
AINode
AINode
AINode 是支持时序相关模型注册、管理、调用的 IoTDB 原生节点,内置业界领先的自研时序大模型,如清华自研时序模型 Timer 系列,可通过标准 SQL 语句进行调用,实现时序数据的毫秒级实时推理,可支持时序趋势预测、缺失值填补、异常值检测等应用场景。
V2.0.5.1及以后版本支持
系统架构如下图所示:
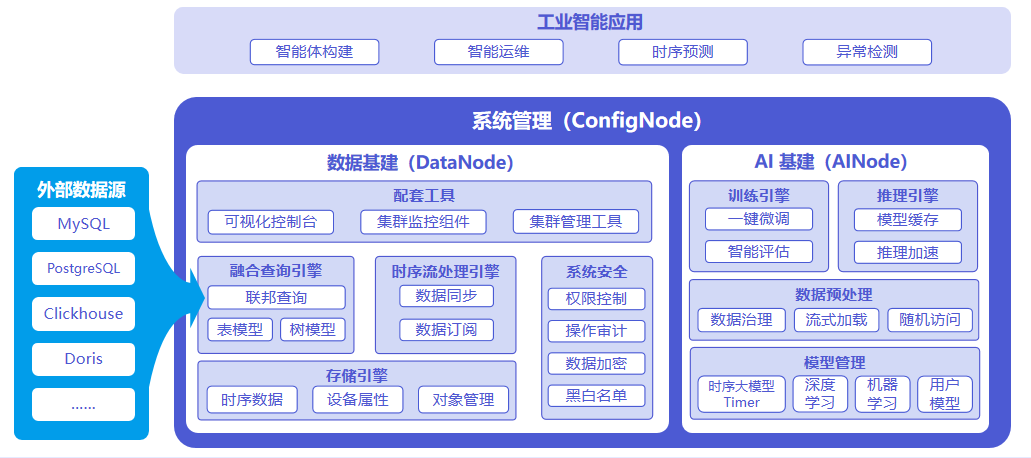
三种节点的职责如下:
- ConfigNode:负责分布式节点管理和负载均衡。
- DataNode:负责接收并解析用户的 SQL请求;负责存储时间序列数据;负责数据的预处理计算。
- AINode:负责时序模型的管理和使用。
1. 优势特点
与单独构建机器学习服务相比,具有以下优势:
简单易用:无需使用 Python 或 Java 编程,使用 SQL 语句即可完成机器学习模型管理与推理的完整流程。如创建模型可使用CREATE MODEL语句、使用模型进行推理可使用 SELECT * FROM FORECAST (...) 语句等,使用更加简单便捷。
避免数据迁移:使用 IoTDB 原生机器学习可以将存储在 IoTDB 中的数据直接应用于机器学习模型的推理,无需将数据移动到单独的机器学习服务平台,从而加速数据处理、提高安全性并降低成本。

- 内置先进算法:支持业内领先机器学习分析算法,覆盖典型时序分析任务,为时序数据库赋能原生数据分析能力。如:
- 时间序列预测(Time Series Forecasting):从过去时间序列中学习变化模式;从而根据给定过去时间的观测值,输出未来序列最可能的预测。
- 时序异常检测(Anomaly Detection for Time Series):在给定的时间序列数据中检测和识别异常值,帮助发现时间序列中的异常行为。
- 时间序列标注(Time Series Annotation):为每个数据点或特定时间段添加额外的信息或标记,例如事件发生、异常点、趋势变化等,以便更好地理解和分析数据。
2. 基本概念
- 模型(Model):机器学习模型,以时序数据作为输入,输出分析任务的结果或决策。模型是 AINode 的基本管理单元,支持模型的增(注册)、删、查、改(微调)、用(推理)。
- 创建(Create): 将外部设计或训练好的模型文件或算法加载到 AINode 中,由 IoTDB 统一管理与使用。
- 推理(Inference):使用创建的模型在指定时序数据上完成该模型适用的时序分析任务。
- 内置能力(Built-in):AINode 自带常见时序分析场景(例如预测与异常检测)的机器学习算法或自研模型。
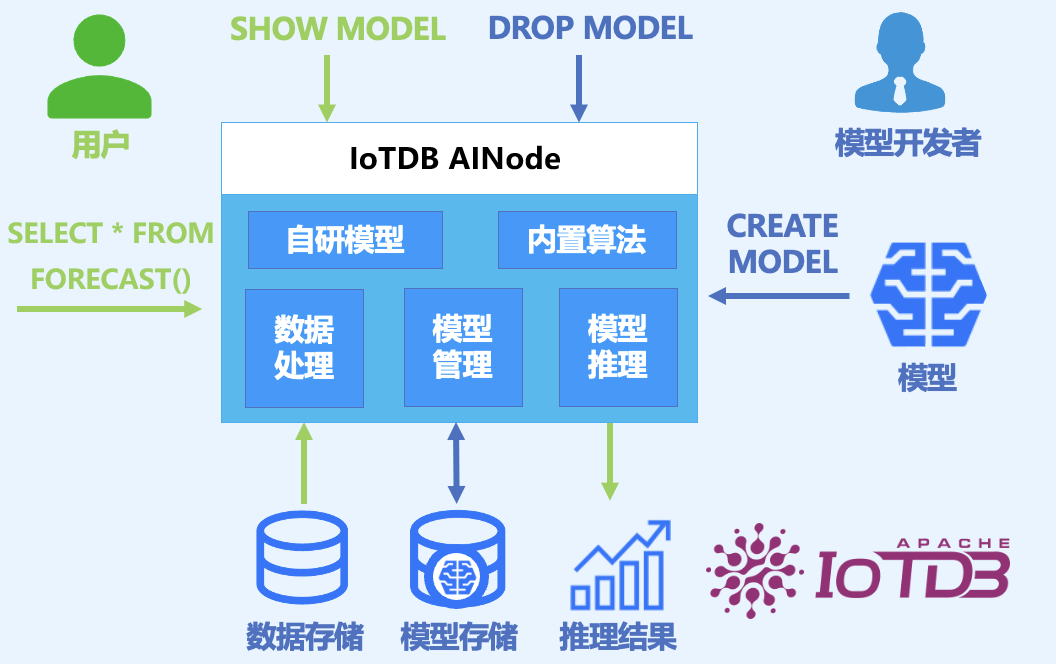
3. 安装部署
AINode 的部署可参考文档 AINode 部署 章节。
4. 使用指导
AINode 对时序模型提供了模型创建及删除功能,内置模型无需创建,可直接使用。
4.1 注册模型
通过指定模型输入输出的向量维度,可以注册训练好的深度学习模型,从而用于模型推理。
符合以下内容的模型可以注册到AINode中:
- AINode 目前支持基于 PyTorch 2.4.0 版本训练的模型,需避免使用 2.4.0 版本以上的特性。
- AINode 支持使用 PyTorch JIT 存储的模型(
model.pt),模型文件需要包含模型的结构和权重。 - 模型输入序列可以包含一列或多列,若有多列,需要和模型能力、模型配置文件对应。
- 模型的配置参数必须在
config.yaml配置文件中明确定义。使用模型时,必须严格按照config.yaml配置文件中定义的输入输出维度。如果输入输出列数不匹配配置文件,将会导致错误。
下方为模型注册的SQL语法定义。
create model <model_id> using uri <uri>SQL中参数的具体含义如下:
