从磁盘中去读取,大大减少了我们查询的 latency。
之前在查询规范阶段提到,Distribution Planner 会将整个查询根据数据的分片信息,分发成不同的分片到对应的 Worker 去执行,这里是利用了分布式的多机并行,属于节点间的并行。当对应的数据发放到对应的 Worker 后,我们还会再进一步的对这个查询进行并行化处理, 将 fragment 再切分成多个 pipeline,而一个 pipeline 根据当前 Region 下的文件,再进一步决定是由一个还是多个 Driver 执行。这样就可以进一步的利用单机多核的特点,降低查询延迟,这个属于节点内的并行。
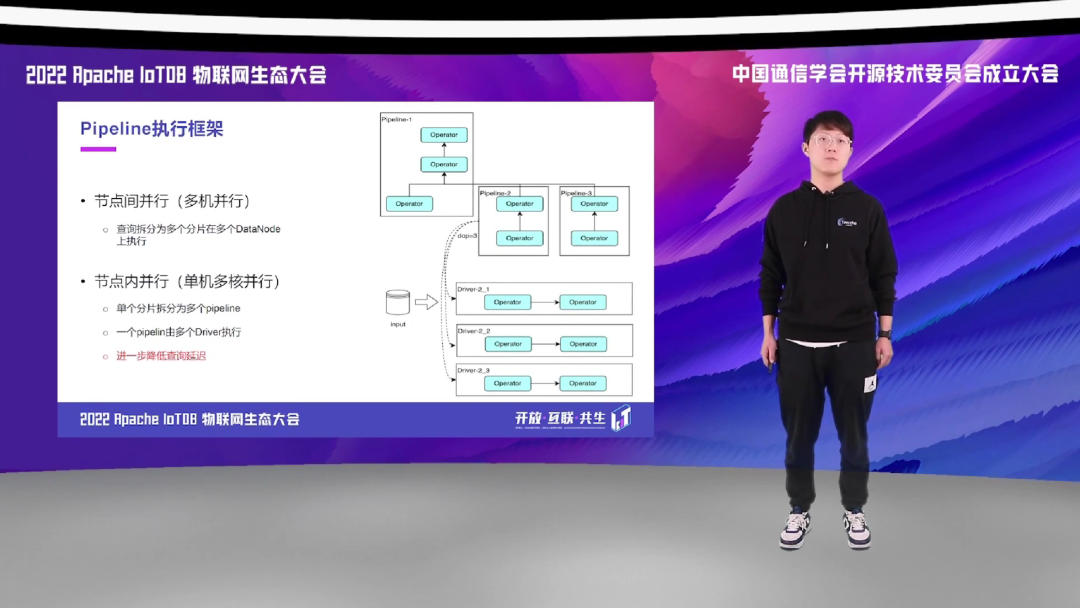
大家都知道,操作系统中,线程是 OS Kernel 的最小调度单元,而我们上一步切分出来的 Driver 就是 IoTDB 查询调度的最小单元、最小粒度。IoTDB 实现了自己的查询调度器 DriverScheduler,能够对查询超时,包括固定查询线程数,以及实现定制化的查询调度,查询内存控制,都能有比较好的、高度定制化的开发以及控制。

IoTDB将调度器抽象出接口,所以可以方便实现多种调度方式,供用户选择最合适的。对于调度器我们有这样几个设计目标。
