
AINode
AINode
AINode 是支持时序相关模型注册、管理、调用的 IoTDB 原生节点,内置业界领先的自研时序大模型,如清华自研时序模型 Timer 系列,可通过标准 SQL 语句进行调用,实现时序数据的毫秒级实时推理,可支持时序趋势预测、缺失值填补、异常值检测等应用场景。
系统架构如下图所示:
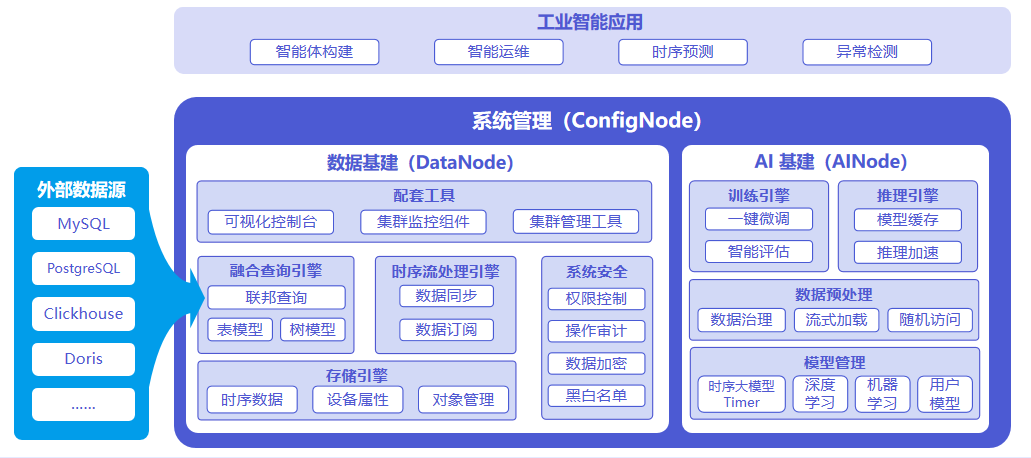
三种节点的职责如下:
- ConfigNode:负责分布式节点管理和负载均衡。
- DataNode:负责接收并解析用户的 SQL请求;负责存储时间序列数据;负责数据的预处理计算。
- AINode:负责时序模型的管理和使用。
1. 优势特点
与单独构建机器学习服务相比,具有以下优势:
- 简单易用:无需使用 Python 或 Java 编程,使用 SQL 语句即可完成机器学习模型管理与推理的完整流程。如创建模型可使用CREATE MODEL语句、使用模型进行推理可使用
SELECT * FROM FORECAST (...)语句等,使用更加简单便捷。 - 避免数据迁移:使用 IoTDB 原生机器学习可以将存储在 IoTDB 中的数据直接应用于机器学习模型的推理,无需将数据移动到单独的机器学习服务平台,从而加速数据处理、提高安全性并降低成本。

- 内置先进算法:支持业内领先机器学习分析算法,覆盖典型时序分析任务,为时序数据库赋能原生数据分析能力。如:
- 时间序列预测(Time Series Forecasting):从过去时间序列中学习变化模式;从而根据给定过去时间的观测值,输出未来序列最可能的预测。
- 时序异常检测(Anomaly Detection for Time Series):在给定的时间序列数据中检测和识别异常值,帮助发现时间序列中的异常行为。
2. 基本概念
- 模型(Model):机器学习模型,以时序数据作为输入,输出分析任务的结果或决策。模型是 AINode 的基本管理单元,支持模型的增(注册)、删、查、改(微调)、用(推理)。
- 创建(Create): 将外部设计或训练好的模型文件或算法加载到 AINode 中,由 IoTDB 统一管理与使用。
- 推理(Inference):使用创建的模型在指定时序数据上完成该模型适用的时序分析任务。
- 内置能力(Built-in):AINode 自带常见时序分析场景(例如预测与异常检测)的机器学习算法或自研模型。
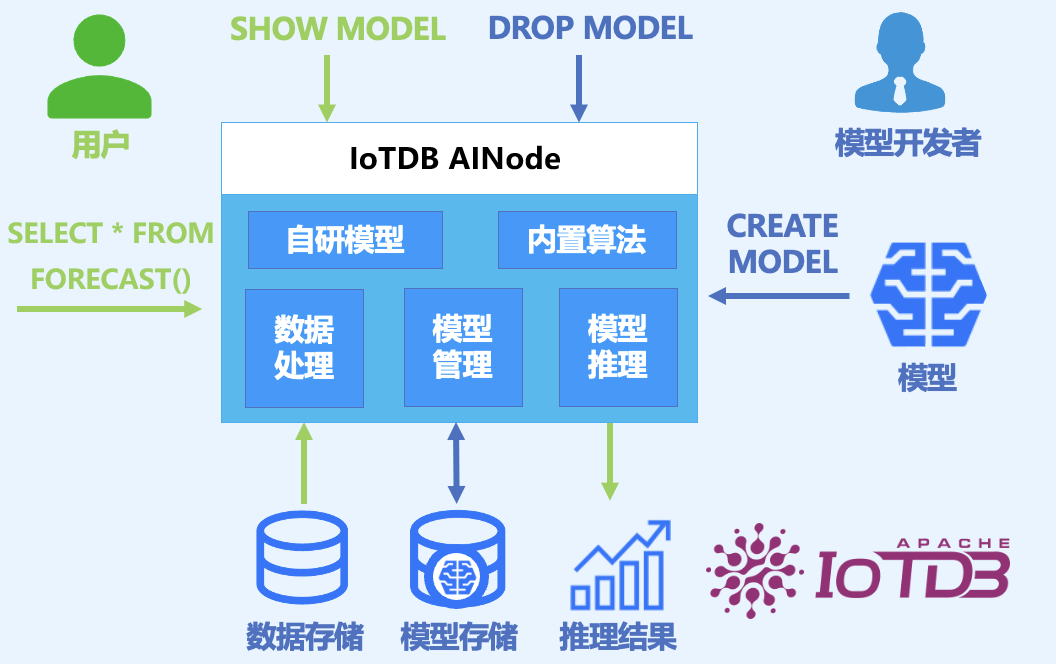
3. 安装部署
AINode 的部署可参考文档 AINode 部署 。
4. 使用指导
TimechoDB-AINode 支持模型推理、模型微调以及模型管理(注册、查看、删除、加载、卸载等)三大功能,下面章节将进行详细说明。
4.1 模型推理
TimechoDB-AINode 表模型支持时序预测和时序数据分类两大推理能力。
4.1.1 时序预测
表模型 AINode 提供的时序预测能力包括:
- 单变量预测:支持对单一目标变量进行预测。
- 协变量预测:可同时对多个目标变量进行联合预测,并支持在预测中引入协变量,以提升预测的准确性。
下文将详细介绍预测推理功能的语法定义、参数说明以及使用实例。
- SQL 语法
SELECT * FROM FORECAST(
MODEL_ID,
TARGETS, -- 获取目标变量的 SQL
[HISTORY_COVS, -- 字符串,用于获取历史协变量的 SQL
FUTURE_COVS, -- 字符串,用于获取未来协变量的 SQL
OUTPUT_START_TIME,
OUTPUT_LENGTH,
OUTPUT_INTERVAL,
TIMECOL,
PRESERVE_INPUT,
AUTO_ADAPT, -- bool类型,表示是否开启自适应
MODEL_OPTIONS]?
