

9 月 24 日,“保障数据永不丢失!数据管理实战:分区、同步与备份”直播中,天谋科技时序数据库内核研发工程师,IoTDB 项目交付负责人曹志佳围绕 IoTDB 分区同步和备份相关原理及实践展开,为大家介绍了数据分区对时序数据库的重要性、IoTDB 的分区机制和同步方式,以及流处理框架的应用场景。
此次直播回放可在这里查看,主要内容我们为你总结如下:
01 数据分区的重要性及特征
(1)时序数据背景及特征
随着 IT 和 OT 行业技术的快速迭代,时序数据在工业、能源、军工等众多领域的价值日益凸显,如在 AI 分析、设备预警等场景中发挥着重要作用。
时序数据的特点,一是测点数量巨大,如储能行业大型储能站传感器数量可百万级,全国范围内测点量级能达百亿;汽车行业某品牌在路上行驶车辆的测点量级可达 10 亿以上。二是存储代价大,如钢铁制造行业超大型炼钢装置和新能源发电场景中的风机,数据产生量大且采集频率高,对磁盘需求达 PB 级以上。

(2)数据分区的定义及优势
数据分区的定义为将数据按照一定规则进行切分,形成可独立管理的数据单元。以图书馆管理书籍为例,有数据分区时,按类别将书籍放置在不同书架,管理和查找效率更高。
面对海量的时序数据,传统数据库难以管理,数据分区可提高数据管理和查询效率。