第一,需要引入优先级调度。因为用户的查询任务分为紧急的情况是不一样的,比如实时的交互式查询往往耗时比较短,但它的优先级会比较高。再比如一些大数据量的长查询,也就是分析类的查询,它需要批量读取历史数据,但是不能让这些 background 的、这些分析类的查询去抢占了我们很多交互式的查询的资源。
第二,我们同时也需要保证优先级的任务不能够饥饿,也就是 background 的这些长查询,需要在一定时间内也能得到执行完成,而不是被源源不断到来的交互式的短查询所抢占了资源。
第三,就是希望调度器的额外开销要尽量最小。

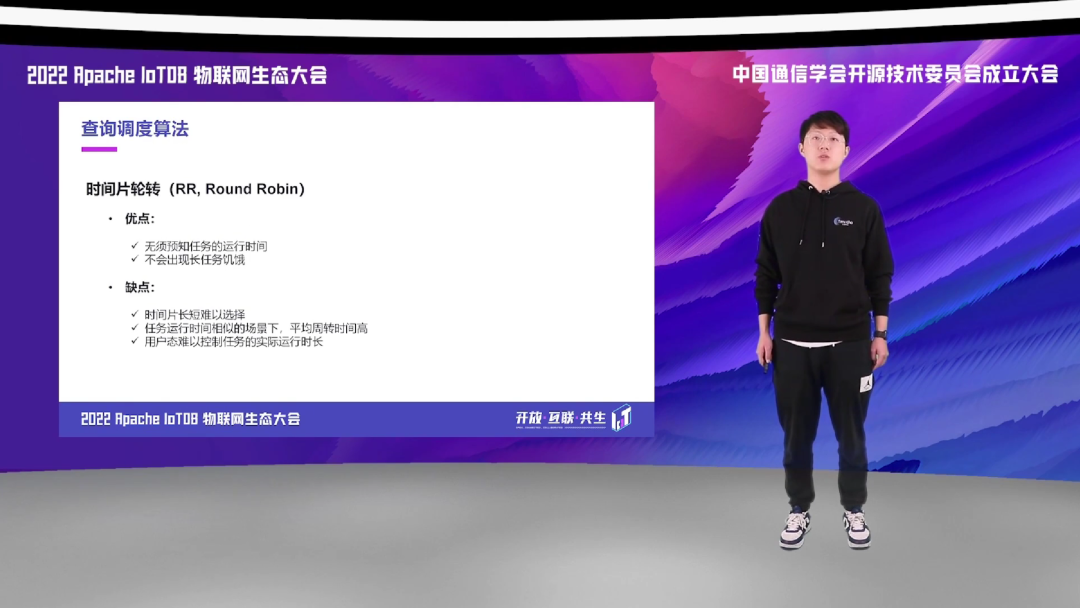
最经典的就是我们的时间片轮转算法。它的优点很明显,它无须预知任务的运行时间,并不会出现长任务的饥饿现象。它的缺点也同样突出,时间片的长短难以选择;并且在用户无法预知实际的运行时长,很容易导致一次运行超过时间片的情况发生;并且任务运行的时间相似场景下,它的平均周转时间也是最长的。
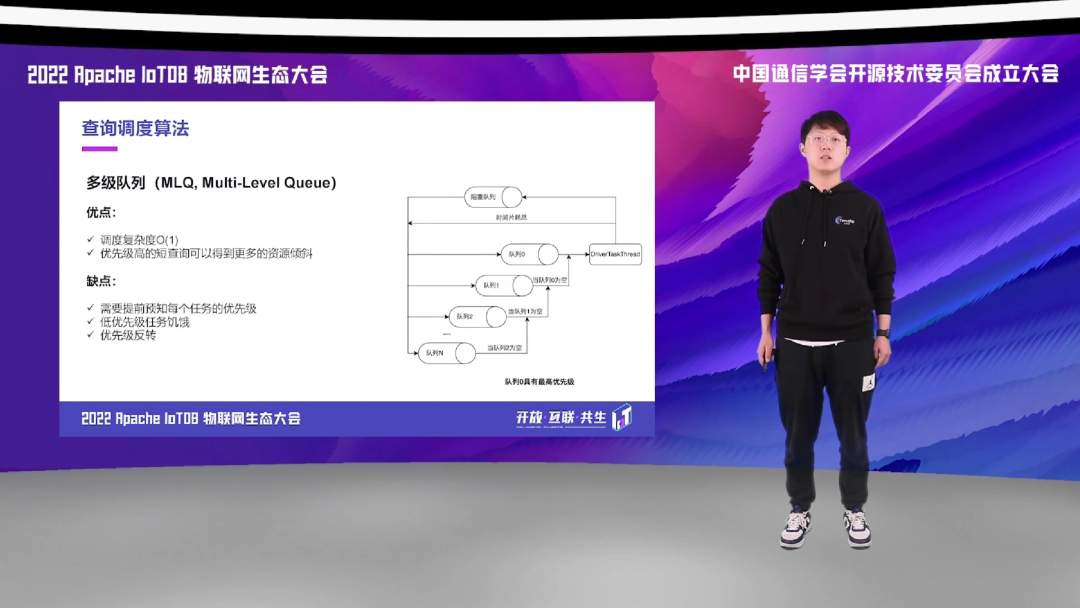
第二种经典的调度算法就是多级队列。每个任务会被分发到预先设计好的优先级,每一个优先级对应一个队列,任务会被存储在对应的优先级队列中,如果优先级不同的任务同时处于同一个优先级队列,那么调度器就会倾向于调度优先级高的任务。因此,一个任务必须等待到所有优先级比它高的任务调度完,才可以被调度。处于同优先级队列的任务,它们内部的调度方式没有统一的标准,可以针对性地为不同队列采用不同的调度方式,比如刚刚提到的时间片轮转算法等。
