

12 月 3 日、4日,2022 Apache IoTDB 物联网生态大会在线上圆满落幕。大会上发布 Apache IoTDB 的分布式 1.0 版本,并分享 Apache IoTDB 实现的数据管理技术与物联网场景实践案例,深入探讨了 Apache IoTDB 与物联网企业如何共建活跃生态,企业如何与开源社区紧密配合,实现共赢。
我们邀请到天谋科技高级开发工程师,Apache IoTDB PMC 侯昊男参加此次大会,并做主题演讲——《Apache IoTDB 首创时序顺乱序分离存储引擎 IoTLSM》。以下为内容全文。
各位关注 IoTDB 的朋友们大家好,我是天谋科技负责存储引擎模块的工程师,也是 Apache IoTDB 的 PMC 成员之一侯昊男。这次大会很高兴有这样一个机会,给大家分享一下 IoTDB 首创的时序顺乱序分离的这样一个存储引擎 IoTLSM。
本次我的分享主要分为这么三个大的内容,第一个是时序数据存储所面对的一些挑战,第二个是 IoTDB 底层的时序数据文件存储结构 TsFile。第三个是 IoTDB 的存储引擎架构 IoTLSM 的一个整体的一个情况。
01 时序数据存储面临的挑战
首先,我想先跟大家一起分析一下时序数据存储所面临的一些挑战。
大家应该都知道,就是我们在工业时序数据的这样一个场景中,大规模的这种时序数据有这样的几个特点:第一个就是占用空间极大,第二个是数据的吞吐量非常大,第三个是产生的速度快而且不间断。
举个例子,比如说是我们风电厂的这样一个场景。一个风电厂有超过两万个风机,然后每个风机有 120 个到 500 多个这样的传感器,每个传感器的采样频率从 0.00167 赫兹到 50 赫兹不等,这跟传感器的种类有关。这样一个风机它每年运行 7500 个小时,就会产生 6 TB 这样一个数量级的数据。