)- 内置模型推理无需注册流程,通过 forecast 函数,指定 model_id 就可以使用模型的推理功能。
- 参数介绍
| 参数名 | 参数类型 | 参数属性 | 描述 | 是否必填 | 备注 |
|---|---|---|---|---|---|
| model_id | 标量参数 | 字符串类型 | 预测所用模型的唯一标识 | 是 | |
| targets | 表参数 | SET SEMANTIC | 待预测目标变量的输入数据。IoTDB会自动将数据按时间升序排序再交给AINode 。 | 是 | 使用 SQL 描述带预测目标变量的输入数据,输入的 SQL 不合法时会有对应的查询报错。 |
| history_covs | 标量参数 | 字符串类型(合法的表模型查询 SQL)默认:无 | 指定此次预测任务的协变量的历史数据,这些数据用于辅助目标变量的预测,AINode 不会对历史协变量输出预测结果。在将数据给予模型前,AINode 会自动将数据按时间升序排序。 | 否 | 1. 查询结果只能包含 FIELD 列; 2. 其它:不同模型可能会有独特要求,不符合时会抛出对应的错误。 |
| future_covs | 标量参数 | 字符串类型(合法的表模型查询 SQL) 默认:无 | 指定此次预测任务部分协变量的未来数据,这些数据用于辅助目标变量的预测。 在将数据给予模型前,AINode 会自动将数据按时间升序排序。 | 否 | 1. 当且仅当设置 history_covs 时可以指定此参数; 2. 所涉及协变量名称必须是 history_covs 的子集; 3. 查询结果只能包含 FIELD 列; 4. 其它:不同模型可能会有独特要求,不符合时会抛出对应的错误。 |
| auto_adapt | 标量参数 | 布尔类型,默认值:true | 是否为协变量推理开启自适应。(V2.0.8.2起支持) | 否 | 当开启自适应时: 1. 若未来协变量集合future_covs不是历史协变量集合history_covs的子集,将自动抛弃那些不属于历史协变量的未来协变量。 2. 若某个历史协变量的长度不等于输入目标变量的长度:a. 小于时,在其头部补 0;b. 大于时,自动丢弃其最早的数据。 3. 若某个未来协变量的长度不等于预测长度output_length: a. 小于时,在其尾部补 0;b. 大于时,自动丢弃其最新的数据。 |
| output_start_time | 标量参数 | 时间戳类型。 默认值:目标变量最后一个时间戳 + output_interval | 输出的预测点的起始时间戳 【即起报时间】 | 否 | 必须大于目标变量时间戳的最大值 |
| output_length | 标量参数 | INT32 类型。 默认值:96 | 输出窗口大小 | 否 | 必须大于 0 |
| output_interval | 标量参数 | 时间间隔类型。 默认值:(输入数据的最后一个时间戳 - 输入数据的第一个时间戳) / n - 1 | 输出的预测点之间的时间间隔 支持的单位是 ns、us、ms、s、m、h、d、w | 否 | 必须大于 0 |
| timecol | 标量参数 | 字符串类型。 默认值:time | 时间列名 | 否 | 必须为存在于 targets 中的且数据类型为 TIMESTAMP 的列 |
| preserve_input | 标量参数 | 布尔类型。 默认值:false | 是否在输出结果集中保留目标变量输入的所有原始行 | 否 | |
| model_options | 标量参数 | 字符串类型。 默认值:空字符串 | 模型相关的 key-value 对,比如是否需要对输入进行归一化等。不同的 key-value 对以 ';' 间隔 | 否 |
说明:
- 默认行为:预测 targets 的所有列。当前仅支持 INT32、INT64、FLOAT、DOUBLE 类型。
- 输入数据要求:
- 必须包含时间列。
- 行数要求:不足最低行数会报错,超过最大行数则自动截取末尾数据。
- 列数要求:单变量模型仅支持单列,多列将报错;协变量模型通常无限制,除非模型自身有明确约束。
- 协变量预测时,SQL 语句中需明确指定 DATABASE。
- 输出结果:
- 包含所有目标变量列,数据类型与原表一致。
- 若指定
preserve_input=true,会额外增加is_input列来标识原始数据行。
- 时间戳生成:
- 使用
OUTPUT_START_TIME(可选)作为预测起始时间点,并以此划分历史与未来数据。 - 使用
OUTPUT_INTERVAL(可选,默认为输入数据的采样间隔)作为输出时间间隔。第 N 行的时间戳计算公式为:OUTPUT_START_TIME + (N - 1) * OUTPUT_INTERVAL。
- 使用
- 使用示例
示例一:单变量预测
提前创建数据库 etth 及表 eg
create database etth;
create table eg (hufl FLOAT FIELD, hull FLOAT FIELD, mufl FLOAT FIELD, mull FLOAT FIELD, lufl FLOAT FIELD, lull FLOAT FIELD, ot FLOAT FIELD)准备原始数据 ETTh1-tab,可通过 import-data 脚本导入原始数据,例如
./tools/import-data.sh -ft csv -sql_dialect table -db etth -table eg -s ~/Desktop/model-compare-html/ETTh1-tab.csv使用表 eg 中测点 ot 已知的 1440 行数据,预测其未来的 96 行数据.
IoTDB:etth> select Time, HUFL,HULL,MUFL,MULL,LUFL,LULL,OT from eg LIMIT 1440
+-----------------------------+------+-----+-----+-----+-----+-----+------+
| Time| HUFL| HULL| MUFL| MULL| LUFL| LULL| OT|
+-----------------------------+------+-----+-----+-----+-----+-----+------+
|2016-07-01T00:00:00.000+08:00| 5.827|2.009|1.599|0.462|4.203| 1.34|30.531|
|2016-07-01T01:00:00.000+08:00| 5.693|2.076|1.492|0.426|4.142|1.371|27.787|
|2016-07-01T02:00:00.000+08:00| 5.157|1.741|1.279|0.355|3.777|1.218|27.787|
|2016-07-01T03:00:00.000+08:00| 5.09|1.942|1.279|0.391|3.807|1.279|25.044|
......
Total line number = 1440
It costs 0.119s
IoTDB:etth> select * from forecast(
model_id => 'sundial',
targets => (select Time, ot from etth.eg where time >= 2016-08-07T18:00:00.000+08:00 limit 1440) order BY time,
output_length => 96
)
+-----------------------------+---------+
| time| ot|
+-----------------------------+---------+
|2016-10-06T18:00:00.000+08:00|20.733124|
|2016-10-06T19:00:00.000+08:00|20.258146|
|2016-10-06T20:00:00.000+08:00|20.022043|
|2016-10-06T21:00:00.000+08:00|19.789446|
......