model_id:模型的全局唯一标识,不可重复。模型名称具备以下约束:
- 允许出现标识符 [ 0-9 a-z A-Z _ ](字母,数字(非开头),下划线(非开头))
- 长度限制为2-64字符
- 大小写敏感
uri:模型注册文件的资源路径,路径下应包含模型结构及权重文件 model.pt 文件和模型配置文件 config.yaml
模型结构及权重文件:模型训练完成后得到的权重文件,目前支持 pytorch 训练得到的 .pt 文件
模型配置文件:模型注册时需要提供的与模型结构有关的参数,其中必须包含模型的输入输出维度用于模型推理:
参数名 参数描述 示例 input_shape 模型输入的行列,用于模型推理 [96,2] output_shape 模型输出的行列,用于模型推理 [48,2] 除了模型推理外,还可以指定模型输入输出的数据类型:
参数名 参数描述 示例 input_type 模型输入的数据类型 ['float32','float32'] output_type 模型输出的数据类型 ['float32','float32'] 除此之外,可以额外指定备注信息用于在模型管理时进行展示
参数名 参数描述 示例 attributes 可选,用户自行设定的模型备注信息,用于模型展示 'model_type': 'dlinear','kernel_size': '25'
除了本地模型文件的注册,还可以通过URI来指定远程资源路径来进行注册,使用开源的模型仓库(例如HuggingFace)。
示例
在 example 文件夹下,包含model.pt和config.yaml文件,model.pt为训练得到,config.yaml的内容如下:
configs:
# 必选项
input_shape: [96, 2] # 表示模型接收的数据为96行x2列
output_shape: [48, 2] # 表示模型输出的数据为48行x2列
# 可选项 默认为全部float32,列数为shape对应的列数
input_type: ["int64","int64"] #输入对应的数据类型,需要与输入列数匹配
output_type: ["text","int64"] #输出对应的数据类型,需要与输出列数匹配
attributes: # 可选项 为用户自定义的备注信息
'model_type': 'dlinear'
'kernel_size': '25'指定该文件夹作为加载路径就可以注册该模型
IoTDB> create model dlinear_example using uri "file://./example"SQL执行后会异步进行注册的流程,可以通过模型展示查看模型的注册状态(见模型展示章节),注册成功的耗时主要受到模型文件大小的影响。
模型注册完成后,就可以通过使用正常查询的方式调用具体函数,进行模型推理。
4.2 查看模型
注册成功的模型可以通过show models指令查询模型的具体信息。其SQL定义如下:
show models
show models <model_id>除了直接展示所有模型的信息外,可以指定model id来查看某一具体模型的信息。模型展示的结果中包含如下信息:
| ModelId | ModelType | Category | State |
|---|---|---|---|
| 模型ID | 模型类型 | 模型种类 | 模型状态 |
- 模型状态机流转示意图如下
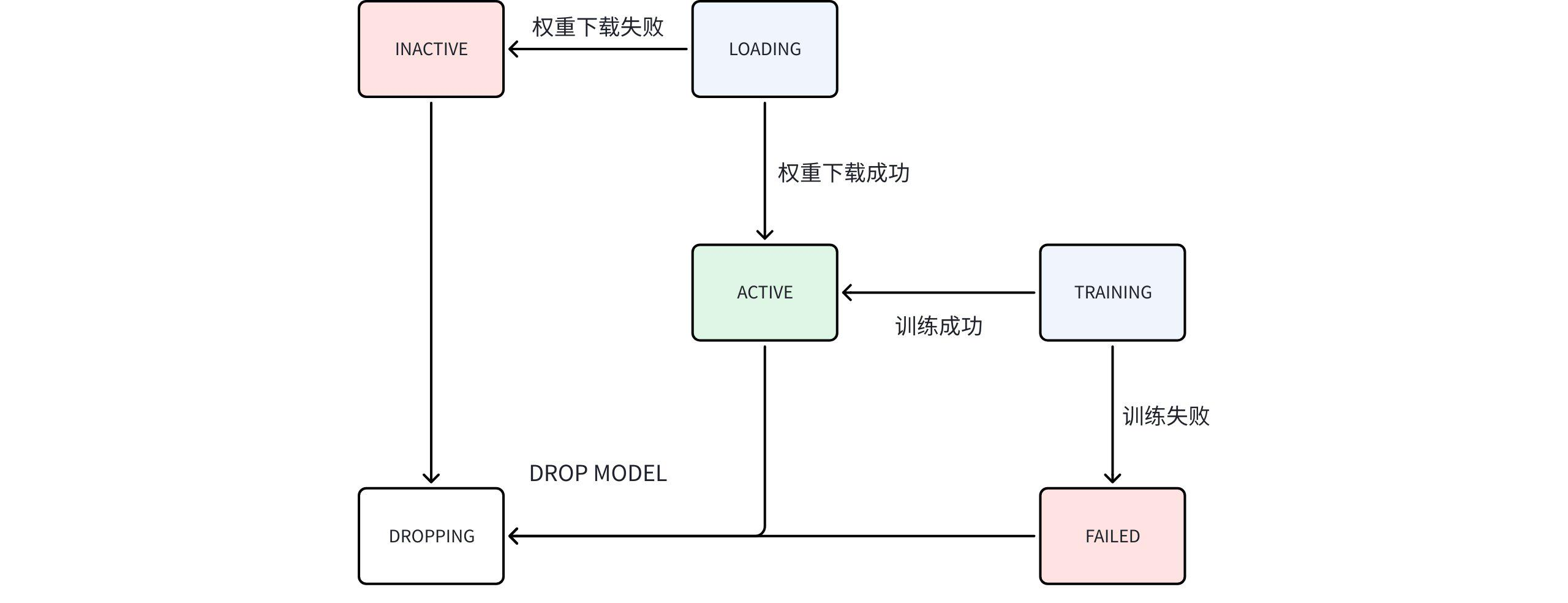
说明:
- 启动 AINode,show models 只能看到 BUILT-IN 模型
- 用户可导入自己的模型,来源为 USER-DEFINED,可尝试从配置文件解析 ModelType,解析不到则为空
- 时序大模型权重不随 AINode 打包,AINode 启动时自动下载,下载过程中为 LOADING