多级队列比较适合静态的、优先级提前可以预知的一些调度情况,并且它的调度复杂度是 O(1) 的。它的缺点也同样明显,就是在高优先级任务源源不断到达的情况下,低优先级的任务会被饥饿,并且我们需要提前预知它们的优先级。
最后,IoTDB 中实现的动态优先级设置的多级反馈队列的调度算法。当任务进入调度器后,一律被当作短任务,为其设定最高优先级,这有利于短任务能够以较快的时间执行完成。然后,会为每一个计算队列设置任务的最大运行时间,如果任务在当前队列运行的总时间超过了队列设置的最大运行时间,就会认为它是长查询,进而将该任务的优先级减 1。
凭借该方法,那 MLFQ 就可以在无须提前预知任务优先级的情况下,去评估用户的任务的运行时间。为了避免长查询的饥饿,多级返回队列也会定时的将所有任务优先级提升到最高,保证不会有任务饥饿的现象发生。这样我们就能保证刚刚提到的那个目标,也就是大量的历史数据分析并不影响实时的数据查询,并且这些 background 任务也能得到执行、完成。

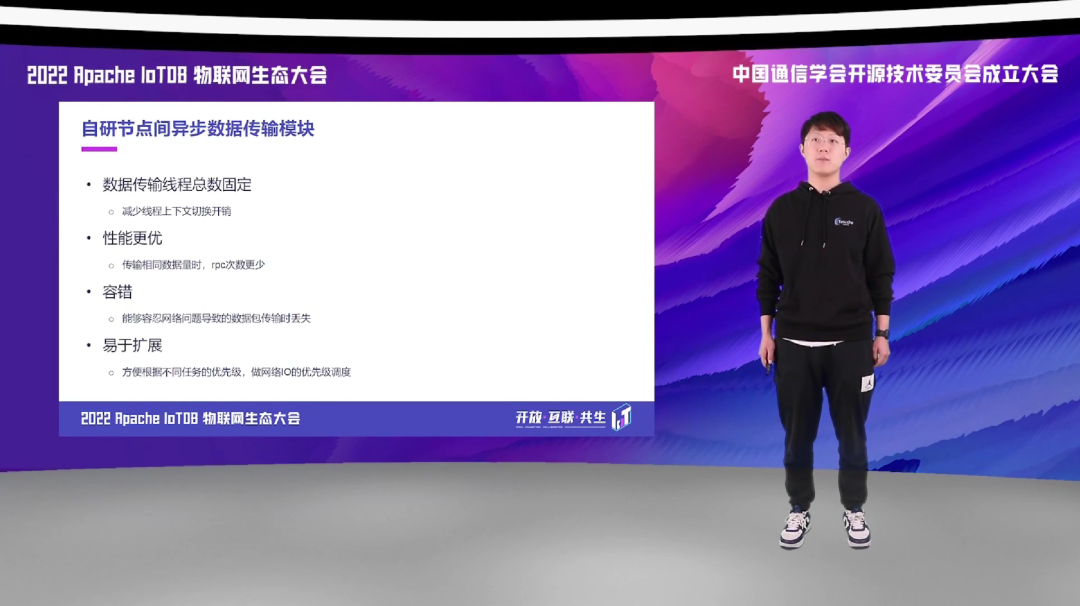
通过之前的介绍,我们了解到,IoTDB 会将一个查询分为不同的分片,分发到不同的数据节点上面执行。那这些数据分片之间需要进行交流,传递数据。我们自研了节点间异步传输的数据框架,我们固定了传输总线程数,避免过多线程导致的上下文切换开销。