

12 月 3 日、4日,2022 Apache IoTDB 物联网生态大会在线上圆满落幕。大会上发布 Apache IoTDB 的分布式 1.0 版本,并分享 Apache IoTDB 实现的数据管理技术与物联网场景实践案例,深入探讨了 Apache IoTDB 与物联网企业如何共建活跃生态,企业如何与开源社区紧密配合,实现共赢。
我们邀请到天谋科技高级开发工程师,Apache IoTDB PMC 张金瑞参加此次大会,并做主题演讲——《为物联网场景优化的时序数据库共识协议》。以下为内容全文。
各位听众大家好,今天我给大家带来分享的题目是《为物联网场景优化的时序数据库的共识协议》,我是今天的主讲人张金瑞。
今天我主要从三个角度给大家分享一下为物联网场景优化的时序数据库的共识协议,主要包括共识协议的框架、当前 IoTDB 分布式版本里面支持的共识协议的配置,以及我们着重给大家介绍的,我们专门为物联网场景优化的、自己定制的多种共识协议。
01 共识协议框架
首先,我给大家介绍一下共识协议的框架。
提到分布式存储系统,大家一定会关心多副本存储、多副本备份的问题。毫无疑问,在 Apache IoTDB 的分布式版本当中,我们加入了对数据多副本存储的支持。多副本可以给分布式存储系统带来更高的可用性,在数据查询的时候,也能提高数据并行的计算能力。当然,多副本存储也会对数据写入性能带来一定的冲击,因为多副本写入一定会比单副本写入要花费更多的写入资源。所以在这种情况下,多副本的数据还有一个要解决的问题,就是它需要在多个副本之间保持数据的一致性。
在 Apache IoTDB 的分布式版本当中,我们对上述的问题进行了比较深入的探讨与讨论,最终我们设计并实现了一种具有高度灵活性、丰富的配置、选项、以及适用于多种不同场景的共识协议框架。
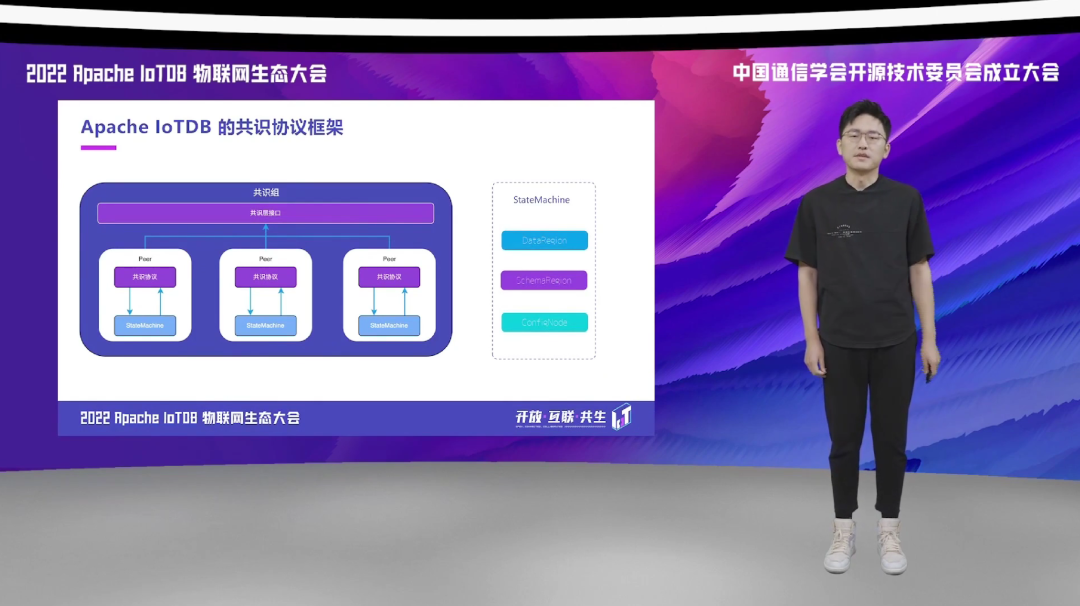
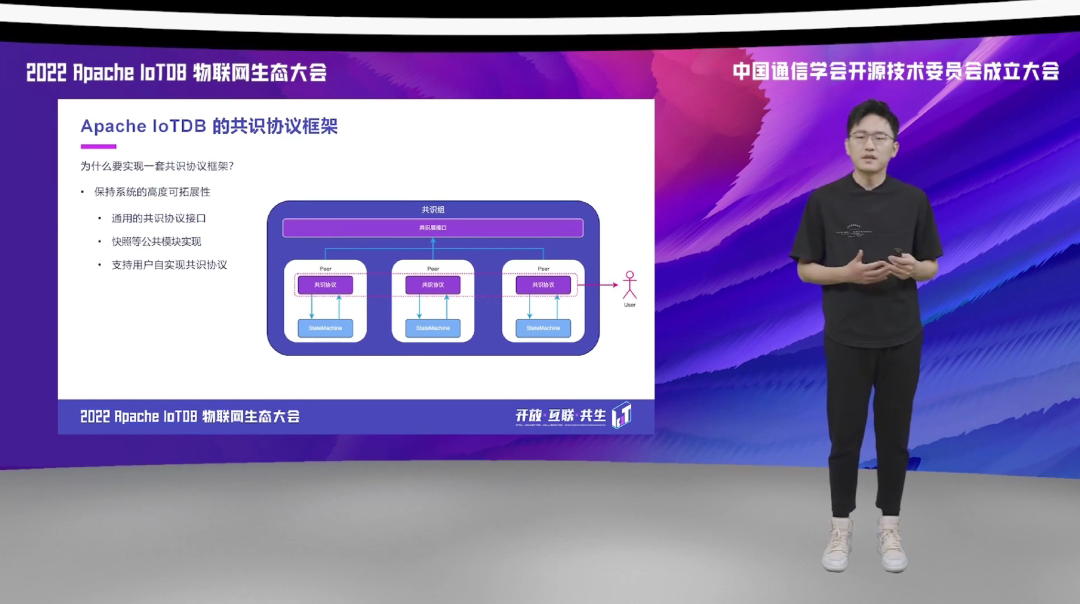
有些听众朋友可能会问,为什么要做一套共识协议的框架,而不是直接去实现对应的共识协议呢?这个主要是有两方面的原因。首先是场景的需求,客户在对数据库进行共识协议配置的时候,往往会由于不同的场景需求而产生对共识协议的不同维度的要求。这些维度主要表现在以下四个方面:强一致性的需求、高可用的需求、高吞吐的需求、以及存储成本的需求。