从这样一个场景中,我们就可以分析出来一些时序数据存储的一些需求。比如说全时全量,需要保证这样一个大的数量级的数据,全时全量的存储进数据库当中。第二个是要支持高效写入,保证数据库能够承受这样的一个高吞吐量的一个写入。第三个就是要满足紧凑压缩的这样一个需求,就是对这样的大规模的、大量级的数据进行一些有效压缩,减少磁盘空间的占用。

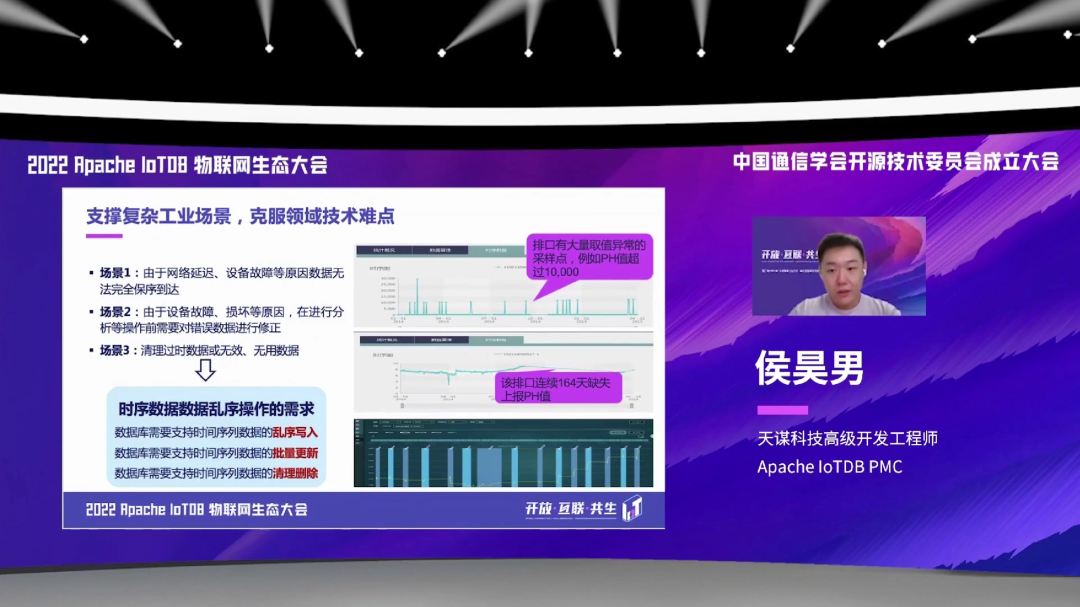
还有一个场景就是,比如说我们在排污口做一些 pH 值的检测,比如说由于网络延迟、设备故障这样的种种原因,这样我们采集出来的数据不能够保证完全保序到达。
还有可能在一些场景中,我们设备可能会有一些故障,像这个图上举的这个例子,有可能会突然跳出来一个 pH 值超过 1 万的数据点。对于这种场景,我们就需要在分析前把这些错误的数据进行一些修正。
还有第三个场景,比如说有一些过期、过时的数据,我们需要定时去清理一下。
从这个场景中,我们也可以总结出来一些对于时序数据乱序操作的一些需求。比如说要支持时间序列数据的乱序的写入,支持批量的进行更新修正的这样一个过程,也需要支持对于一些过期数据的定期的清理、删除这样的操作。
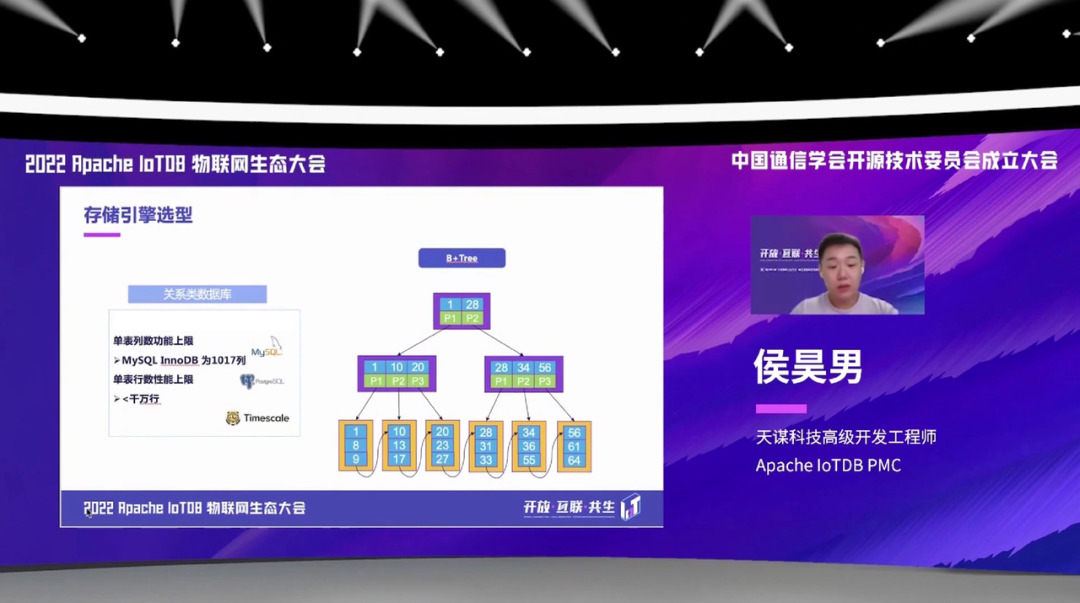
分析完上面的这些需求,然后我们就可以来讨论一下,如果需要满足这些需求,我们的一些可能的一些解决方案。可能大家首先就是会想到一些传统的数据库,如关系型数据库。它的底层存储就是我们可能都是比较熟悉的 B+ 树。但是用关系型数据库去存储这样的一个大规模的时序数据的话,有这样几个问题:第一就是模型的一种扩展性会比较差,吞吐会比较低,有单表列数的功能上限,还有就是对于这种单表的这种行数也有一些限制。
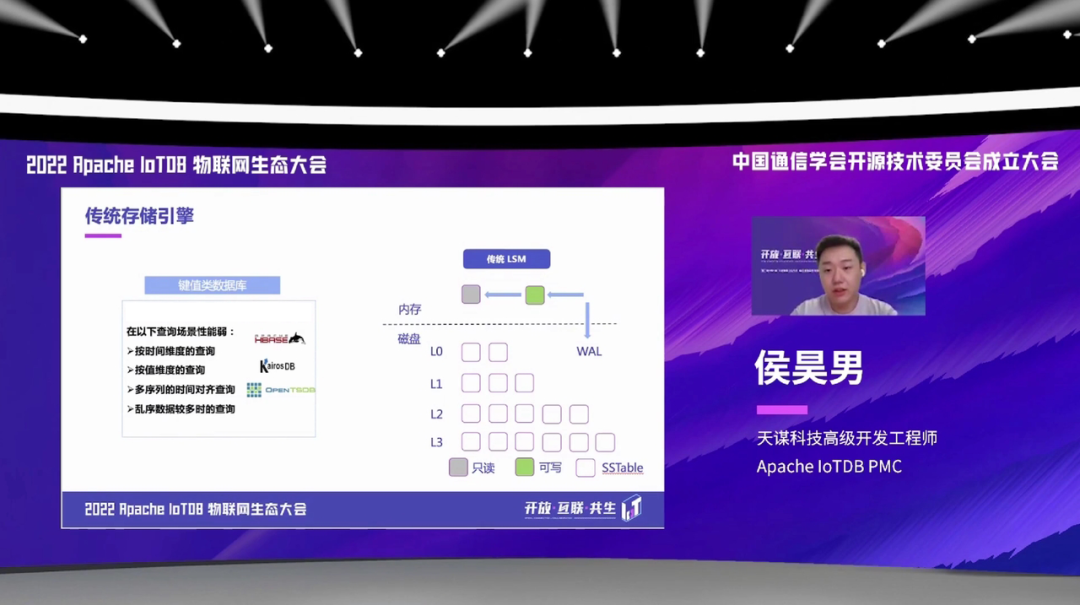