Total line number = 96
It costs 1.615s示例二:协变量预测
提前创建表 tab_real(存储原始真实数据)
create table tab_real (target1 DOUBLE FIELD, target2 DOUBLE FIELD, cov1 DOUBLE FIELD, cov2 DOUBLE FIELD, cov3 DOUBLE FIELD);准备原始数据
--写入语句
IoTDB:etth> INSERT INTO tab_real (time, target1, target2, cov1, cov2, cov3) VALUES
(1, 1.0, 1.0, 1.0, 1.0, 1.0),
(2, 2.0, 2.0, 2.0, 2.0, 2.0),
(3, 3.0, 3.0, 3.0, 3.0, 3.0),
(4, 4.0, 4.0, 4.0, 4.0, 4.0),
(5, 5.0, 5.0, 5.0, 5.0, 5.0),
(6, 6.0, 6.0, 6.0, 6.0, 6.0),
(7, NULL, NULL, NULL, NULL, 7.0),
(8, NULL, NULL, NULL, NULL, 8.0);
IoTDB:etth> SELECT * FROM tab_real
+-----------------------------+-------+-------+----+----+----+
| time|target1|target2|cov1|cov2|cov3|
+-----------------------------+-------+-------+----+----+----+
|1970-01-01T08:00:00.001+08:00| 1.0| 1.0| 1.0| 1.0| 1.0|
|1970-01-01T08:00:00.002+08:00| 2.0| 2.0| 2.0| 2.0| 2.0|
|1970-01-01T08:00:00.003+08:00| 3.0| 3.0| 3.0| 3.0| 3.0|
|1970-01-01T08:00:00.004+08:00| 4.0| 4.0| 4.0| 4.0| 4.0|
|1970-01-01T08:00:00.005+08:00| 5.0| 5.0| 5.0| 5.0| 5.0|
|1970-01-01T08:00:00.006+08:00| 6.0| 6.0| 6.0| 6.0| 6.0|
|1970-01-01T08:00:00.007+08:00| null| null|null|null| 7.0|
|1970-01-01T08:00:00.008+08:00| null| null|null|null| 8.0|
+-----------------------------+-------+-------+----+----+----+预测任务一:使用历史协变量 cov1,cov2 和 cov3 辅助预测目标变量 target1 和 target2。
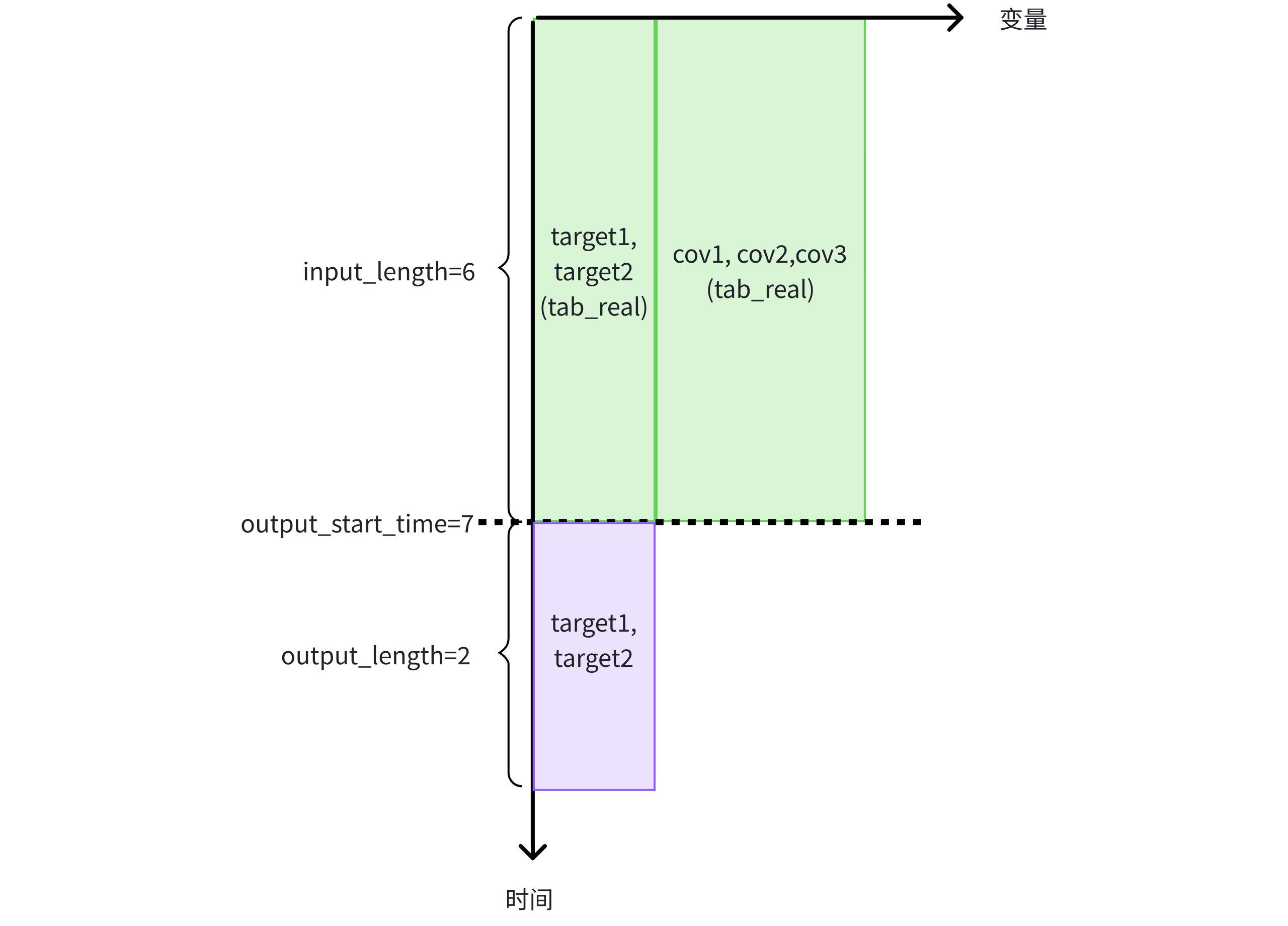
- 使用表 tab_real 中 cov1,cov2,cov3,target1,target2 的 前 6 行历史数据,预测目标变量 target1 和 target2 未来的 2 行数据
IoTDB:etth> SELECT * FROM FORECAST ( MODEL_ID => 'chronos2', TARGETS => ( SELECT TIME, target1, target2 FROM etth.tab_real WHERE TIME < 7 ORDER BY TIME DESC LIMIT 6) ORDER BY TIME, HISTORY_COVS => ' SELECT TIME, cov1, cov2, cov3 FROM etth.tab_real WHERE TIME < 7 ORDER BY TIME DESC LIMIT 6', OUTPUT_LENGTH => 2 ) +-----------------------------+-----------------+-----------------+ | time| target1| target2| +-----------------------------+-----------------+-----------------+ |1970-01-01T08:00:00.007+08:00|7.338330268859863|7.338330268859863| |1970-01-01T08:00:00.008+08:00| 8.02529525756836| 8.02529525756836| +-----------------------------+-----------------+-----------------+ Total line number = 2 It costs 0.315s
- 使用表 tab_real 中 cov1,cov2,cov3,target1,target2 的 前 6 行历史数据,预测目标变量 target1 和 target2 未来的 2 行数据
预测任务二:使用相同表中的历史协变量 cov1,cov2 和已知协变量 cov3 辅助预测目标变量 target1 和 target2。
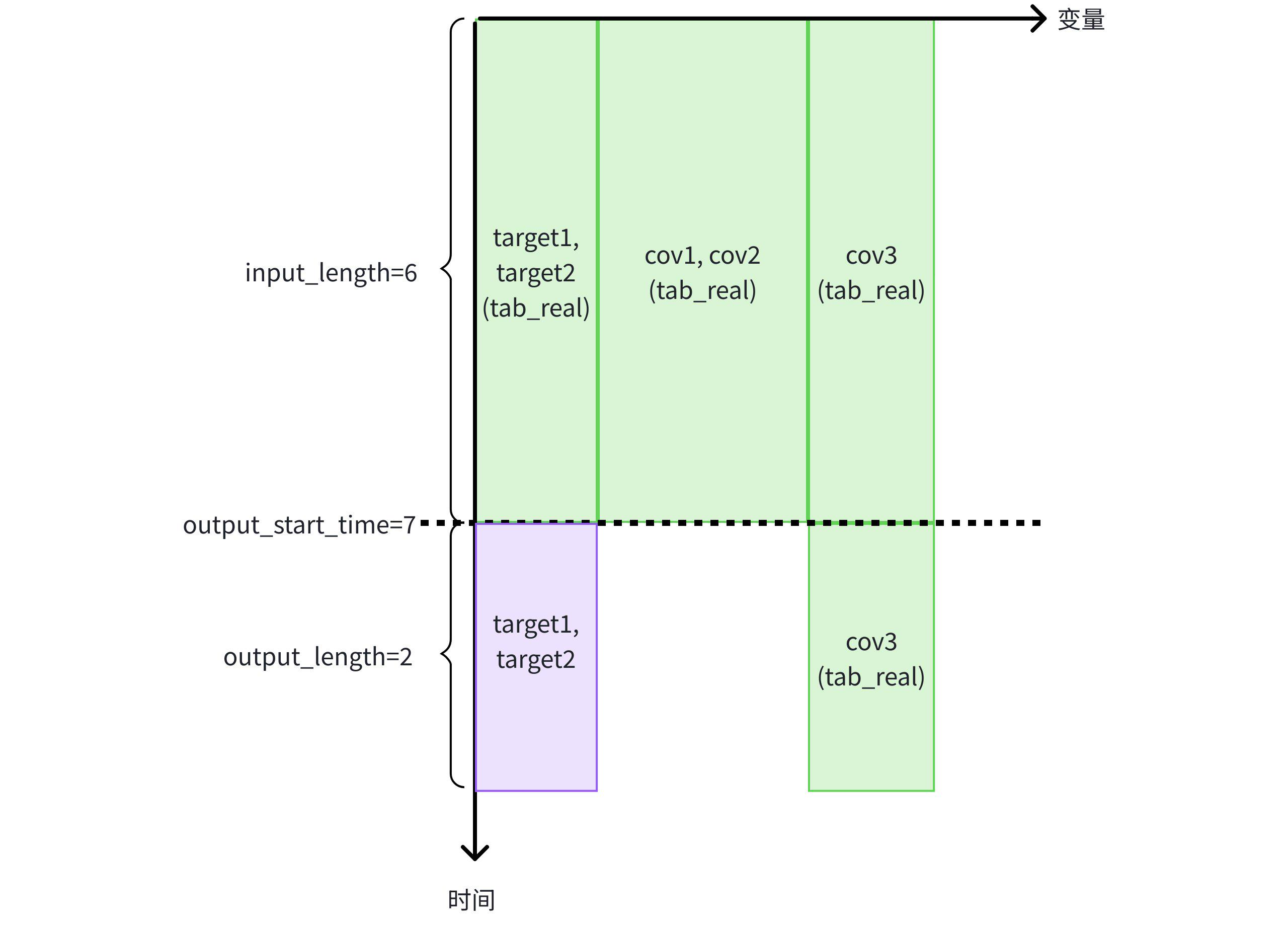
- 使用表 tab_real 中 cov1,cov2,cov3,target1,target2 的 前 6 行历史数据,以及同表中已知协变量 cov3 在未来的 2 行数据来预测目标变量 target1 和 target2 未来的 2 行数据