- 下载成功转变为 ACTIVE,失败则变成 INACTIVE
- 用户启动微调,正在训练的模型状态为 TRAINING,训练成功变为 ACTIVE,失败则是 FAILED
示例
IoTDB> show models
+---------------------+--------------------+--------------+---------+
| ModelId| ModelType| Category| State|
+---------------------+--------------------+--------------+---------+
| arima| Arima| BUILT-IN| ACTIVE|
| holtwinters| HoltWinters| BUILT-IN| ACTIVE|
|exponential_smoothing|ExponentialSmoothing| BUILT-IN| ACTIVE|
| naive_forecaster| NaiveForecaster| BUILT-IN| ACTIVE|
| stl_forecaster| StlForecaster| BUILT-IN| ACTIVE|
| gaussian_hmm| GaussianHmm| BUILT-IN| ACTIVE|
| gmm_hmm| GmmHmm| BUILT-IN| ACTIVE|
| stray| Stray| BUILT-IN| ACTIVE|
| custom| | USER-DEFINED| ACTIVE|
| timerxl| Timer-XL| BUILT-IN| LOADING|
| sundial| Timer-Sundial| BUILT-IN| ACTIVE|
| sundialx_1| Timer-Sundial| FINE-TUNED| ACTIVE|
| sundialx_2| Timer-Sundial| FINE-TUNED| ACTIVE|
| sundialx| Timer-Sundial| FINE-TUNED| ACTIVE|
| sundialx_4| Timer-Sundial| FINE-TUNED| TRAINING|
| sundialx_5| Timer-Sundial| FINE-TUNED| FAILED|
+---------------------+--------------------+--------------+---------+4.3 删除模型
对于注册成功的模型,用户可以通过SQL进行删除,该操作会删除所有 AINode 下的相关模型文件,其SQL如下:
drop model <model_id>需要指定已经成功注册的模型 model_id 来删除对应的模型。由于模型删除涉及模型数据清理,操作不会立即完成,此时模型的状态为 DROPPING,该状态的模型不能用于模型推理。请注意,该功能不支持删除内置模型。
4.4 使用内置模型推理
SQL语法如下:
SELECT * FROM forecast(
input,
model_id,
[output_length,
output_start_time,
output_interval,
timecol,
preserve_input,
model_options]?
)内置模型推理无需注册流程,通过 forecast 函数,指定 model_id 就可以使用模型的推理功能
请注意,使用内置时序大模型进行推理的前提条件是本地存有对应模型权重,目录为 /IOTDB_AINODE_HOME/data/ainode/models/weights/model_id/。若本地没有模型权重,则会自动从 HuggingFace 拉取,请保证本地能直接访问 HuggingFace。
参数介绍如下:
| 参数名 | 参数类型 | 参数属性 | 描述 | 是否必填 | 备注 |
|---|---|---|---|---|---|
| input | 表参数 | SET SEMANTIC | 待预测的输入数据 | 是 | |
| model_id | 标量参数 | 字符串类型 | 需要选择的model名 | 是 | 只能为非空,且内置的模型,否则报错:空字符串:MODEL_ID should never be null or empty不存在的模型:model [%s] has not been created模型不可用:model [%s] is not available |
| output_length | 标量参数 | INT32类型默认值:96 | 输出窗口大小 | 否 | 必须大于 0,否则报错:OUTPUT_LENGTH should be greater than 0 |
| output_start_time | 标量参数 | 时间戳类型默认值:输入数据的最后一个时间戳加 output_interval | 输出的预测点的起始时间戳 | 否 | 可以为负数,表示1970年1月1号之前的时间戳 |
| output_interval | 标量参数 | 时间间隔类型默认值:0(输入数据的采样间隔) | 输出的预测点之间的时间间隔支持的单位是 ns、us、ms、s、m、h、d、w | 否 | 大于 0 时,采用用户指定的输出间隔;小于等于 0 时,根据输入数据自动推测 |
| timecol | 标量参数 | 字符串类型默认值:time | 时间列名 | 否 | 存在于 input 中的,数据类型为 TIMESTAMP 的列,否则报错:若数据类型不为 TIMESTAMP: The type of the column [%s] is not as expected.若列不存在:Required column [%s] not found in the source table argument. |
| preserve_input | 标量参数 | 布尔类型默认值:false | 是否在输出结果集中保留输入的所有原始行 | 否 | |
| model_options | 标量参数 | 字符串类型默认值:空字符串 | 模型相关的key-value对,比如是否需要对输入进行归一化等。不同的key-value对以';'间隔 | 否 | 指定某个模型不支持参数,并不会报错,只会被忽略;AINode 中内置的模型支持的常见参数详见文末附录说明。 |
说明:
- forecast 函数默认对输入表中所有列进行预测(不包含time列和partition by 的列)。
- forecast 函数对于输入数据无顺序性要求,默认对输入数据按照时间戳(由 TIMECOL 参数指定时间戳的列名)做升序排序后,再调用模型进行预测。
- 不同模型对于输入数据的行数要求不同,输入数据少于最低行数要求时会报错。
- 在当前的 AINdoe 内置模型中,Timer-XL 模型至少需要输入 96 行数据,Timer-Sundial 模型至少需要输入 16 行数据。
- forecast 函数的返回结果列包含 input 表的所有输入列,列的数据类型与原表列的数据类型一致。若 preserve_input= true,则还包含 is_input 列(表征当前行是否为输入行)
- 目前只支持对 INT32、INT64、FLOAT、DOUBLE 进行预测,否则报错:The type of the column [%s] is [%s], only INT32, INT64, FLOAT, DOUBLE is allowed
- output_start_time 和 output_interval 只会影响输出结果集的时间戳列生成,均为可选参数。
- output_start_time 默认为输入数据的最后一个时间戳加 output_interval