除了这个传统的关系型数据库,还有就是后面出现的一些键值型、KV 型的数据库。它的底层一般是采用这样的一个传统 LSM 的一个结构。但是用这样的一个存储模型的话,也会有一些在查询方面的限制。比如说在时间维度的查询,在按值维度的一些查询、还有多时间序列的对齐的一些查询,还有乱序数据较多时候的查询,对这种查询不是特别的友好。相对应,它们的一个压缩比也比较低,运维方式也是相较于更新型的数据库,会更复杂一些。
针对于上面的这些场景,然后 IoTDB 就是会走了一条自己首创的、自己发展的一个道路。就是从 2011 年开始,我们清华的团队成员在一些企业方面,有一些具体的实践方案,就发现了这样一个海量序列、动态扩列、乱序处理的这样一个问题。到 2016 年,我们清华的团队就研制了这样一个时序数据列式存储的文件的一个形态,就是 TsFile。
然后到 2018 年的时候,IoTDB 就成为了 Apache 的一个项目,就是开始了全面的拥抱开源社区的一个发展过程。到 2019 年,我们首创了顺乱序分离的这个 IoTLSM 存储引擎的这个架构,解决了乱序的处理问题,然后当时是发布了 0.9.0 版本,并且在上海地铁上线了。
2020 年的时候,我们这个文件合并的模块就逐渐成熟,然后发布了 0.10 版本,在一些电厂的一些公司进行了一些上线,也成为了 Apache 的一个顶级项目。在 2021 年的时候,我们参加了“十三五”的科技成就展,然后我们 IoTLSM 存储引擎也全面进军了我们 1.0 版本的这样一个原生分布式的形态。

02 时序数据文件结构 TsFile
接下来我想跟大家介绍一下 IoTDB 自研的磁盘文件的存储格式 TsFile。
相比于国际上最有名的时序数据的存储系统,我们 TsFile 的这个磁盘空间占用是降低了 85%。看到的这张图,其实是 TsFile 当前版本的整体的一个架构,分为前半部分的数据存储部分和后面的一些文件的索引部分。