IoTDB:etth> SELECT * FROM FORECAST ( MODEL_ID => 'chronos2', TARGETS => ( SELECT TIME, target1, target2 FROM etth.tab_real WHERE TIME < 7 ORDER BY TIME DESC LIMIT 6) ORDER BY TIME, HISTORY_COVS => ' SELECT TIME, cov1, cov2, cov3 FROM etth.tab_real WHERE TIME < 7 ORDER BY TIME DESC LIMIT 6', FUTURE_COVS => ' SELECT TIME, cov3 FROM etth.tab_real WHERE TIME >= 7 LIMIT 2', OUTPUT_LENGTH => 2 ) +-----------------------------+-----------------+-----------------+ | time| target1| target2| +-----------------------------+-----------------+-----------------+ |1970-01-01T08:00:00.007+08:00|7.244050025939941|7.244050025939941| |1970-01-01T08:00:00.008+08:00|7.907227516174316|7.907227516174316| +-----------------------------+-----------------+-----------------+ Total line number = 2 It costs 0.291s
- 使用表 tab_real 中 cov1,cov2,cov3,target1,target2 的 前 6 行历史数据,以及同表中已知协变量 cov3 在未来的 2 行数据来预测目标变量 target1 和 target2 未来的 2 行数据
预测任务三:使用不同表中的历史协变量 cov1,cov2 和已知协变量 cov3 辅助预测目标变量 target1 和 target2。
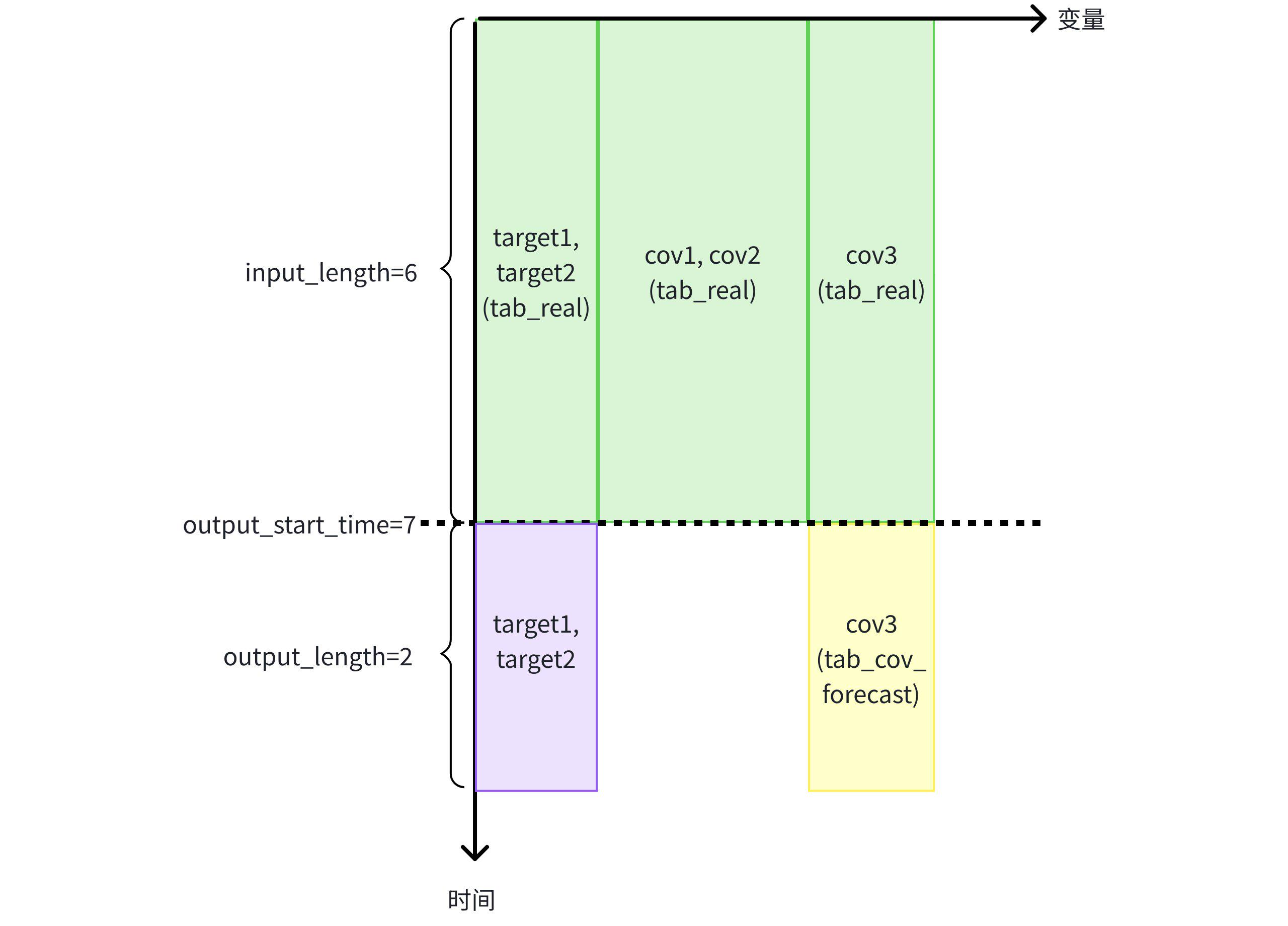
- 提前创建表 tab_cov_forecast(存储已知协变量 cov3 的预测值 ),并准备相关数据。
create table tab_cov_forecast (cov3 DOUBLE FIELD); --写入语句 INSERT INTO tab_cov_forecast (time, cov3) VALUES (7, 7.0),(8, 8.0); IoTDB:etth> SELECT * FROM tab_cov_forecast +----+----+ |time|cov3| +----+----+ | 7| 7.0| | 8| 8.0| +----+----+ - 使用表 tab_real 中 cov1,cov2,cov3,target1,target2 已知的前 6 行数据,以及表 tab_cov_forecast 中已知协变量 cov3 在未来的 2 行数据来预测目标变量 target1 和 target2 未来的 2 行数据
IoTDB:etth> SELECT * FROM FORECAST ( MODEL_ID => 'chronos2', TARGETS => ( SELECT TIME, target1, target2 FROM etth.tab_real WHERE TIME < 7 ORDER BY TIME DESC LIMIT 6) ORDER BY TIME, HISTORY_COVS => ' SELECT TIME, cov1, cov2, cov3 FROM etth.tab_real WHERE TIME < 7 ORDER BY TIME DESC LIMIT 6', FUTURE_COVS => ' SELECT TIME, cov3 FROM etth.tab_cov_forecast WHERE TIME >= 7 LIMIT 2', OUTPUT_LENGTH => 2 ) +-----------------------------+-----------------+-----------------+ | time| target1| target2| +-----------------------------+-----------------+-----------------+ |1970-01-01T08:00:00.007+08:00|7.244050025939941|7.244050025939941| |1970-01-01T08:00:00.008+08:00|7.907227516174316|7.907227516174316| +-----------------------------+-----------------+-----------------+ Total line number = 2 It costs 0.351s
- 提前创建表 tab_cov_forecast(存储已知协变量 cov3 的预测值 ),并准备相关数据。
4.1.2 时序分类
时序分类是时序预测之外的重要能力,在工业界具有广泛应用。其典型范式是输入多个测点的近期采样值,综合判断设备整体运行状态,输出当前状态的分类标签。例如:可用于新能源电池组设备的运行状态分类等场景。
AINode 表模型支持通过调用协变量分类模型执行时序数据的分类任务。
注意:该功能从 V2.0.9.1 版本开始提供。
- SQL 语法
SELECT * FROM CLASSIFY(
MODEL_ID,
INPUTS -- 获取输入变量的 SQL
[TIMECOL,
MODEL_OPTIONS]?