- output_interval = (输入数据的最后一个时间戳 - 输入数据的第一个时间戳) / n - 1, 默认为输入数据的采样间隔
- 第 N 个输出行的时间为 output_start_time + (N - 1) * output_interval
示例:需要提前创建数据库及表
create database etth
create table eg (hufl FLOAT FIELD, hull FLOAT FIELD, mufl FLOAT FIELD, mull FLOAT FIELD, lufl FLOAT FIELD, lull FLOAT FIELD, ot FLOAT FIELD)我们所使用的的测试集的数据为ETTh1-tab。
查看当前支持的模型
IoTDB:etth> show models
+---------------------+--------------------+--------+------+
| ModelId| ModelType|Category| State|
+---------------------+--------------------+--------+------+
| arima| Arima|BUILT-IN|ACTIVE|
| holtwinters| HoltWinters|BUILT-IN|ACTIVE|
|exponential_smoothing|ExponentialSmoothing|BUILT-IN|ACTIVE|
| naive_forecaster| NaiveForecaster|BUILT-IN|ACTIVE|
| stl_forecaster| StlForecaster|BUILT-IN|ACTIVE|
| gaussian_hmm| GaussianHmm|BUILT-IN|ACTIVE|
| gmm_hmm| GmmHmm|BUILT-IN|ACTIVE|
| stray| Stray|BUILT-IN|ACTIVE|
| sundial| Timer-Sundial|BUILT-IN|ACTIVE|
| timer_xl| Timer-XL|BUILT-IN|ACTIVE|
+---------------------+--------------------+--------+------+
Total line number = 10
It costs 0.004s表模型推理(以 sundial 为例)
IoTDB:etth> select Time, HUFL,HULL,MUFL,MULL,LUFL,LULL,OT from eg LIMIT 96
+-----------------------------+------+-----+-----+-----+-----+-----+------+
| Time| HUFL| HULL| MUFL| MULL| LUFL| LULL| OT|
+-----------------------------+------+-----+-----+-----+-----+-----+------+
|2016-07-01T00:00:00.000+08:00| 5.827|2.009|1.599|0.462|4.203| 1.34|30.531|
|2016-07-01T01:00:00.000+08:00| 5.693|2.076|1.492|0.426|4.142|1.371|27.787|
|2016-07-01T02:00:00.000+08:00| 5.157|1.741|1.279|0.355|3.777|1.218|27.787|
|2016-07-01T03:00:00.000+08:00| 5.09|1.942|1.279|0.391|3.807|1.279|25.044|
......