它拥有卓越的性能,传输数据量相同的同时,它 RPC 次数能控制在最少。能够容忍网络问题导致的数据包的传输丢失,并且它更加易于扩展,方便我们后期根据不同任务优先级,去做网络 IO 的优先级调度。
04 边缘计算的应用
第四个方面,我想跟大家简单介绍一下 IoTDB 在边缘计算当中应用的一些实例。
大家都知道,IoTDB 很轻量化,并且部署形态很灵活,能够支持端边云协同部署,也就是在边缘侧我们也可以部署 IoTDB server,充分利用了边缘算力。那除了可以在边缘侧进行中等规模的数据存储和查询之外,我们具体还可以使用边缘算力做哪些事情呢?
边缘侧的设备对计算时所需的计算能力、存储空间和网络带宽都十分敏感,所以将所有产生的数据不可能都全部进行上云处理,也不能全部存储在本地。同时,由于流式时序数据自身的价值特点,因此触发它的应用场景通常都具有高实时性、多数据流计算、时间窗口计算等需求。
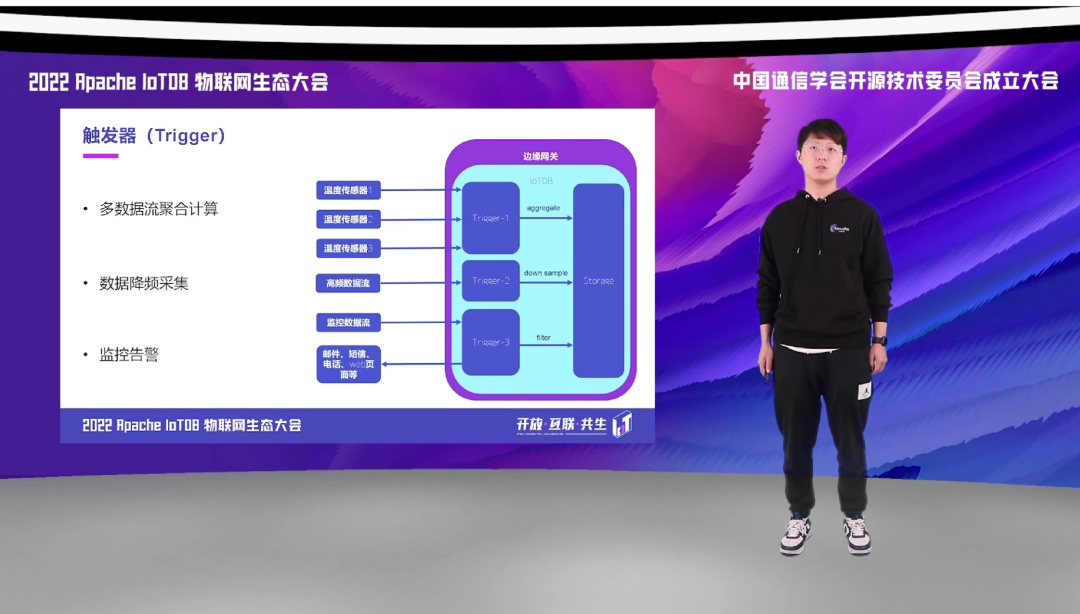
下面是这样一组例子,我们举了三个应用我们的触发器的例子。第一个是多数据流的聚合计算,也就是我们在边缘网关部署一台 IoTDB 后,会有很多温度传感器向边缘网关的 IoTDB 传输它的实时采集的温度。这些温度我们可以通过 Trigger 后,计算出来一个平均值,然后再由 Trigger 定时的去往 IoTDB 去写,这样我们就能做到多采易写的效果。