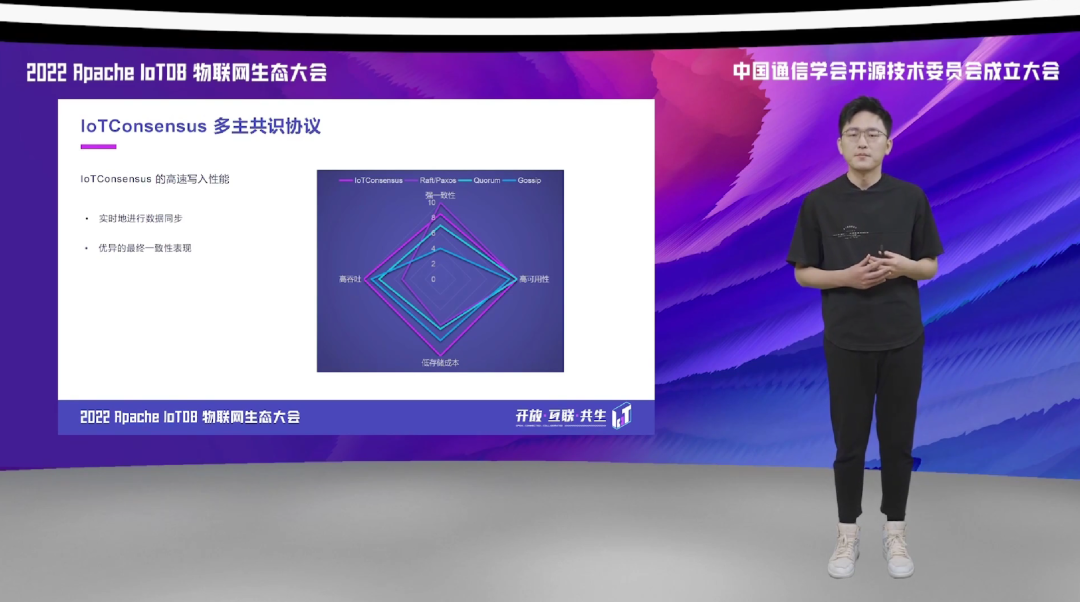
当前较为流行的一些共识协议,比如说 Raft、Paxos、 Quorum、Gossip 等,它们在这几个维度的侧重点也是不一样的。比如说如右图所示,像 Raft、Paxos 更强调一致性,而像 Quorum、Gossip 它们更强调高可用和高吞吐。IoTDB 本身是一款面向物联网场景应用的时序数据库,在实际的物联网的场景当中,它们对这几个维度要求更不一样,它们更强调高可用、低存储成本以及高吞吐。

所以,基于这是第一个我们做这个框架的原因,还有一个很重要的原因就是高拓展性。我们都知道,大数据存储与分布式系统的技术发展是日新月异的,共识协议的算法也具有很强的多样性,也是在不断的发展的。
如果通过这个共识协议的框架,Apache IoTDB 可以非常方便快捷地集成新的共识协议的算法,而无需对系统的查询存储等模块进行变更。具有开发经验的用户甚至可以基于自身的需求,然后定制化的开发自己的共识协议算法,并且把它应用到分布式的 Apache IoTDB 中来。
所以基于这些原因,我们开发了这一套共识协议的框架,让我们的系统来具有更强的拓展性。
02 共识协议配置
好了,介绍完共识协议的框架,我们来看一下分布式的 Apache IoTDB 的版本当中,目前已经内置并实现的几种共识协议。
在当前的 Apache IoTDB 的分布式版本当中,我们支持了三种不同的共识协议算法。它们分别是 Raft 协议,我们叫 RaftConsensus;然后 SimpleConsensus,是一个单副本的更轻量的协议;还有就是我们专门开发的这个 IoTConsensus,多组共识协议。
刚才也提到了,这个 IoTConsensus,它是我们 Apache IoTDB 首创的一种专门面向物联网场景优化的一个共识协议。在后文当中,我会详细的和大家介绍一下 IoTConsensus 它是如何与物联网场景进行紧密结合,它是如何设计的,以及它有哪些优势。

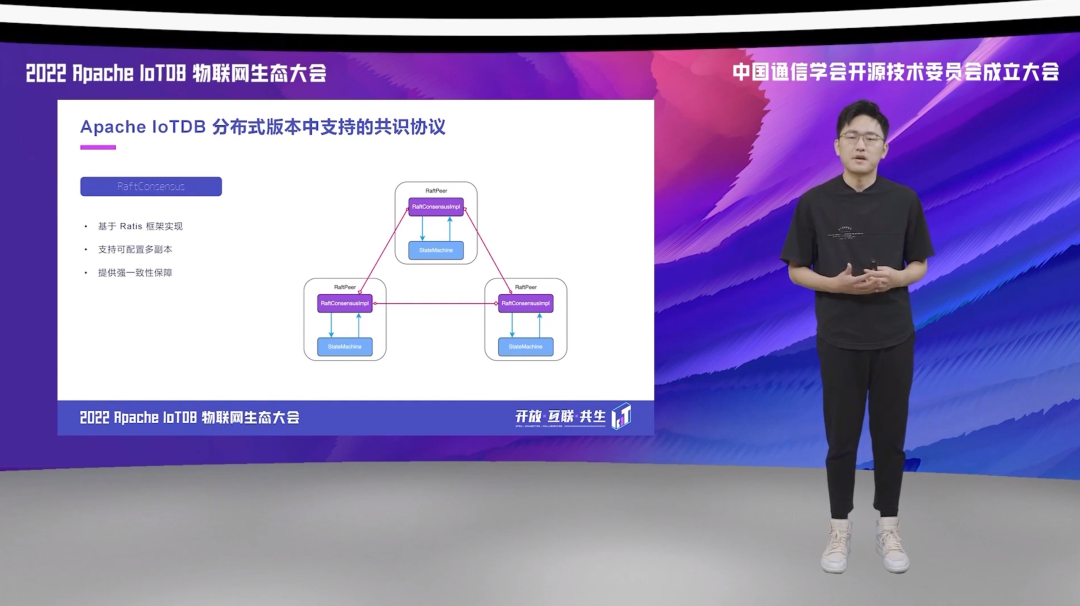