)- 参数介绍
| 参数名 | 参数类型 | 参数属性 | 描述 | 是否必填 | 备注 |
|---|---|---|---|---|---|
| model_id | 标量参数 | 字符串类型 | 分类所用模型的唯一标识 | 是 | |
| inputs | 表参数 | SET SEMANTIC | 输入的待分类数据。IoTDB 会自动将数据按时间升序排序再交给 AINode 。 | 是 | 使用 SQL 描述输入的待分类数据,输入的 SQL 不合法时会有对应的查询报错。 |
| timecol | 标量参数 | 字符串类型,默认值:time | 时间列名 | 否 | 存在于 inputs 中的,数据类型为 TIMESTAMP 的列,否则报错。 |
| model_options | 标量参数 | 字符串类型默认值:空字符串。 | 模型相关的 key-value 对,比如是否需要对输入进行归一化等。不同的 key-value 对以 ';' 间隔 | 否 | 指定某个模型不支持参数,并不会报错,只会被忽略 |
说明:
- 输入数据要求:
- 类型约束:目前仅支持 INT32、INT64、FLOAT、DOUBLE 类型。
- 行数要求:不同模型要求不同。对于有行数限制的模型,低于最小行数或高于最多行数时将报错。
- 列数要求:必须包含时间列。单变量分类模型仅支持单列,多列将报错;多变量分类模型通常无限制,除非模型自身有明确约束。
- 顺序要求:多变量零样本分类模型通常无限制,除非模型自身有明确约束。
- 输出结果:
- 返回结果是由时序数据的分类结果组成的表,其规格取决于模型的具体实现。
- 使用示例
假设某项目的时序数据的变量数为10,输入长度为192。以自定义的 mantis_custom 模型为例进行时序数据分类推理。
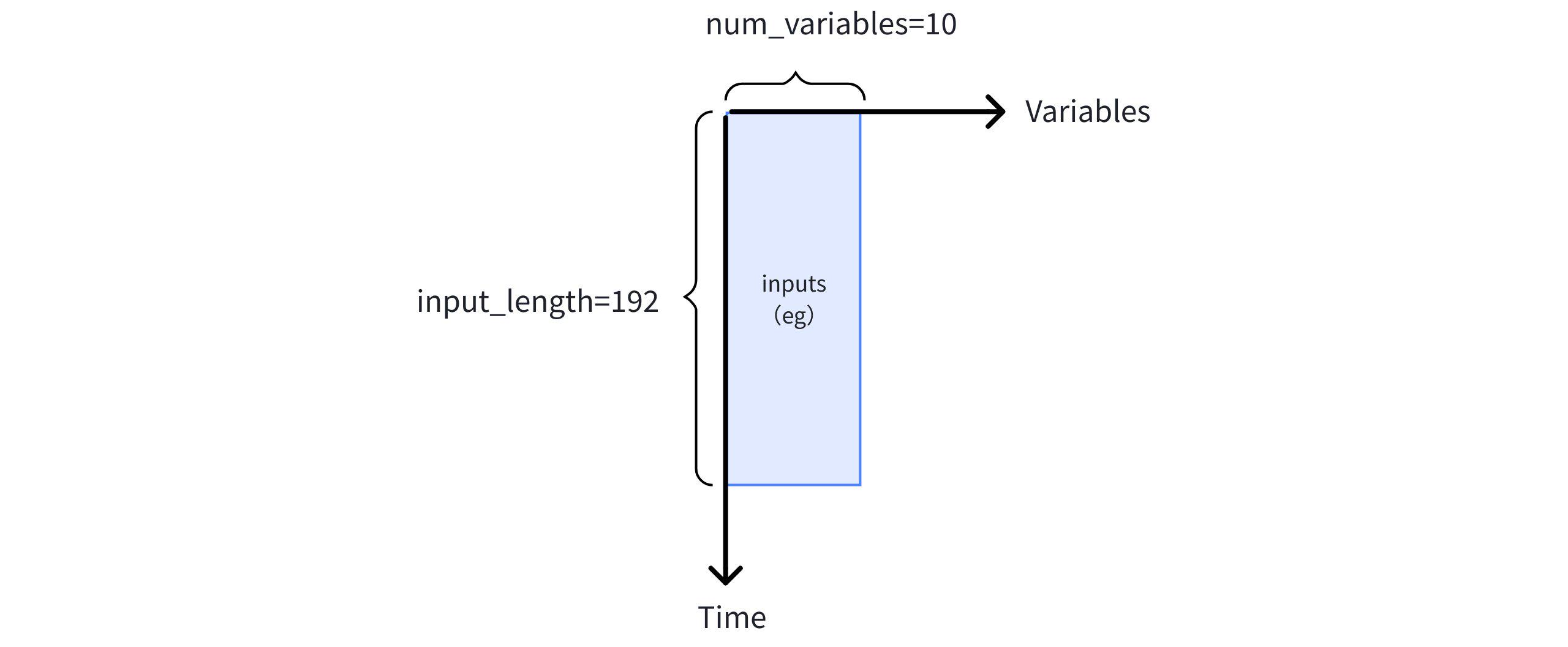
- 注册模型
CREATE MODEL mantis_custom USING URI 'file:///path/to/mantis'注册自定义模型的详细步骤说明可参考 4.3 小节。
- 运行SQL
IoTDB:etth> SELECT * FROM CLASSIFY (
MODEL_ID => 'mantis_custom',
INPUTS => (
SELECT Time, HUFL,HULL,MUFL,MULL,LUFL,LULL,OT,UT,MT,LT
FROM eg
WHERE TIME < 2016-07-09 00:00:00
ORDER BY TIME DESC
LIMIT 192) ORDER BY TIME
)- 执行结果
+--------+
|category|
+--------+
| 4|
+--------+4.2 模型微调
AINode 支持通过 SQL 进行模型微调任务。
SQL 语法
createModelStatement
| CREATE MODEL modelId=identifier (WITH HYPERPARAMETERS '(' hparamPair (',' hparamPair)* ')')? FROM MODEL existingModelId=identifier ON DATASET '(' targetData=string ')'
;
hparamPair
: hparamKey=identifier '=' hyparamValue=primaryExpression
;参数说明
| 名称 | 描述 |
|---|---|
| modelId | 微调出的模型的唯一标识 |
| hparamPair | 微调使用的超参数 key-value 对,目前支持如下:train_epochs: int 类型,微调轮数 iter_per_epoch: int 类型,每轮微调的迭代次数 learning_rate: double 类型,学习率 |
| existingModelId | 微调使用的基座模型 |
| targetData | 用于获取微调使用的数据集的 SQL |
示例
- 选择测点 ot 中指定时间范围的数据作为微调数据集,基于 sundial 创建模型 sundialv3。
IoTDB> set sql_dialect=table
Msg: The statement is executed successfully.