那对于一些高频采集的传感器,全部将它的数据存储下来的价值是比较低的。我们也可以部署一个 Trigger 去对高频采集的数据进行降频处理,做 downsampling,然后再存储到 IoTDB 中。
第三点就是大家比较常见的监控告警的场景。我们可以对一些监控告警的传感器设置 Trigger,将这些 Trigger 所采集到的值拦截之后,做一些提前的规则处理。如果他不满足这个规则,也就是它是一个需要触发告警的,那这个 Trigger 可能就直接去触发外部的第三方的告警,比如邮件、电话甚至 web 端的页面;对于一些没有触发告警的数据,我们再让它正常通过我们的拦截去进入到 IoTDB 中。
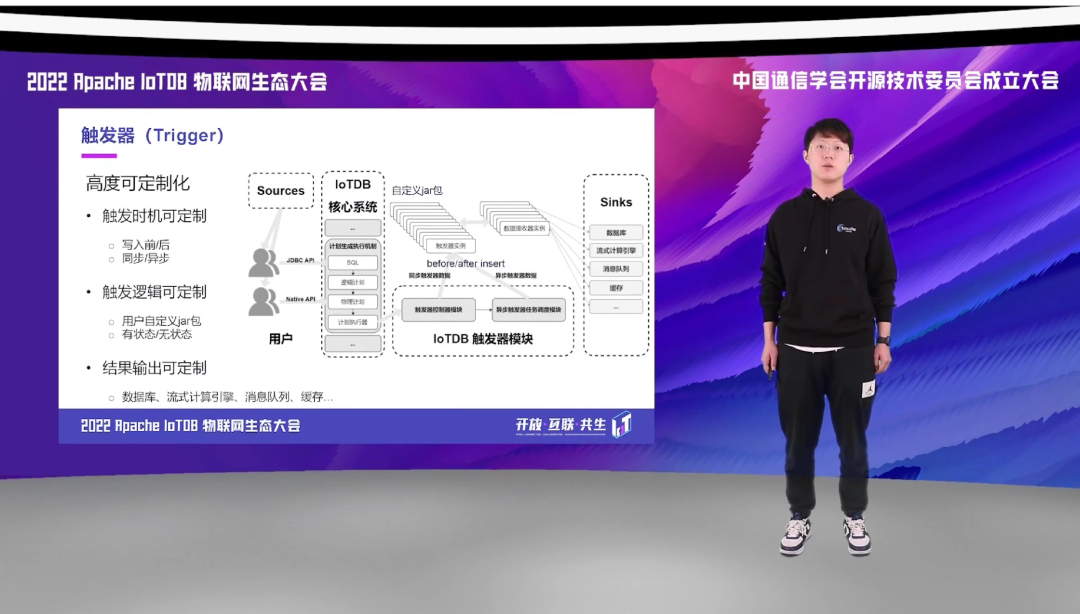
不同于传统关系型中利用 SQL 的方式编写的触发器,IoTDB 的触发器模块是具有高度可定制化能力的。通过加载外部 jar 包的方式,我们允许用户在自定义编写 Trigger 中加入与外部服务或者系统,比如我这边列出来的有存储后端、消息队列、计算引擎等,进行交互的逻辑。
我们还设计了数据的接收器模块,用于将模块得到的数据与常见的服务、系统进行对接。并且,我们的触发时机也是高度可定制化的,现在有写入前触发,也可以在写入后触发;也可以选择同步触发,也可以选择异步触发。这样就可以将可定制化的特点总结为三个:触发时机可定制、触发逻辑可定制,输出结果可定制。