好,我们先来看一下我们内置第一个共识协议 RaftConsensus。RaftConsensus 是一种基于 Apache Ratis 实现的、支持多个副本的、同时还能提供强一致性保障的共识协议。右图是一个由 3 个副本组成的 Raft 的共识组的示意图。我们使用 Ratis 对共识层进行了实现,共识层可以分布在多个不同的 DataNode 上,然后共识组内部的 3 个成员通过共识层的接口,它们可以来进行相互的连通,选举 Leader,同时也可以进行数据的同步。
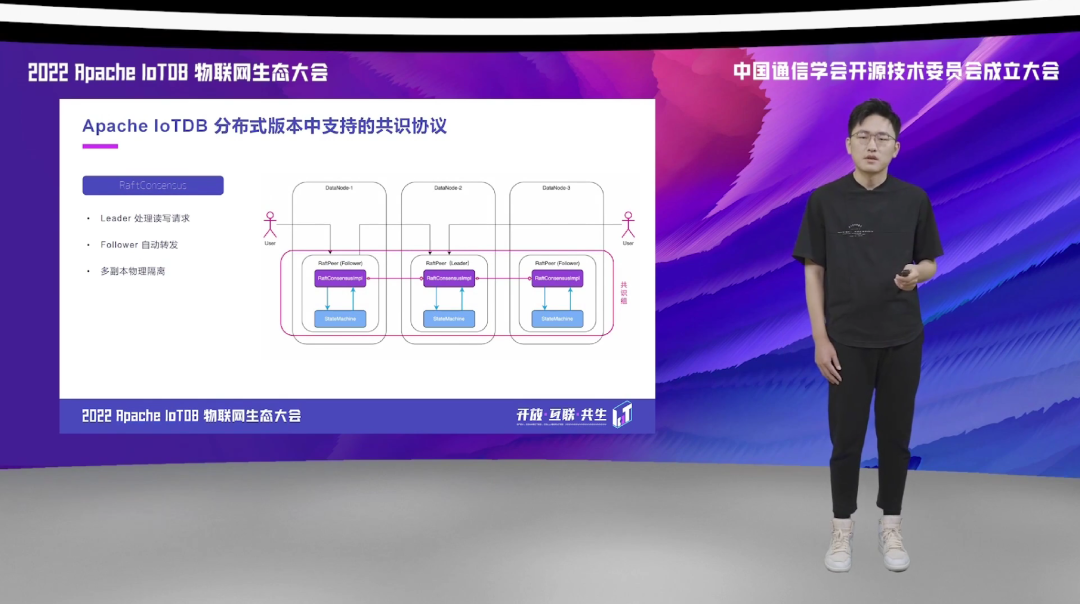
在数据的写入过程当中,IoTDB 会为待写入的数据创建对应的共识组。共识组创建完毕之后,数据会根据相应的分区策略,被写入到相应的共识组当中。同一个共识组的多个副本会被分配到不同的 DataNode 当中,用户在进行数据写入的时候,可以连接任意的 DataNode 进行数据写入。写入请求会通过共识层的接口,转发给相应的 Leader 来进行 Raft 日志的提交与同步。
比如说右图中我们所示的,一个由 3 个副本组成的 Raft 集群、Raft 共识组,每一个副本它都会分布在不同的 DataNode 上,然后副本之间通过共识层的实现来进行通信。它们组成一个共识组,选举 Leader,有了 Leader 之后,用户的写入和查询请求,会可以选择副本当中的任意一个节点进行发送。而这个请求,比如说写入请求,如果它的这个直联的副本是 Leader,它就会直接进行写入;如果不是的话,它可能会通过其中的副本,进行一个数据的转发,转发给 Leader 然后再去做操作。这就是一个 Raft 协议在我们当前的架构下的一个实现的一个示意图。
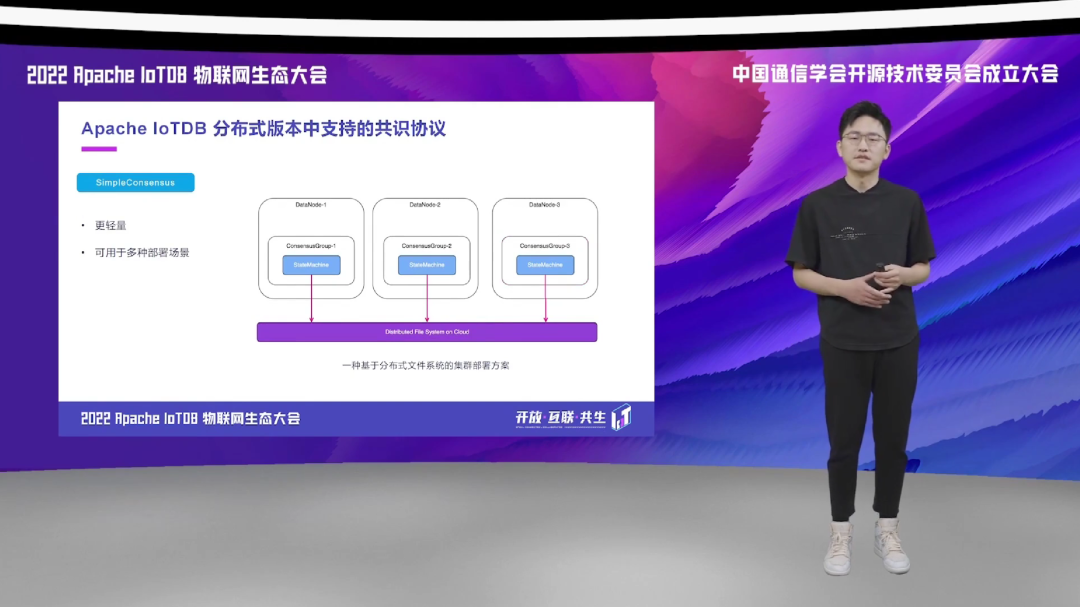
好,Apache IoTDB 内置的第二种共识协议叫做 SimpleConsensus,从它的名字我们就可以看的出来,它是一种非常轻量化的单副本的协议。它在数据写入和读取的过程当中,几乎是没有附加任何的冗余操作的,这就可以为数据的读取和写入提供非常好的性能表现。同时,基于 SimpleConsensus 集群的横向扩容操作是非常的轻量、简单的,因为它是一种单副本的共识协议,所以每个共识组它只包含一个状态机,每个共识组也只会分布在一个 DataNode 上面。这样的话,整体的结构就会变的非常的简单,在进行集群的扩容、缩容的时候,它们操作起来也会步骤变得更加的轻量。