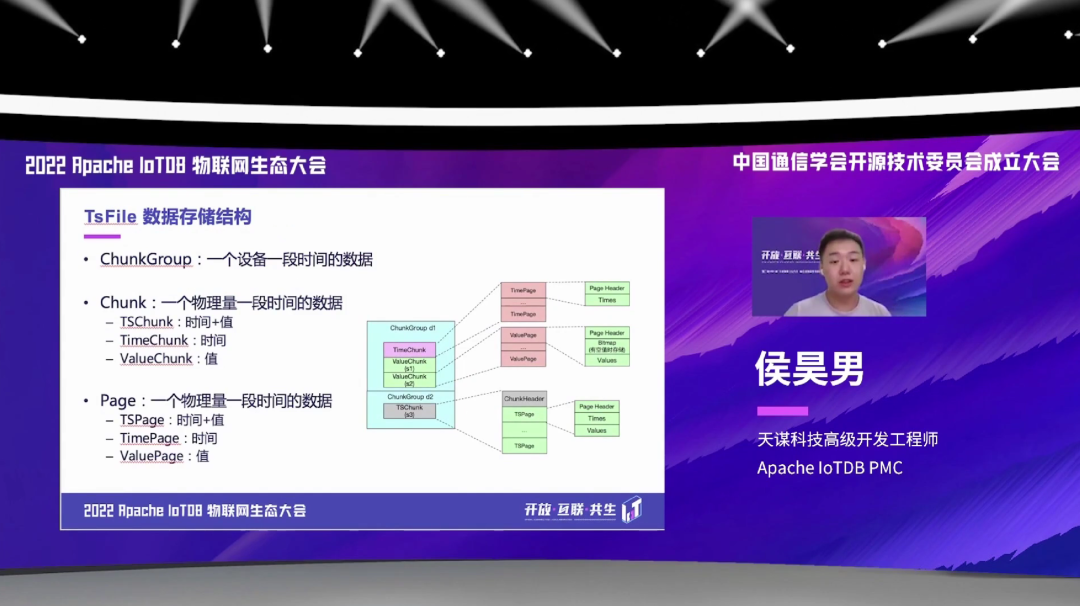
TsFile 的文件存储结构也是一个多级的结构。首先是一个叫 ChunkGroup 的结构,它存储是一个设备一段时间内的数据。
在每个 ChunkGroup 内部有一个叫 Chunk 的结构,它是存一个物理量一段时间的数据。在每个 Chunk 里面,都是会分一些具体的分类,比如说有 TSChunk 和 TimeChunk、ValueChunk。TSChunk 是针对于非对齐序列的一个 Chunk 的结构,然后 TimeChunk 和 ValueChunk 是针对于对齐序列的这样一个 Chunk 的结构。
然后在每个 Chunk 里面,还有一个叫 Page 的结构,它也是一个物理量一段时间的一个数据。也是分为 TSPage、TimePage、ValuePage 这样的几个分类。
除了数据部分,然后 TsFile 还有序列内的这样一个索引结构。我们 TsFile 支持的索引也是分为多个等级的,包括 Page 级、Chunk 级和文件级。每一个 Page 有一些统计信息,每个 Chunk 会有这个 Chunk 级别的统计信息,每个 TsFile 文件会有一个文件级别的一个统计。它的这样一个统计索引信息,作用就是为了过滤数据块,减少 IO 和物化。然后也支持快速的一些聚合查询,可以在做这种聚合查询的时候,可以从一个索引里面直接反馈结果,就不用去扫原始数据了。
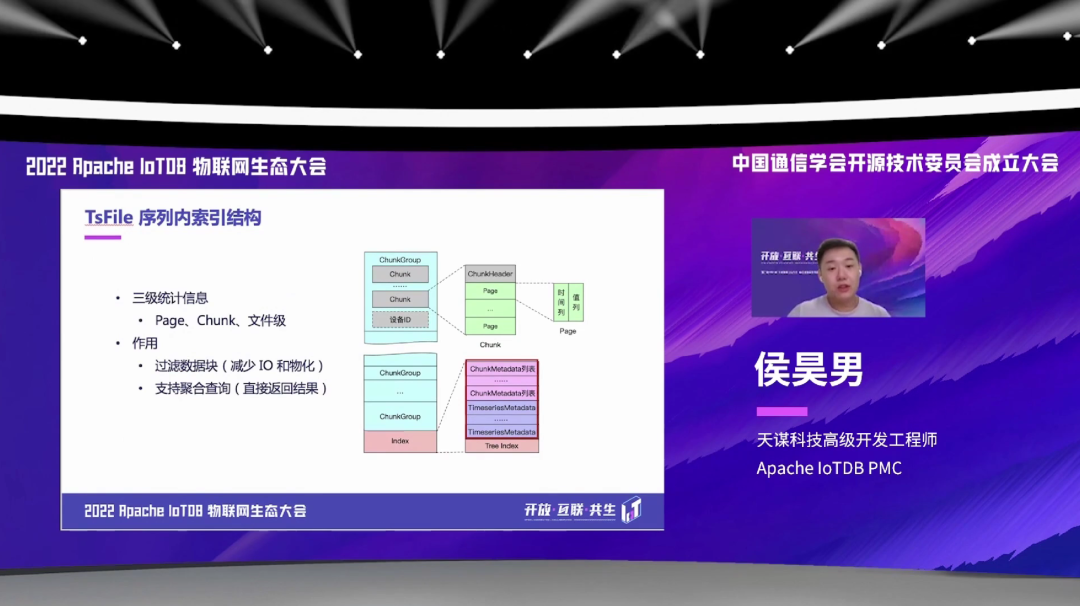