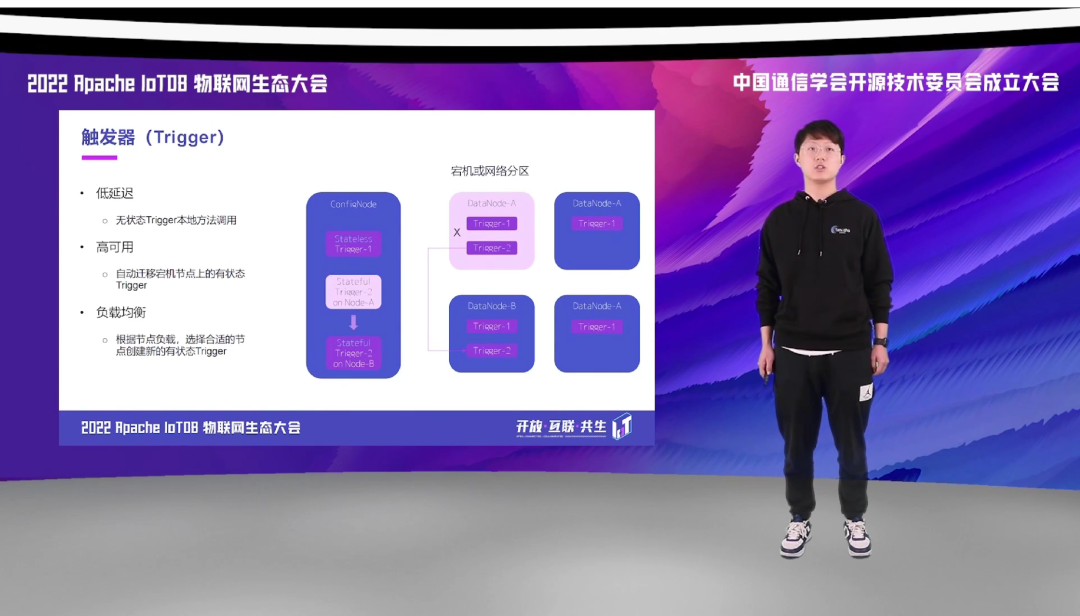
IoTDB 允许用户创建两种类型的 Trigger,一个是有状态的,一个是无状态的。无状态的 Trigger 实例会在每个 DataNode 上面进行创建,保证写入时能本地触发,减少触发器对于写入延迟的影响。而有状态的 Trigger 实例只会创建一个,具体在哪个 DataNode 上创建,由集群的负载均衡器决定。并且,IoTDB 会保证有状态的 Trigger 的高可用性,如有状态 Trigger 实例所在的节点如果宕机,或者发生网络分区无法访问时,会自动将该节点上的 Trigger 实例迁移至其他可用节点。
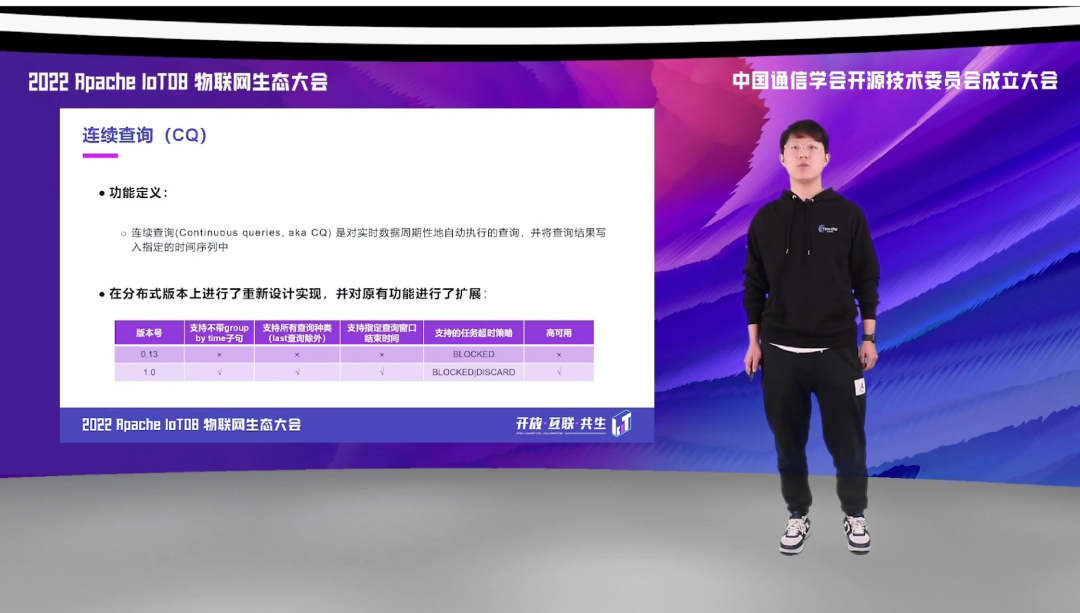
除了利用触发器进行实时告警处理外,我们还可以在边缘侧注册连续查询。连续查询是对实时数据周期性的执行自动的查询,并且将查询结果写入指定的时间序列中。我们在 1.0 的分布式版本上进行了重新的设计和实现,并对原有的功能进行了扩展。原来的 0.13 受很多查询因素的限制,比如说它不支持很多查询功能,比如 align by device、各种时间查询的窗口,而且原来的 0.13 版本是一个单机实现的,无法实现 CQ 的高可用。而在 1.0 版本,我们支持了几乎所有的原生的 IoTDB 能够支持的查询,在 CQ 当中也都能支持,除了 slimit 和 soffset 的子句外。