IoTDB> CREATE MODEL sundialv3 FROM MODEL sundial ON DATASET ('SELECT time, ot from etth.eg where 1467302400000 <= time and time < 1517468400001')
Msg: The statement is executed successfully.
IoTDB> show models
+---------------------+---------+-----------+---------+
| ModelId|ModelType| Category| State|
+---------------------+---------+-----------+---------+
| arima| sktime| builtin| active|
| holtwinters| sktime| builtin| active|
|exponential_smoothing| sktime| builtin| active|
| naive_forecaster| sktime| builtin| active|
| stl_forecaster| sktime| builtin| active|
| gaussian_hmm| sktime| builtin| active|
| gmm_hmm| sktime| builtin| active|
| stray| sktime| builtin| active|
| timer_xl| timer| builtin| active|
| sundial| sundial| builtin| active|
| chronos2| t5| builtin| active|
| sundialv2| sundial| fine_tuned| active|
| sundialv3| sundial| fine_tuned| training|
+---------------------+---------+-----------+---------+- 微调任务后台异步启动,可在 AINode 进程看到 log;微调完成后,查询并使用新的模型
IoTDB> show models
+---------------------+---------+-----------+---------+
| ModelId|ModelType| Category| State|
+---------------------+---------+-----------+---------+
| arima| sktime| builtin| active|
| holtwinters| sktime| builtin| active|
|exponential_smoothing| sktime| builtin| active|
| naive_forecaster| sktime| builtin| active|
| stl_forecaster| sktime| builtin| active|
| gaussian_hmm| sktime| builtin| active|
| gmm_hmm| sktime| builtin| active|
| stray| sktime| builtin| active|
| timer_xl| timer| builtin| active|
| sundial| sundial| builtin| active|
| chronos2| t5| builtin| active|
| sundialv2| sundial| fine_tuned| active|
| sundialv3| sundial| fine_tuned| active|
+---------------------+---------+-----------+---------+4.3 注册自定义模型
符合以下要求的 Transformers 模型可以注册到 AINode 中:
AINode 目前使用 v4.56.2 版本的 transformers,构建模型时需避免继承低版本(<4.50)接口;
模型需继承一类 AINode 的推理任务流水线(当前支持预测流水线):
- iotdb-core/ainode/iotdb/ainode/core/inference/pipeline/basic_pipeline.py
V2.0.9.3 之前
class BasicPipeline(ABC): def __init__(self, model_id, **model_kwargs): self.model_info = model_info self.device = model_kwargs.get("device", "cpu") self.model = load_model(model_info, device_map=self.device, **model_kwargs) @abstractmethod def preprocess(self, inputs, **infer_kwargs): """ 在推理任务开始前对输入数据进行前处理,包括形状验证和数值转换。 """ pass @abstractmethod def postprocess(self, output, **infer_kwargs): """ 在推理任务结束后对输出结果进行后处理。 """ pass class ForecastPipeline(BasicPipeline): def __init__(self, model_info, **model_kwargs): super().__init__(model_info, model_kwargs=model_kwargs) def preprocess(self, inputs: list[dict[str, dict[str, torch.Tensor] | torch.Tensor]], **infer_kwargs): """ 在将输入数据传递给模型进行推理之前进行预处理,验证输入数据的形状和类型。 Args: inputs (list[dict]): 输入数据,字典列表,每个字典包含: - 'targets': 形状为 (input_length,) 或 (target_count, input_length) 的张量。 - 'past_covariates': 可选,张量字典,每个张量形状为 (input_length,)。 - 'future_covariates': 可选,张量字典,每个张量形状为 (input_length,)。 infer_kwargs (dict, optional): 推理的额外关键字参数,如: - `output_length`(int): 如果提供'future_covariates',用于验证其有效性。 Raises: ValueError: 如果输入格式不正确(例如,缺少键、张量形状无效)。 Returns: 经过预处理和验证的输入数据,可直接用于模型推理。 """ pass def forecast(self, inputs, **infer_kwargs): """ 对给定输入执行预测。 Parameters: inputs: 用于进行预测的输入数据。类型和结构取决于模型的具体实现。 **infer_kwargs: 额外的推理参数,例如: - `output_length`(int): 模型应该生成的时间点数量。 Returns: 预测输出,具体形式取决于模型的具体实现。 """ pass def postprocess(self, outputs: list[torch.Tensor], **infer_kwargs) -> list[torch.Tensor]: """ 在推理后对模型输出进行后处理,验证输出数据的形状并确保其符合预期维度。 Args: outputs: 模型输出,2D张量列表,每个张量形状为 `[target_count, output_length]`。 Raises: InferenceModelInternalException: 如果输出张量形状无效(例如,维数错误)。 ValueError: 如果输出格式不正确。 Returns: list[torch.Tensor]: 后处理后的输出,将是一个2D张量列表。 """ passV2.0.9.3 起