除了序列内的索引,TsFile 还有序列间的一个索引,就是在文件尾部有一个元数据的索引树。它的作用是,当我们一个 TsFile 里面的序列数非常多的时候,那么就需要一个高效的索引结构,能够去快速去找、去定位一个序列的数据在文件的一个具体的一个位置。那么也是分了多个等级,比如先开始是设备级,先找到具体的设备,然后去索要查询的一个具体的一个测点;然后根据测点层的索引,再去找刚才说的序列内的这样一个索引;根据序列内的这样一个索引,然后我们就可以找到具体的原始数据所存储的一个位置。
关于数据压缩 TsFile 也支持对于各种数据类型,不同的压缩和编码方式。现在 TsFile 支持的基本类型有这么六种:BOOLEAN、INT32、INT64、FLOAT、DOUBLE 和 TEXT 类型。然后针对于不同的类型,我们也是支持了不同的这样一个编码方式,包括有损和无损编码。这个表上标红的是我们默认的一个编码方式,就是说如果去创建这样一个序列,如果不指定特定的编码方式的话,就是按红色的这个编码方式去进行一个编码。
然后压缩我们也是每一种数据类型都支持四种不同的压缩方式,包括不压缩 UNCOMPRESSED、还有 SNAPPY、LZ4 和 GZIP。

除了基本的编码和压缩方式之外,IoTDB 还支持这样一个 SDT 死区处理的算法。可以从这个图上看,原始数据可能会有 11 行的这样一个数据,然后经过 SDT 的死区处理算法之后,我们就可能只存这样五条数据。总体来说就是 IoTDB 可以支持这样一个三级的压缩,具体流程就是首先先是进行这样一个死区处理,如果设置了死区处理,会进行这样一个死区处理,就直接去把有些不重要的点丢掉。然后去做这样一个,刚才提到的,有损或者无损的编码,然后再进行一个压缩,压缩都是无损的。

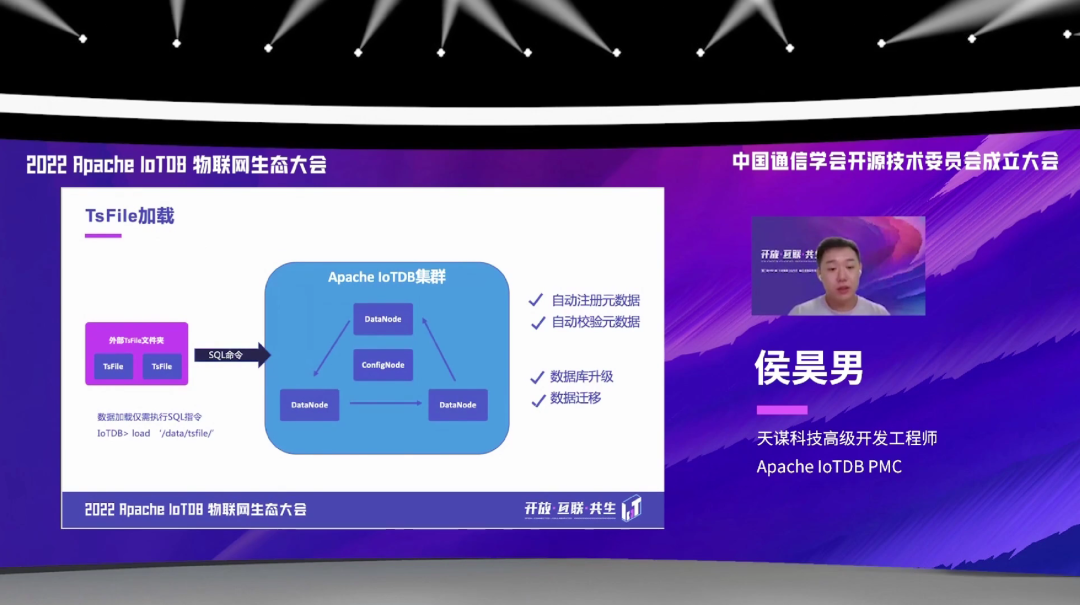