比如说我们右图所示的,一个原本是有两个节点组成的一个分布式的集群,它上面有四个共识组。这四个共识组现在如果说,我们认为它的写入负担已经到达一定的限制,我们决定对集群进行一个扩容。我们增加一个物理的 DataNode 进来,进来之后我们可以做两种操作。第一个,可以非常方便的把一个已经存在的 共识组,迁移到新增的 DataNode 上,这个操作是非常简单的。其次就是,我们也可以在新的 DataNode 上,直接再创建一个新的共识组,根据写入的需求以及 ConfigNode 的规划。也就是说在 SimpleConsensus 协议下,这种扩容、迁移、操作都会变得更简单,整个集群的压力也会变得更小。

同时,SimpleConsensus 由于它的单副本、更轻量的特点,它在系统部署的时候,就可以适用于更多的、更广泛的应用场景。比如说,用户希望把 Apache IoTDB 部署在一套已经基于分布式的文件系统存储的一个平台上,它不需要 IoTDB 本身再去提供数据副本的冗余操作,这个时候它就可以选择 SimpleConsensus。那这个时候,在 IoTDB 的应用层,数据会被写成一个副本,但是在文件的存储层,在底层的文件系统里,它有可能会根据用户的场景有多副本的复制。这样的部署方法就给用户提供了更多的灵活选择的可能性,也为我们的云端部署的 Apache IoTDB 提供了一些新的方案和思路。
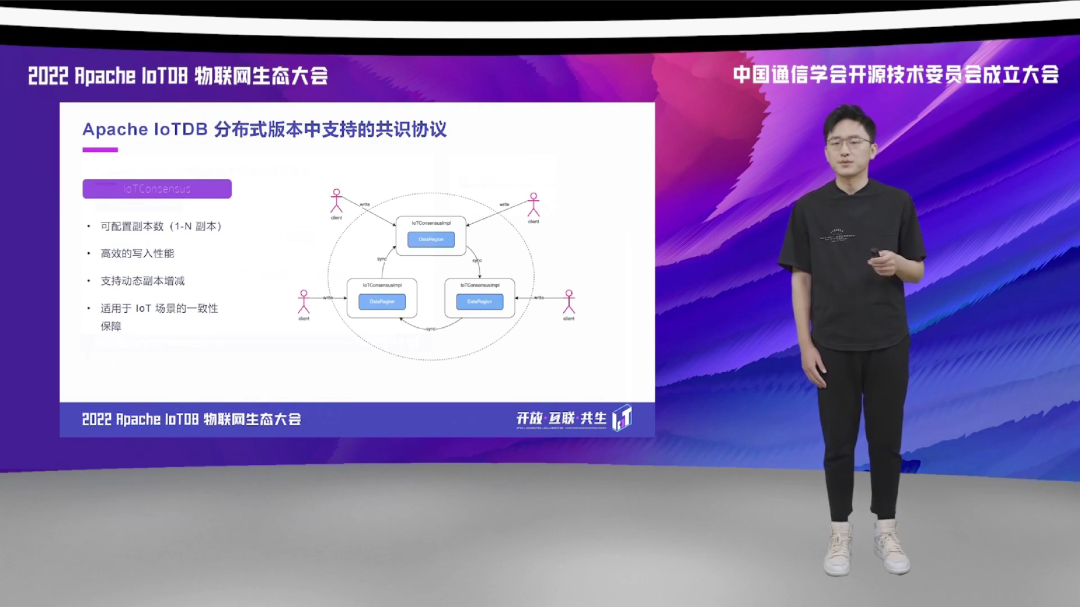
好,那么介绍完了前两种共识协议之后,我给大家介绍一下 Apache IoTDB 内置的第三种共识协议,也是我们着重想给大家介绍的一种协议,它叫做 IoTConsensus,是 Apache IoTDB 首创的、专门面向物联网场景优化的一种共识协议。IoTConsensus 它在部署的时候,对于副本的数量是没有限制的,它支持最低两个副本的高可用部署方案,副本的动态的增加和删除也是非常方便的。
同时, IoTConsensus 它最大的优势在于它具有非常强的数据写入的速度,它的写入性能其实可以和 SimpleConsensus 接近,也就是说它其实是保持了一个非常高的写入性能。同时,这个协议在一些我们 IoT 本身的能力的支持下,它也能够提供最终一致性、会话一致性这种一致性的保障。我们具体的来看一下。