连续查询在边缘侧有着丰富的应用场景,比如说在进行数据同步时,我们可以根据需求选择的进行同步原始数据,或经过计算后的原始数据;对数据进行降采样,并对降采样后的数据使用不同的保留策略;也可以进行一些预计算,将一些计算代价高昂的查询,通过 CQ 得到计算后先写入另一个预先设定的序列中,之后这些高昂的数据查询我们就可以转化为从已经写入的这些数据序列当中进行查询。
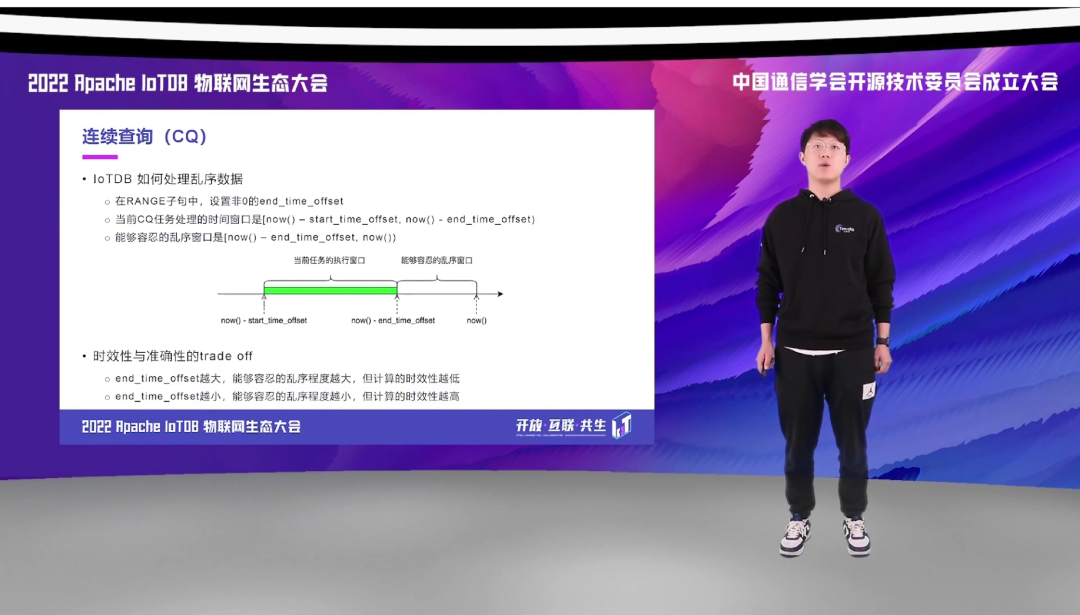
连续查询在 IoTDB 当中有非常丰富的时间窗口的设定参数。目前一类已有的 CQ 的语法,无法对于数据乱序处理的情况无法处理,当前 CQ 任务处理的时间窗口只能是当前时间减去 for_interval 到当前时间,如果在之后到达的数据,就是乱序到达的情况下,这一段时间窗口它是无法处理的。
在 IoTDB 当中,通过新增 end_time 和 start_time,我们可以让用户自由的去配置 CQ 查询执行的时间窗口,也就是,我们可以把能够执行的时间往前推移,空出一段时间窗口,用于我们预估的数据可能乱序到达的情况。

IoTDB 是如何处理乱序数据的呢?在 RANGE 子句当中,我们通过设置 end_time_offset,那当前 CQ 所处理的时间窗口就变成了 now() – start_time_offset,到 now() - end_time_offset。