IoTDB 还支持一个重要的特性,就是可以把一个外部的 TsFile,或者一个文件夹里面包含很多 TsFile,通过一个 SQL 命令去加载到一个 IoTDB 里面。执行也很简单,就是执行一个 load 的这样一个 SQL 的命令就行。这个 load 加载的过程中也是支持,我们之前一直提到的自动注册元数据,会自动校验元数据。在我们推荐使用这个功能,一般是在数据库的升级或者数据迁移的这样一个场景下,去使用这个 TsFile 加载功能。
03 IoTLSM 存储引擎架构
介绍完这个文件格式,我想给大家再介绍一下 IoTDB 的独有的这样一个存储引擎的架构 IoTLSM。
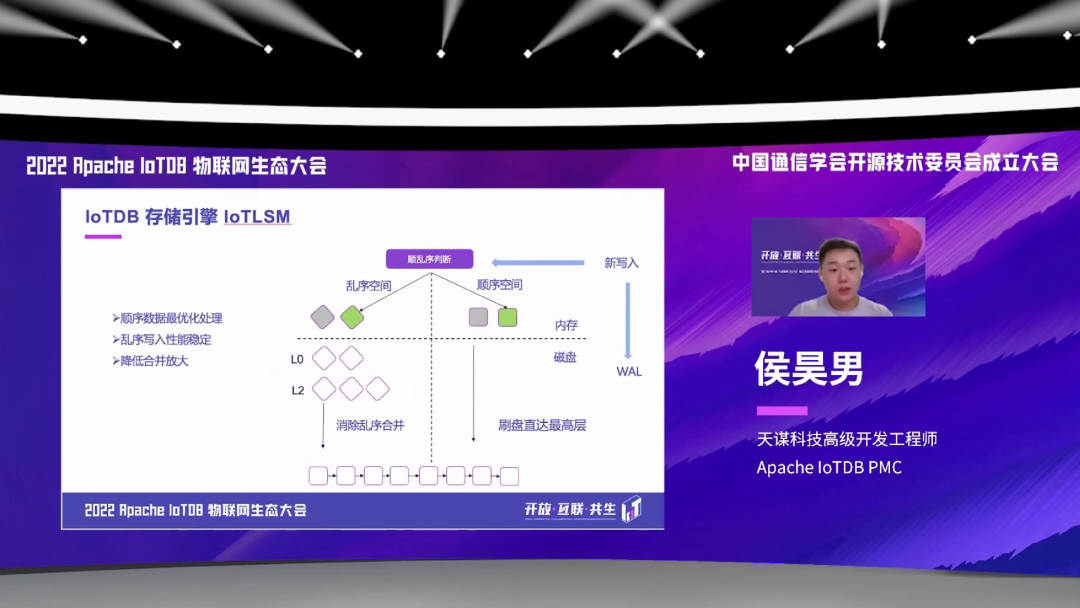
这个图就是我们这个存储引擎整体的一个情况。每当来一个新的写入的时候,首先先记在这个 WAL 里面,我们会有一个独有的顺乱序判断的一个机制,去把这个数据分到顺序空间,或者是去分到乱序空间里面。然后如果是分到顺序空间里面,并且触发了这个刷盘,它会直接刷到这个文件的最高层。如果是乱序空间的话,它会首先进行一些空间类的合并,然后再通过乱序合并、跨空间合并去消除这样一个乱序文件。
我们这个 IoTLSM 的特点,首先是对于顺序数据有这样一个最优化的处理,就是直接刷盘到了最高层。然后乱序写入的这个性能会是非常稳定的。对于合并放大的问题,我们也有降低的一些策略。
具体的一个顺乱序分离存储的过程是这样的。首先就是,我们先将内存写入一定量级的数据,然后它会触发一些 flush 的操作,就是持久化到磁盘中写成 TsFile。
以这个例子为例,假如说我们就写了这样一个 time = 1,value = 1、time = 3,value = 3 这样两条数据,然后触发了一个刷盘,我们就会把这样一个 TsFile 刷到磁盘中,同时删除掉刚才这个记录的写前日志。同时,我们在内存里面,会留这样一个 tsfile.resource 的索引信息,里面记录了这个 device 的 start_time 和 end_time,就是起始时间和终止时间。