03 多主共识协议
基于这个协议的特性我们把它命名为 IoTConsensus,我们来具体的看一下这个协议的一些实现以及它的一些优势。当然在介绍具体的 IoTConsensus 协议前,我想大家肯定会问一个问题,就是说为什么要专门去研发IoTConsensus?
其实这个原因是这样的,我给大家解释一下,我们给它叫多主共识协议,它是针对物联网场景设计的,那么我们对大多数的物联网的应用场景进行了一些调研。然后我们发现,大多数的物联网的应用场景,它对高可用、低存储成本以及高吞吐这三个维度有更高的要求。比如说,在我们最开始列出的一些共识协议的对比上,物联网场景下用户更要求这三个方面的性能。所以在应用到物联网的数据库的时候,我们现有的一些共识协议,很少能够在这三个维度都能做到非常好的表现,所以基于这个原因,我们决定去研发一个面向 IoT 场景专门优化的这样一种共识协议。
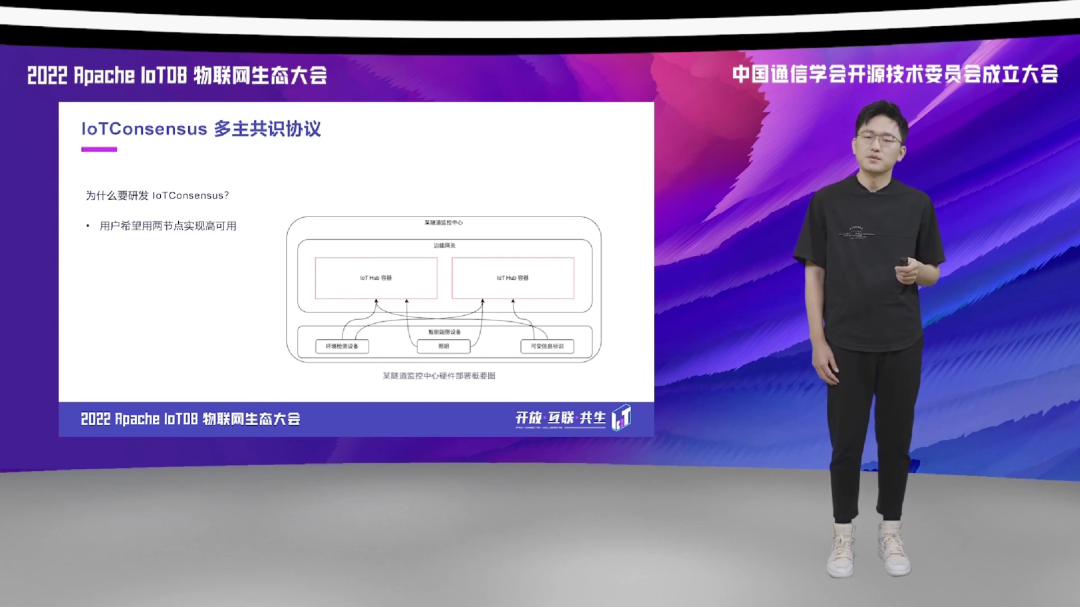
当然,还有两个比较重要的原因。第一个就是说,我们调研发现,在某些 IoT 部署的场景下,它们存在一些对两节点高可用的需求。那在当前的一些高可用的共识协议的配置下,最低也要求三个节点,它是没有办法满足这种部署场景的。
为什么会有两节点的这种高可用部署需求?比如说我举一个实际的例子,右图描述一个简要的隧道监控中心的硬件部署的概要图,这是一个实际的应用场景。在这个场景当中,处于边缘端系统资源的要求,以及相应的环境限制的条件下,我们在这个系统当中只能部署两个由 IoTHub 容器组成的双节点,只能通过它来进行系统的部署。那么在这种场景下,双节点的高可用系统就会显得非常的重要。
其次,物联网的应用场景还有一个非常明确的特点,那这个特点就是说,每个 Client 负责的数据都是来自于一个或者多个设备,是什么意思?就是说同一个设备的数据,通常只会由一个 Client 做写入,不会由多个Client同时写同一个设备的数据。