class BasicPipeline(ABC): def __init__(self, model_id, **model_kwargs): self.model_info = model_info self.device = model_kwargs.get("device", "cpu") self.model = load_model(model_info, device_map=self.device, **model_kwargs) @abstractmethod def preprocess(self, inputs, **infer_kwargs): """ 在推理任务开始前对输入数据进行前处理,包括形状验证和数值转换。 """ pass @abstractmethod def postprocess(self, output, **infer_kwargs): """ 在推理任务结束后对输出结果进行后处理。 """ pass class ForecastPipeline(BasicPipeline): def __init__(self, model_info, **model_kwargs): super().__init__(model_info, model_kwargs=model_kwargs) def _preprocess( self, inputs: list[dict[str, dict[str, torch.Tensor] | torch.Tensor]], **infer_kwargs, ): """ 在将输入数据传递给模型进行推理之前进行预处理,验证输入数据的形状和类型。 Args: inputs (list[dict[str, dict[str, torch.Tensor] | torch.Tensor]]): 输入数据,字典列表,每个字典包含: - 'targets': 形状为 (input_length,) 或 (target_count, input_length) 的张量。 - 'past_covariates': 可选,张量字典,每个张量形状为 (input_length,)。 - 'future_covariates': 可选,张量字典,每个张量形状为 (input_length,)。 infer_kwargs (dict, optional): 推理的额外关键字参数,如: - `output_length`(int): 如果提供'future_covariates',用于验证其有效性。 Raises: ValueError: 如果输入格式不正确(例如,缺少键、张量形状无效)。 Returns: 经过预处理和验证的输入数据,可直接用于模型推理。 """ pass def forecast(self, inputs, **infer_kwargs): """ 对给定输入执行预测。 Parameters: inputs: 用于进行预测的输入数据。类型和结构取决于模型的具体实现。 **infer_kwargs: 额外的推理参数,例如: - `output_length`(int): 模型应该生成的时间点数量。 Returns: 预测输出,具体形式取决于模型的具体实现。 """ pass def _postprocess(self, outputs, **infer_kwargs) -> list[torch.Tensor]: """ 在推理后对模型输出进行后处理,验证输出数据的形状并确保其符合预期维度。 Args: outputs: 模型输出,2D张量列表,每个张量形状为 `[target_count, output_length]`。 Raises: InferenceModelInternalException: 如果输出张量形状无效(例如,维数错误)。 ValueError: 如果输出格式不正确。 Returns: list[torch.Tensor]: 后处理后的输出,将是一个2D张量列表。 """ pass修改模型配置文件 config.json,确保包含以下字段:
V2.0.9.3 之前
{ "auto_map": { "AutoConfig": "config.Chronos2CoreConfig", // 指定模型 Config 类 "AutoModelForCausalLM": "model.Chronos2Model" // 指定模型类 }, "pipeline_cls": "pipeline_chronos2.Chronos2Pipeline", // 指定模型的推理流水线 "model_type": "custom_t5", // 指定模型类型 }- 必须通过 auto_map 指定模型的 Config 类和模型类;
- 必须集成并指定推理流水线类;
- 对于 AINode 管理的内置(builtin)和自定义(user_defined)模型,模型类别(model_type)也作为不可重复的唯一标识。即,要注册的模型类别不得与任何已存在的模型类型重复,通过微调创建的模型将继承原模型的模型类别。
V2.0.9.3 起
参数 model_type 非必填
{ "auto_map": { "AutoConfig": "config.Chronos2CoreConfig", // 指定模型 Config 类 "AutoModelForCausalLM": "model.Chronos2Model" // 指定模型类 }, "pipeline_cls": "pipeline_chronos2.Chronos2Pipeline", // 指定模型的推理流水线 }- 必须通过 auto_map 指定模型的 Config 类和模型类;
- 必须集成并指定推理流水线类;
确保要注册的模型目录包含以下文件,且模型配置文件名称和权重文件名称不支持自定义:
- 模型配置文件:config.json;
- 模型权重文件:model.safetensors;
- 模型代码:其它 .py 文件。
注册自定义模型的 SQL 语法如下所示:
CREATE MODEL <model_id> USING URI <uri>参数说明:
- model_id:自定义模型的唯一标识;不可重复,有以下约束:
- 允许出现标识符 [ 0-9 a-z A-Z _ ] (字母,数字(非开头),下划线(非开头))
- 长度限制为 2-64 字符
- 大小写敏感
- uri:包含模型代码和权重的本地 uri 地址。
注册示例:
从本地路径上传自定义 Transformers 模型,AINode 会将该文件夹拷贝至 user_defined 目录中。
CREATE MODEL chronos2 USING URI 'file:///path/to/chronos2'SQL执行后会异步进行注册的流程,可以通过模型展示查看模型的注册状态(见查看模型章节)。模型注册完成后,就可以通过使用正常查询的方式调用具体函数,进行模型推理。
4.4 查看模型
注册成功的模型可以通过查看指令查询模型的具体信息。
SHOW MODELS除了直接展示所有模型的信息外,可以指定model_id来查看某一具体模型的信息。
SHOW MODELS <model_id> -- 只展示特定模型模型展示的结果中包含如下内容:
| ModelId | ModelType | Category | State |
|---|---|---|---|
| 模型ID | 模型类型 | 模型种类 | 模型状态 |
其中,State 模型状态机流转示意图如下:
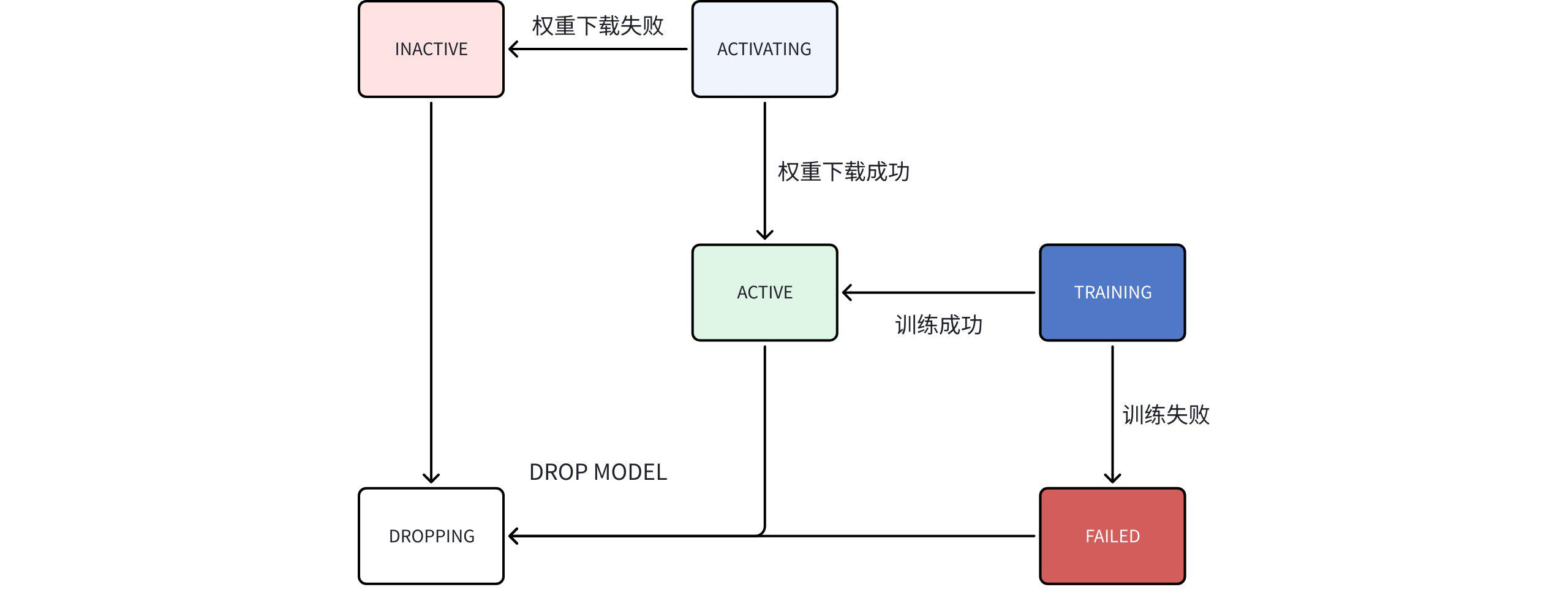
状态机流程说明:
- 启动 AINode 后,执行
show models命令,仅能查看到系统内置(BUILTIN)的模型。 - 用户可导入自己的模型,这类模型的来源标识为用户自定义(USER_****DEFINED);AINode 会尝试从模型配置文件中解析模型类型(ModelType),若解析失败,该字段则显示为空。
- 时序大模型(内置模型)权重文件不随 AINode 打包,AINode 启动时自动下载。
- 下载过程中为 ACTIVATING,下载成功转变为 ACTIVE,失败则变成 INACTIVE。
- 用户启动模型微调任务后,正在训练的模型状态为 TRAINING,训练成功变为 ACTIVE,失败则是 FAILED。
- 若微调任务成功,微调结束后会统计所有 ckpt (训练文件)中指标最佳的文件并自动重命名,变成用户指定的 model_id。
查看示例
IoTDB> show models
+---------------------+--------------+--------------+-------------+
| ModelId| ModelType| Category| State|
+---------------------+--------------+--------------+-------------+
| arima| sktime| builtin| active|
| holtwinters| sktime| builtin| active|
|exponential_smoothing| sktime| builtin| active|
| naive_forecaster| sktime| builtin| active|
| stl_forecaster| sktime| builtin| active|
| gaussian_hmm| sktime| builtin| active|
| gmm_hmm| sktime| builtin| active|
| stray| sktime| builtin| active|
| custom| | user_defined| active|
| timer_xl| timer| builtin| activating|
| sundial| sundial| builtin| active|
| sundialx_1| sundial| fine_tuned| active|
| sundialx_4| sundial| fine_tuned| training|
| sundialx_5| sundial| fine_tuned| failed|
| chronos2| t5| builtin| inactive|
+---------------------+--------------+--------------+-------------+内置传统时序模型介绍如下:
| 模型名称 | 核心概念 | 适用场景 | 主要特点 |
|---|---|---|---|