在这个之后,如果我们再写入这样两条数据,比如说 time = 2 和 time = 4 的这样两条数据。time = 2 的话,因为是在之前写的那个 resource 里面,会记录已经超过了end_time,所以它会判断为这是一条乱序数据。然后如果是 time = 4,会发现它已经不在这个范围之内,它会去作为一条顺序数据,去写在顺序空间里面。可以看到右边这个图,就是看到 4 的数据是写到顺序文件里面, 2 的数据会写在乱序数据里面。

我们 IoTDB 的存储引擎还有一个独特的地方, 是我们使用了基础类型的一个数组,来作为这样一个内存存储的一个单元。对于这些数组,我们有一个结构就是 Array Pool,来去管理这些内存存储单元,去做了一个池化的这样一个操作。每次写入的时候先向 Array Pool 去申请对应类型的一个数组,就包括这些 INT、LONG、FLOAT、DOUBLE 等数组。每次刷完盘之后,再将 Array Pool 去归还使用后的数组。
这个 Array Pool 的作用,大家可能能看出来,就是为了减少内存对象的一个不停的创建,来减少 GC。我们这个 Array Pool 是可以根据写入数据的具体类型,去动态调整这个 Array Pool 里面各种数据类型的数组的比例。比如我写入的时候只写入 INT 和 FLOAT 类型的数组,它可能刚开始初始化的时候,Pool 里面每个数组都会有一些比例,但是在写入一段时间之后,发现只有 INT 和 FLOAT 类型的数组会使用比较多,这个 Pool 里面的比例会慢慢的去转向 INT 和 FLOAT 数组更多一些,会有这样一个优化、自动调整的机制。