Total line number = 96
It costs 0.119s
IoTDB:etth> select * from forecast(
model_id => 'sundial',
input => (select Time, ot from etth.eg where time >= 2016-08-07T18:00:00.000+08:00 limit 1440) order BY time,
output_length => 96
)
+-----------------------------+---------+
| time| ot|
+-----------------------------+---------+
|2016-10-06T18:00:00.000+08:00|20.781654|
|2016-10-06T19:00:00.000+08:00|20.252121|
|2016-10-06T20:00:00.000+08:00|19.960138|
|2016-10-06T21:00:00.000+08:00|19.662334|
......
Total line number = 96
It costs 1.615s4.5 使用内置模型微调
仅 Timer-XL、Timer-Sundial 可以进行微调操作。
SQL语法如下:
create model <model_id> (with hyperparameters
(<parameterName>=<parameterValue>(, <parameterName>=<parameterValue>)*))?
from model <existing_model_id>
on dataset (inputSql)示例
- 选择测点 ot 中前 80% 数据作为微调数据集,基于 sundial 创建模型 sundialv3。
IoTDB> set sql_dialect=table
Msg: The statement is executed successfully.
IoTDB> CREATE MODEL sundialv3 FROM MODEL sundial ON DATASET ('SELECT time, ot from etth.eg where 1467302400000 <= time and time < 1517468400001')
Msg: The statement is executed successfully.
IoTDB> show models
+---------------------+--------------------+----------+--------+
| ModelId| ModelType| Category| State|
+---------------------+--------------------+----------+--------+
| arima| Arima| BUILT-IN| ACTIVE|
| holtwinters| HoltWinters| BUILT-IN| ACTIVE|
|exponential_smoothing|ExponentialSmoothing| BUILT-IN| ACTIVE|
| naive_forecaster| NaiveForecaster| BUILT-IN| ACTIVE|
| stl_forecaster| StlForecaster| BUILT-IN| ACTIVE|
| gaussian_hmm| GaussianHmm| BUILT-IN| ACTIVE|
| gmm_hmm| GmmHmm| BUILT-IN| ACTIVE|
| stray| Stray| BUILT-IN| ACTIVE|
| sundial| Timer-Sundial| BUILT-IN| ACTIVE|
| timer_xl| Timer-XL| BUILT-IN| ACTIVE|
| sundialv2| Timer-Sundial|FINE-TUNED| ACTIVE|
| sundialv3| Timer-Sundial|FINE-TUNED|TRAINING|
+---------------------+--------------------+----------+--------+- 微调任务后台异步启动,可在 AINode 进程看到 log;微调完成后,查询并使用新的模型
IoTDB> show models
+---------------------+--------------------+----------+------+
| ModelId| ModelType| Category| State|
+---------------------+--------------------+----------+------+
| arima| Arima| BUILT-IN|ACTIVE|
| holtwinters| HoltWinters| BUILT-IN|ACTIVE|
|exponential_smoothing|ExponentialSmoothing| BUILT-IN|ACTIVE|
| naive_forecaster| NaiveForecaster| BUILT-IN|ACTIVE|
| stl_forecaster| StlForecaster| BUILT-IN|ACTIVE|
| gaussian_hmm| GaussianHmm| BUILT-IN|ACTIVE|
| gmm_hmm| GmmHmm| BUILT-IN|ACTIVE|
| stray| Stray| BUILT-IN|ACTIVE|
| sundial| Timer-Sundial| BUILT-IN|ACTIVE|
| timer_xl| Timer-XL| BUILT-IN|ACTIVE|
| sundialv2| Timer-Sundial|FINE-TUNED|ACTIVE|
| sundialv3| Timer-Sundial|FINE-TUNED|ACTIVE|