比如说右图举的这个例子,左边这个 Client 它负责写第一和第二组数据,右边这个 Client 它负责写的就是第三和第四组数据。红色和蓝色这两个 Client 它们写的数据之间很少,几乎是没有数据冲突的。那在这个特性下,也对我们设计和实现 IoTConsensus 提供了一些优化的思路。我们可以针对这个场景做一些优化,也就是说我们其实可以不用去关心数据冲突的问题,在这个协议实现的时候。

所以说,基于上述的这些原因,设计并研发一种新的、专门适用于物联网场景的一致性协议,就成了一件非常迫切的事情。经过我们团队的不断的努力与打磨,第一版的 IoTConsensus 也如期和大家见面了,下面我们来看一下它具体的工作原理。
IoTConsensus 本身是类似于一种 P2P 的架构,其中每个副本均可以直接对数据进行写入,写入本地成功之后,数据会被异步的复制到共识组的其他副本当中。当数据落后比较大的时候,我们可以直接通过快照进行数据的一次性的传输,然后减少网络传输的压力。所以基于 IoTDB 本身提供的能力,它几乎可以达到一种近乎于实时复制的效果。
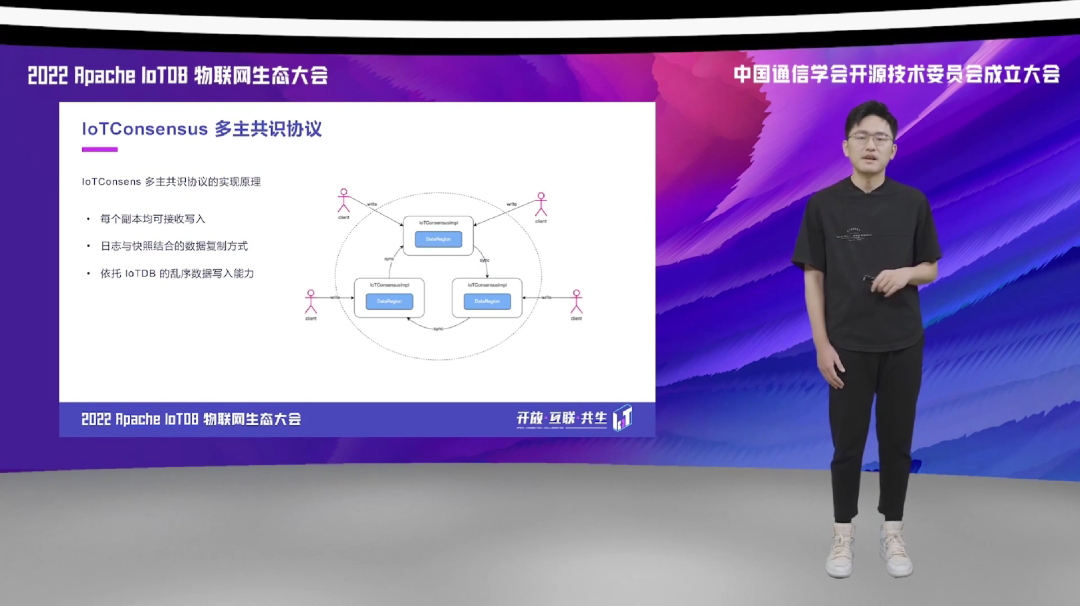
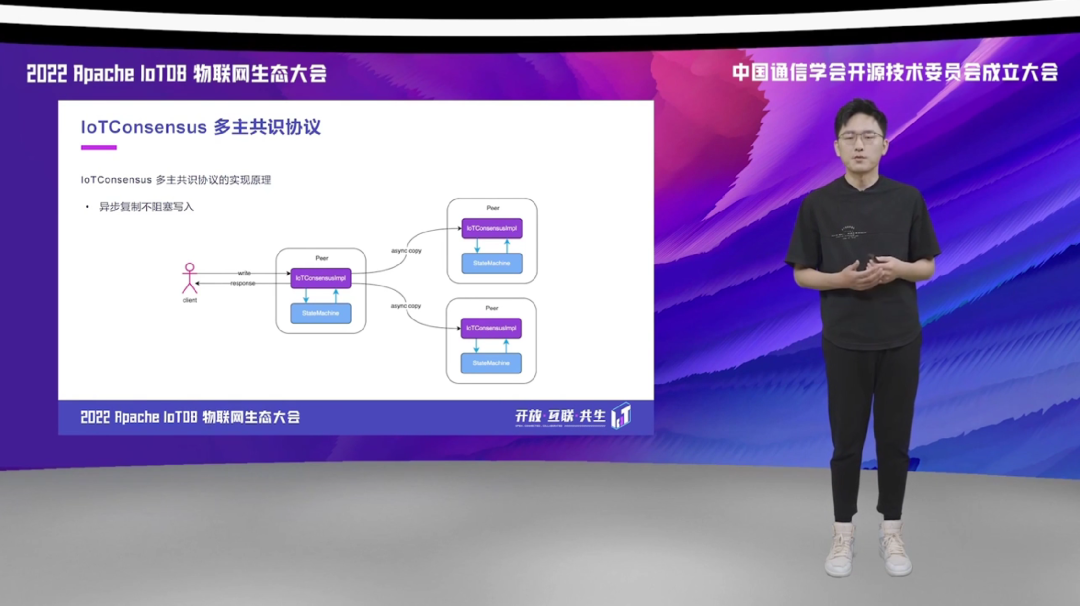
下面我们通过一个写入请求,来看一下 IoTConsensus 具体的实现过程。当用户把数据写到某个副本成功之后,这个副本会直接给 Client 返回成功的这样的一个 Response。同时,这个副本会记录它与其他副本之间的写入差距,并通过异步复制的方法,不断的把自己的数据复制给其他的副本,最终让各个副本之间的数据能够保持一致。
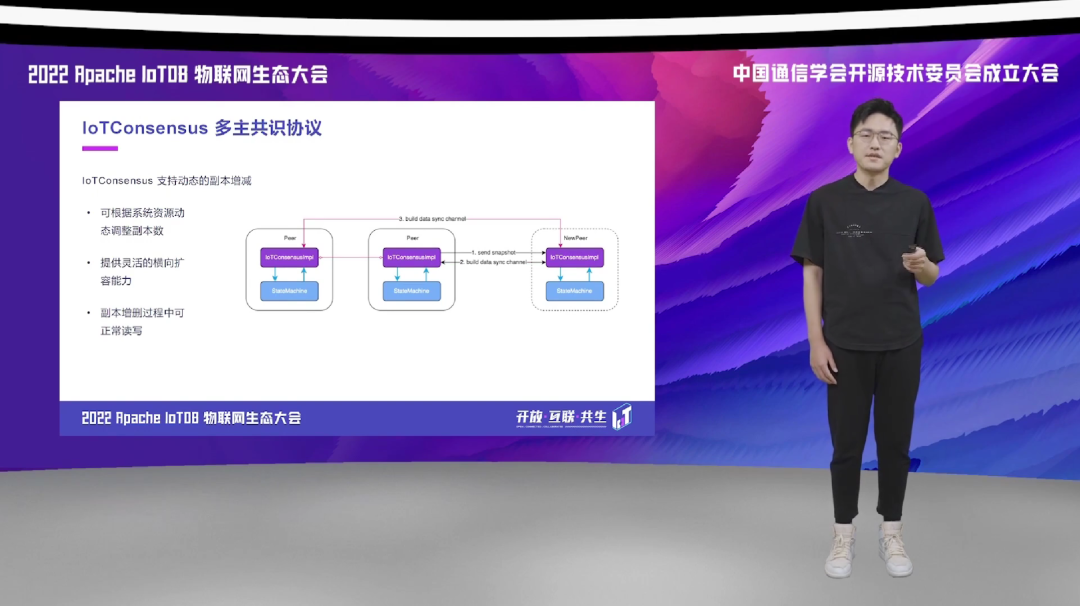
IoTConsensus 它还有一个非常重要的特性,就是它支持非常灵活的、动态的副本增减机制。这对于一个共识协议来讲也是非常重要的,有了这个动态的副本增减机制,分布式系统它在横向扩容的时候也会更加的灵活。所以, IoTConsensus 也天生地支持副本数的动态增减,得益于 IoTConsensus 本身它的这个解耦的设计,它的副本增减能够做到非常低的复杂程度,也给系统提供了更多的灵活性。