然后,我们存储引擎是支持这样一个空间内的一个合并,就比如说有这样三个小文件,然后把它合并成一个大的文件。这样的一个空间内的合并主要的目的是这样三点。
第一个是减少查询的 IO,当内存比较受限制的时候,刷出来的数据会比较小。因为我们刷盘具体的一个文件大小,可能是由当时这个机器的具体内存大小来决定的,如果机器内存比较小的话,它刷出来的文件也会比较小。当如果这个文件比较小的时候,它查询的 IO 次数就会非常的多,然后通过这样一个空间内的合并,可以减少这样的查询 IO。
第二点就是可以提升索引的一个速度,因为就是刚才介绍 TsFile 的时候,有说 TsFile 文件尾部有一些索引。如果把各种小文件合并成大文件之后,这样的索引的效率可能会极大的提高。
第三就是可以通过这样的空间内合并,去优化整个的文件系统,减少文件的个数,降低文件系统的一个负载。

接下来是跨空间合并,就是把乱序空间的数据去往顺序空间去合并。这个图也是表示了这个意思,比如说第一个文件是顺序数据,第二个是个乱序的文件,合并之后就是统一合并成一个顺序空间的一个文件。通过这样的跨空间合并,可以提升乱序数据的查询效率。假如说,我们要去查一个大的时间范围的所有数据,如果里面有顺序加乱序的话,需要去做这样的一个归并排序。如果去消除这样一个乱序文件的话,只有顺序数据就会提升我们的这个查询性能。

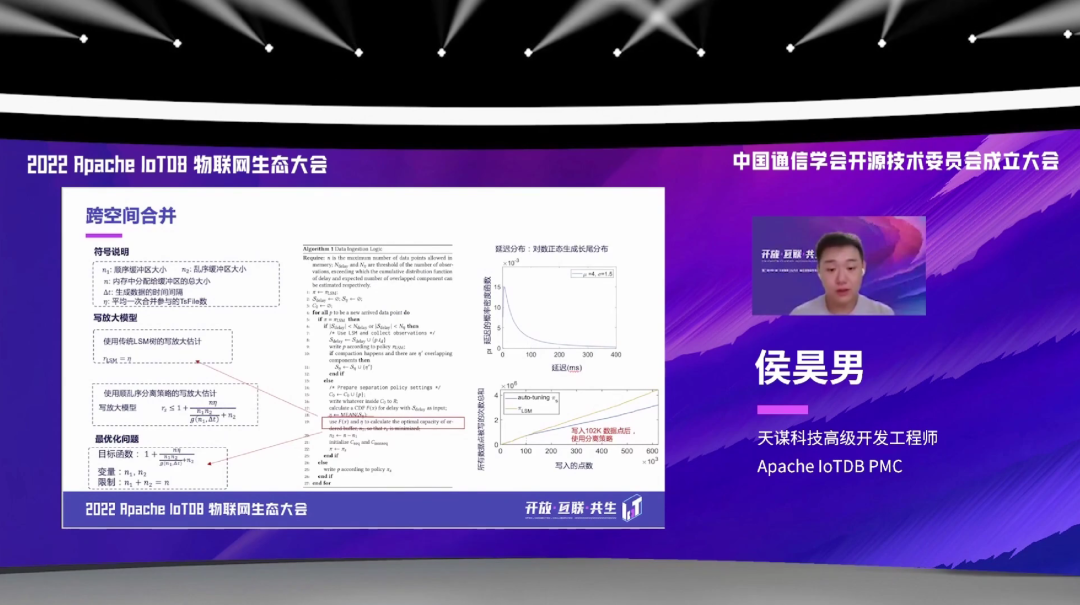
跟传统的 LSM-Tree 相比,IoTDB 使用了这样一个顺乱序分离策略,它的写放大会明显的较小。我们也是发表这样相关的一些论文,可以看到随着写入的点数的增多,右下角这个图,然后我们相比于传统的 LSM-Tree 来说,写入的次数更少一些,也是一个更优化的一个存储的模型。
本次我的分享大概就是这些,非常感谢大家的观看,谢谢大家。
更多内容推荐:
• 回顾 IoTDB 2022 大会全内容