| ARIMA(自回归整合移动平均模型) | 结合自回归(AR)、差分(I)和移动平均(MA),用于预测平稳时间序列或可通过差分变为平稳的数据。 | 单变量时间序列预测,如股票价格、销量、经济指标等。 | 1. 适用于线性趋势和季节性较弱的数据。2. 需要选择参数 (p,d,q)。3. 对缺失值敏感。 |
| Holt-Winters(三参数指数平滑) | 基于指数平滑,引入水平、趋势和季节性三个分量,适用于具有趋势和季节性的数据。 | 有明显季节性和趋势的时间序列,如月度销售额、电力需求等。 | 1. 可处理加性或乘性季节性。2. 对近期数据赋予更高权重。3. 简单易实现。 |
| Exponential Smoothing(指数平滑) | 通过加权平均历史数据,权重随时间指数递减,强调近期观测值的重要性。 | 无显著季节性但存在趋势的数据,如短期需求预测。 | 1. 参数少,计算简单。2. 适合平稳或缓慢变化序列。3. 可扩展为双指数或三指数平滑。 |
| Naive Forecaster(朴素预测器) | 使用最近一期的观测值作为下一期的预测值,是最简单的基准模型。 | 作为其他模型的比较基准,或数据无明显模式时的简单预测。 | 1. 无需训练。2. 对突发变化敏感。3. 季节性朴素变体可用前一季节同期值预测。 |
| STL Forecaster(季节趋势分解预测) | 基于STL分解时间序列,分别预测趋势、季节性和残差分量后组合。 | 具有复杂季节性、趋势和非线性模式的数据,如气候数据、交通流量。 | 1. 能处理非固定季节性。2. 对异常值稳健。3. 分解后可结合其他模型预测各分量。 |
| Gaussian HMM(高斯隐马尔可夫模型) | 假设观测数据由隐藏状态生成,每个状态的观测概率服从高斯分布。 | 状态序列预测或分类,如语音识别、金融状态识别。 | 1. 适用于时序数据的状态建模。2. 假设观测值在给定状态下独立。3. 需指定隐藏状态数量。 |
| GMM HMM (高斯混合隐马尔可夫模型) | 扩展Gaussian HMM,每个状态的观测概率由高斯混合模型描述,可捕捉更复杂的观测分布。 | 需要多模态观测分布的场景,如复杂动作识别、生物信号分析。 | 1. 比单一高斯更灵活。2. 参数更多,计算复杂度高。3. 需训练GMM成分数。 |
| STRAY(基于奇异值的异常检测) | 通过奇异值分解(SVD)检测高维数据中的异常点,常用于时间序列异常检测。 | 高维时间序列的异常检测,如传感器网络、IT系统监控。 | 1. 无需分布假设。2. 可处理高维数据。3. 对全局异常敏感,局部异常可能漏检。 |
内置时序大模型介绍如下:
| 模型名称 | 核心概念 | 适用场景 | 主要特点 |
|---|---|---|---|
| Timer-XL | 支持超长上下文的时序大模型,通过大规模工业数据预训练增强泛化能力。 | 需利用极长历史数据的复杂工业预测,如能源、航空航天、交通等领域。 | 1. 超长上下文支持,可处理数万时间点输入。2. 多场景覆盖,支持非平稳、多变量及协变量预测。3. 基于万亿级高质量工业时序数据预训练。 |
| Timer-Sundial | 采用“Transformer + TimeFlow”架构的生成式基础模型,专注于概率预测。 | 需要量化不确定性的零样本预测场景,如金融、供应链、新能源发电预测。 | 1. 强大的零样本泛化能力,支持点预测与概率预测 2. 可灵活分析预测分布的任意统计特性。3. 创新生成架构,实现高效的非确定性样本生成。 |
| Chronos-2 | 基于离散词元化范式的通用时序基础模型,将预测转化为语言建模任务。 | 快速零样本单变量预测,以及可借助协变量(如促销、天气)提升效果的场景。 | 1. 强大的零样本概率预测能力。2. 支持协变量统一建模,但对输入有严格要求:a. 未来协变量的名称组成的集合必须是历史协变量的名称组成的集合的子集;b. 每个历史协变量的长度必须等于目标变量的长度; c. 每个未来协变量的长度必须等于预测长度;3. 采用高效的编码器式结构,兼顾性能与推理速度。 |
4.5 删除模型
对于注册成功的模型,用户可以通过 SQL 进行删除,AINode 会将 user_defined 目录下的对应模型文件夹整个删除。其 SQL 语法如下:
DROP MODEL <model_id>需要指定已经成功注册的模型 model_id 来删除对应的模型。由于模型删除涉及模型数据清理,操作不会立即完成,此时模型的状态为 DROPPING,该状态的模型不能用于模型推理。请注意,该功能不支持删除内置模型。
4.6 加载/卸载模型
为适应不同场景,AINode 提供以下两种模型加载策略:
- 即时加载:即推理时临时加载模型,结束后释放资源。适用于测试或低负载场景。
- 常驻加载:即将模型持久化加载在内存(CPU)或显存(GPU)中,以支持高并发推理。用户只需通过 SQL 指定加载或卸载的模型,AINode 会自动管理实例数量。当前常驻模型的状态也可随时查看。
下文将详细介绍加载/卸载模型的相关内容:
- 配置参数
支持通过编辑如下配置项设置常驻加载相关参数。
# AINode 在推理时可使用的设备内存/显存占总量的比例
# Datatype: Float
ain_inference_memory_usage_ratio=0.4
# AINode 每个加载的模型实例需要占用的内存比例,即模型占用*该值
# Datatype: Float
ain_inference_extra_memory_ratio=1.2- 展示可用的 device
支持通过如下 SQL 命令查看所有可用的设备 ID
SHOW AI_DEVICES示例
IoTDB> show ai_devices
+-------------+
| DeviceId|
+-------------+
| cpu|
| 0|
| 1|
+-------------+- 加载模型
支持通过如下 SQL 命令手动加载模型,系统根据硬件资源使用情况自动均衡模型实例数量。
LOAD MODEL <existing_model_id> TO DEVICES <device_id>(, <device_id>)*参数要求
- existing_model_id: 指定的模型 id,当前版本仅支持 timer_xl 和 sundial。
- device_id: 模型加载的位置。
- cpu: 加载到 AINode 所在服务器的内存中。
- gpu_id: 加载到 AINode 所在服务器的对应显卡中,如 "0, 1" 表示加载到编号为 0 和 1 的两张显卡中。
示例
LOAD MODEL sundial TO DEVICES 'cpu,0,1'- 卸载模型
支持通过如下 SQL 命令手动卸载指定模型的所有实例,系统会重分配空闲出的资源给其他模型
UNLOAD MODEL <existing_model_id> FROM DEVICES <device_id>(, <device_id>)*参数要求
- existing_model_id: 指定的模型 id,当前版本仅支持 timer_xl 和 sundial。
- device_id: 模型加载的位置。
- cpu: 尝试从 AINode 所在服务器的内存中卸载指定模型。
- gpu_id: 尝试从 AINode 所在服务器的对应显卡中卸载指定模型,如 "0, 1" 表示尝试从编号为 0 和 1 的两张显卡卸载指定模型。
示例
UNLOAD MODEL sundial FROM DEVICES 'cpu,0,1'- 展示加载的模型
支持通过如下 SQL 命令查看已经手动加载的模型实例,可通过 device_id 指定设备。
SHOW LOADED MODELS
SHOW LOADED MODELS <device_id>(, <device_id>)* # 展示指定设备中的模型实例示例:在内存、gpu_0 和 gpu_1 两张显卡加载了sundial 模型
IoTDB> show loaded models
+-------------+--------------+------------------+
| DeviceId| ModelId| Count(instances)|
+-------------+--------------+------------------+
| cpu| sundial| 4|
| 0| sundial| 6|
| 1| sundial| 6|
+-------------+--------------+------------------+说明:
- DeviceId : 设备 ID
- ModelId :加载的模型 ID
- Count(instances) :每个设备中的模型实例数量(系统自动分配)
4.7 时序大模型介绍
AINode 目前支持多种时序大模型,相关介绍及部署使用可参考时序大模型
5. 权限管理
使用 AINode 相关的功能时,可以使用IoTDB本身的鉴权去做一个权限管理,用户只有在具备 USE_MODEL 权限时,才可以使用模型管理的相关功能。当使用推理功能时,用户需要有访问输入模型的 SQL 对应的源序列的权限。
| 权限名称 | 权限范围 | 管理员用户(默认ROOT) | 普通用户 |
|---|---|---|---|
| USE_MODEL | create model / show models / drop model | √ | √ |
| READ_SCHEMA&READ_DATA | forecast | √ | √ |