下面我们来看一下 IoTConsensus 当中,一个本来有两副本的共识组,在增加副本的时候,它的整个过程是什么样的。首先,如右图所示,当一个新的副本要增加到共识组当中的时候,我们首先在这个现有的副本当中,挑选一个作为一个种子副本,然后把它的快照传输给新的副本。快照传输完毕之后,我们再建立种子副本和新副本之间的数据相互复制的一个管道,那么它们两个就可以相互进行数据复制了。然后在做完这件事情之后,我们再去把原始的副本和新的副本之间建立数据同步管道,让它们之间也可以进行数据的相互复制。在这个操作完成之后,这三个副本之间都两两建立了数据同步的管道,那么这个新的副本就等于加入了原本的共识组,原本由两个副本组成的一个共识组,现在就可以变成一个由三个副本组成的一个共识组来工作。
整个过程它的步骤是非常少的,需要做的操作也是比较简单的。而且在整个副本的增加和删除的过程当中,针对该共识组的数据读取和写入都是可以不被影响的,在用户端操作是不会被感受到的。它也能够提供一个非常好的实时不下线的这样一种服务,基于这个共识协议,那么这个共识组它在对外提供读取写入服务的时候,也能有一个更好的表现。
另外,还有一个非常重要的特性,刚刚我们也提到了,就是说 IoTConsensus 它是可以提供一个非常高效的写入性能的。而且根据我们自己的实验表明,IoTConsensus 它的写入性能是接近于 SimpleConsensus,这个主要得益于以下几个方面。
首先是这样的,我想大家肯定也会问,你既然要做这个数据的复制,肯定要消耗资源,肯定要做持久化的存储,要消耗更多的硬件写入、磁盘读写等等,那为什么它能够达到一个非常好的写入性能?首先,我们看一下这个数据在写入到一个副本当中之后,IoTConsensus 并不会像 Raft 协议等,需要做更多的持久化操作,反而它不需要做更多的持久化操作。写入还是按照正常的流程来走,然后当前副本写入成功之后,它就会返回给客户端写入成功。
那这时候,你可能又会问了,那它是怎么去把自己的数据同步给其他节点的呢?如果自己没有做更多的持久化操作,那这个数据是怎么保证一定会被同步的?是这样的,我们是直接从 WAL 里面去读取带同步的数据,WAL 当中我们加入了相关的逻辑,在 compaction 过程中不会对没有发送的数据进行删除。也就是说,如果这个数据还没有被复制到其他的副本,那我在当前 WAL 里面的数据是不会被删掉的。有了这个逻辑的保证,我们能保证数据一定不会丢失,一定会被发出去。同时我们 WAL 这个数据本身它也是需要做持久化的,即使我们不用这个IoTConsensus,所以我们也在这个过程当中没有引入更多的持久化的操作。