+---------------------+--------------------+----------+------+4.6 时序大模型导入步骤
AINode 目前支持多种时序大模型,部署使用请参考时序大模型
5 权限管理
使用AINode相关的功能时,可以使用IoTDB本身的鉴权去做一个权限管理,用户只有在具备 USE_MODEL 权限时,才可以使用模型管理的相关功能。当使用推理功能时,用户需要有访问输入模型的SQL对应的源序列的权限。
| 权限名称 | 权限范围 | 管理员用户(默认ROOT) | 普通用户 | 路径相关 |
|---|---|---|---|---|
| USE_MODEL | create model / show models / drop model | √ | √ | x |
| READ_DATA | call inference | √ | √ | √ |
6 附录
Arima
| 支持的参数 | 含义 | 默认值 |
|---|---|---|
| order | ARIMA模型的阶数 (p, d, q):p是自回归阶数,d是差分阶数,q是滑动平均阶数。 | (1,0,0) |
| seansonal_order | 季节性ARIMA的阶数 (P, D, Q, s):分别为季节性自回归、差分、滑动平均阶数,s是季节周期(如12代表月度数据)。 | (0,0,0,0) |
| method | 优化器选择,可选:'newton'、'nm'、'bfgs'、'lbfgs'、'powell'、'cg'、'ncg'、'basinhopping'。 | 'lbfgs' |
| maxiter | 最大迭代次数或函数评估次数。 | 50 |
| out_of_sample_size | 用于验证的时间序列尾部样本数,模型不在这些样本上拟合。 | 0 |
| scoring | 验证时使用的评分函数,字符串需为 sklearn 中可导入的评分指标,或用户自定义函数。 | 'mse' |
| trend | 趋势项配置,若 with_intercept=True 且此项为 None,则默认使用 'c'(包含常数项)。 | None |
| with_intercept | 是否包含截距项。 | True |
| time_varying_regression | 是否允许回归系数随时间变化。 | False |
| enforce_stationarity | 是否强制AR部分平稳性。 | True |
| enforce_invertibility | 是否强制MA部分可逆性。 | True |
| simple_differnecing | 是否使用差分后的数据估计(牺牲前几行数据换取更简状态空间)。 | False |
| measurement_error | 是否认为观测值中含有误差。 | False |
| mle_regression | 是否使用极大似然估计回归系数,若 time_varying_regression=True 则必须为 False。 | True |
| hamilton_representation | 是否使用 Hamilton 表达方式(默认用 Harvey)。 | False |
| concentrate_scale | 是否从似然函数中排除误差方差参数,减少待估参数个数(但无法获得误差项方差的标准误)。 | False |
NaiveForecaster
| 支持的参数 | 含义 | 默认值 |
|---|---|---|
| strategy | 预测策略: • "last":预测训练集最后一个值;若设置了季节周期(sp>1),则每个季节分别预测其最后一个周期值。对 NaN 值鲁棒。 • "mean":预测最后窗口中的平均值;若 sp>1,按每个季节分别计算均值。对 NaN 值鲁棒。 • "drift":用最后窗口的首尾点拟合一条直线并外推预测。对 NaN 值不鲁棒。 | "last" |
| sp | 季节性周期。若为 None,等效于 1,表示无季节性;如果设为 12,表示每 12 个单位(如月)为一个周期。 | 1 |
- STLForecaster
| 支持的参数 | 含义 | 默认值 |
|---|---|---|
| sp | 季节周期长度(周期性单位数)。传入 statsmodels 的 STL 中。 | 2 |
| seasonal | 季节项平滑窗口长度,必须为 ≥3 的奇数,通常建议 ≥7。 | 7 |
| seasonal_deg | 季节项 LOESS 的多项式阶数(0 表示常数,1 表示线性)。 | 1 |
| trend_deg | 趋势项 LOESS 的多项式阶数(0 或 1)。 | 1 |
| low_pass_deg | 低通项 LOESS 的多项式阶数(0 或 1)。 | 1 |
| seasonal_jump | LOESS 拟合的插值步长(季节项),每 n 点拟合一次,中间插值。值越大,估计速度越快。 | 1 |
| trend_jump | 趋势项插值步长,越大速度越快但精度可能下降。 | 1 |
| low_pass_jump | 低通项插值步长,设置同上。 | 1 |
ExponentialSmoothing (HoltWinters)
| 支持的参数 | 含义 | 默认值 |
|---|---|---|
| damped_trend | 是否使用阻尼趋势(趋势会逐渐平缓,而非无限增长)。 | True |
| initialization_method | 初始化方法: • "estimated":通过拟合估计初始状态 • "heuristic":使用启发式方法估计初始水平/趋势/季节 • "known":用户显式提供所有初始值 • "legacy-heuristic":旧版本兼容方式 | "estimated" |
| optmized | 是否通过最大化对数似然来优化参数。 | True |
| remove_bias | 是否移除偏差,使预测值和拟合值的残差平均值为0。 | False |
| use_brute | 是否使用穷举法(网格搜索)来寻找初始参数。否则使用启发式初始值。 |