那我们能够容忍的乱序窗口就变成 now() – end_time_offset,到当前时间这一段。那这一段时间如果在这次 CQ 执行完之后再到来是没有关系的,因为它会在下一次CQ执行的时候将它计算进来。
但是这个其实是一个时效性与准确性之间的 trade off:end_time_offset 越大,它能够容忍的乱序程度就越大,但是计算的时效性就会越低;end_time_offset 越小,那它能够容忍的乱序数据程度也就越小,但是同样的,它的计算的实时性就会更高。end_time_offset 为 0 的时候就变成跟已有的 CQ 的语法一样的情况。
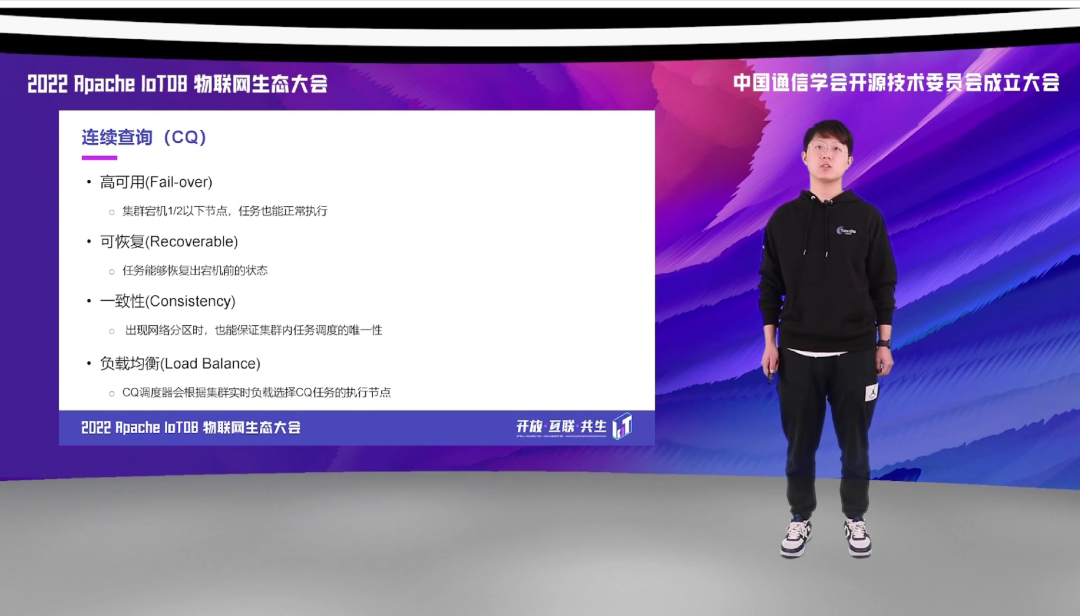
分布式版本的 CQ 有着以下几个特点。第一,它高可用,集群 1/2 以下节点宕机的时候,任务也能够正常执行。第二,是它具有很强的恢复性,也就是任务能够恢复出宕机之前的状态。第三就是一致性,出现网络分区时也能够保证集群内的调度的唯一性,也就是同一个 CQ 只会出现一个调度任务,而不会出现多个调度任务,在发生网络分区的情况下。第四点就是负载均衡性,CQ 调度器会根据各个节点实时的负载,去决定将当前的 CQ 任务调度到哪一个 DataNode 上面去进行执行。
谢谢大家,我今天的演讲内容就是以上的部分。
更多内容推荐:
• 回顾 IoTDB 2022 大会全内容