然后在发送的时候,我们利用了一个多线程的、异步转发的操作。数据在发送的时候,可以充分利用网络带宽,不会由于网络原因,导致数据延迟发送。同时在接收端,我们也针对它的特点做了一些优化,在接收端的时候我们设计并实现了一种可以动态调整的、支持并发的反序列化的,同时还可以按照顺序进行写入的算法,来保证接收端的数据能够尽可能的并发的被处理,同时还能够按照原先副本的数据写入顺序,来进行自身的数据写入,从而减少乱序数据的产生。减少乱序数据的产生就可以充分的利用它的这个写入性能,数据能够在两个副本之间,它的整个传递过程变得更加的迅速、快捷。

所以,得益于 IoTConsensus 它的这个设计优势,它可以做到近乎实时的副本间的数据同步,这也给这个协议提供了非常好的一种表现。比如说,有了这些近乎实时的数据同步,IoTConsensus 的协议它在进行实际的运行过程当中,能够表现出非常好的最终一致性的保障。比如说,它的数据能够近乎实时的进行在副本之间的复制,不会出现大幅落后的情况。即使出现落后,我们也有其他的这个机制对它进行一个保障,比如说快照传输等等。
所以,综上所述我们能够看到 IoTConsensus 它具有一个非常好的表现,而且刚刚我们提到了一些接收端的数据并发写入排队、以及并发反序列化、顺序写入的一些算法,我们也有了相关的研究成果,相关研究成果已经入选了 VLDB 的相关论文,有兴趣的同学可以回头去看一下。

最后,我们再回顾一下多种不同共识协议在几个维度的表现,我们再来看一下本次给大家最开始放的一个多维的共识协议的比较的图。当我们把这个 IoTConsensus 加进来之后,我们会发现 IoTConsensus 与其他的共识协议相比,它在高可用、高吞吐以及低存储这三个维度上都能够具有非常好的表现。那么它在这三个维度上的优势也更适用于 IoT 场景,所以这是我们专门为 IoT 场景研发的一种共识协议,也会应用到我们的 Apache IoTDB 的分布式版本当中,能够给 IoT 场景的数据写入与读取提供更好的性能支持。
好的,这就是我今天的主要给大家分享的内容,感谢大家观看。
更多内容推荐:
• 回顾 IoTDB 2022 大会全内容