02 IoTDB 的数据分区机制
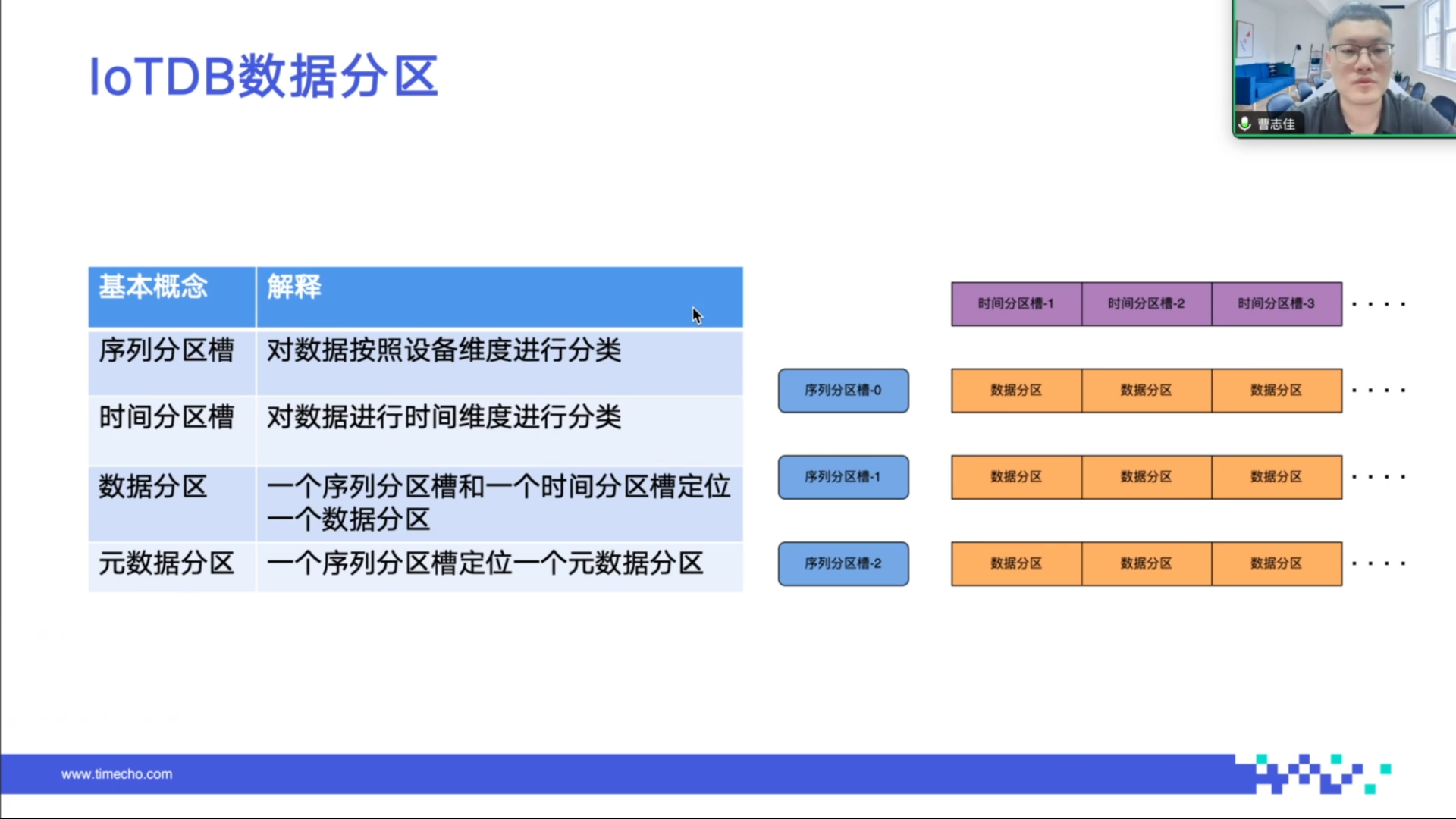
(1)分区维度及概念
IoTDB 的数据分区基于序列和时间两个维度,涉及概念包括序列分区槽和时间分区槽。
序列分区槽是对时间序列的纵向管理机制,默认是数据库级别的,每个数据库持有固定数量(默认 1,000 个)的序列分区槽,通过哈希算法将序列分配到不同槽位,可避免内存映射占用过多问题。
时间分区槽是对时间序列的横向管理机制,将数据按固定时间范围(默认 7 天)切分,可提高数据查询效率。
(2)分区在集群中的分布
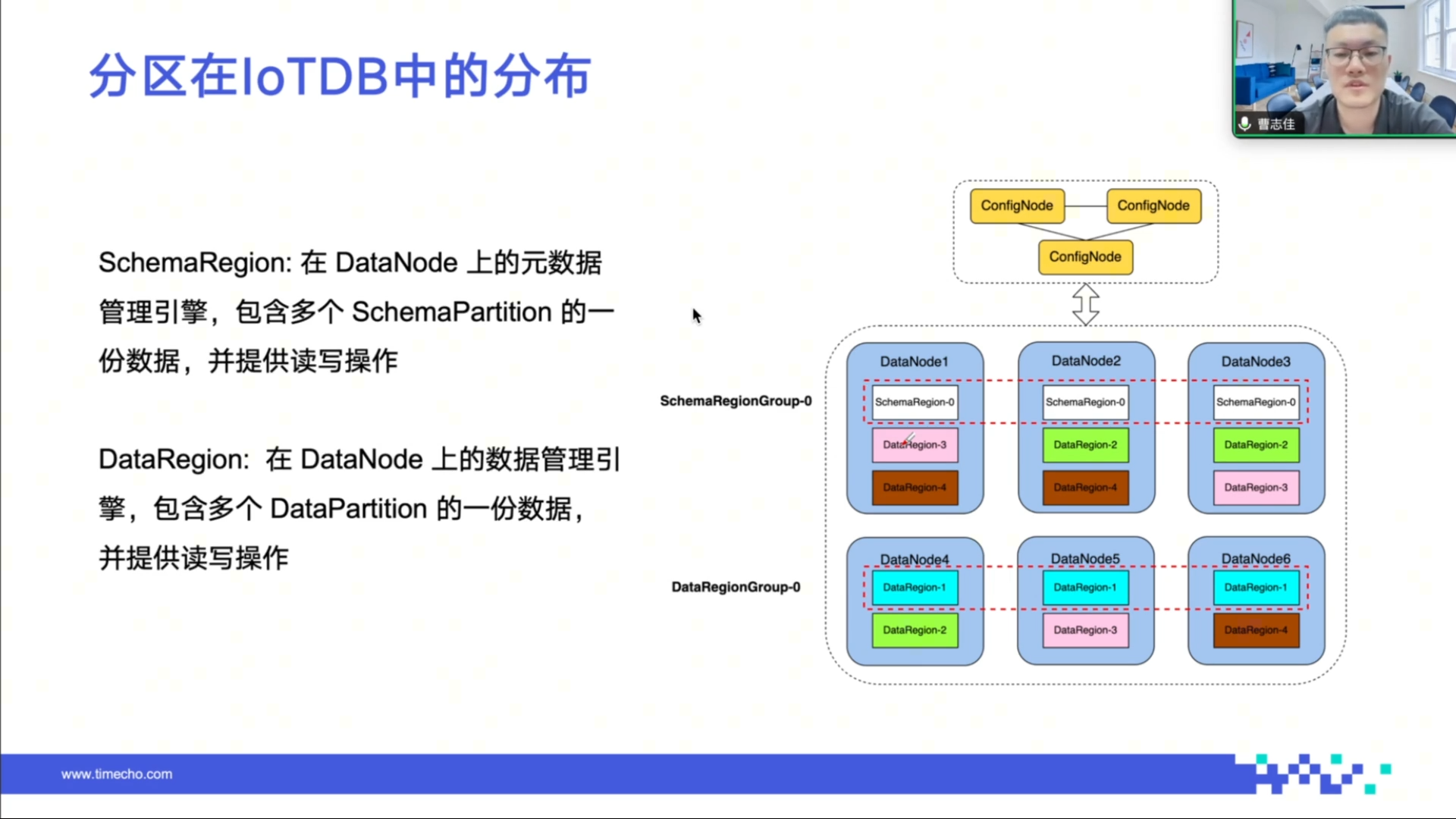
IoTDB 节点分为 ConfigNode 和 DataNode,ConfigNode 是集群的管理者和协调者,DataNode 处理客户的读写请求。
源数据分区和数据分区位于 DataNode 中,每个 DataNode 上存在一个或多个 SchemaRegion 和 DataRegion。IoTDB 集群通过负载均衡算法保证数据分区在不同节点上均匀分布,提高数据存储和写入的均衡性和效率。
(3)读写视角下的分区执行流程
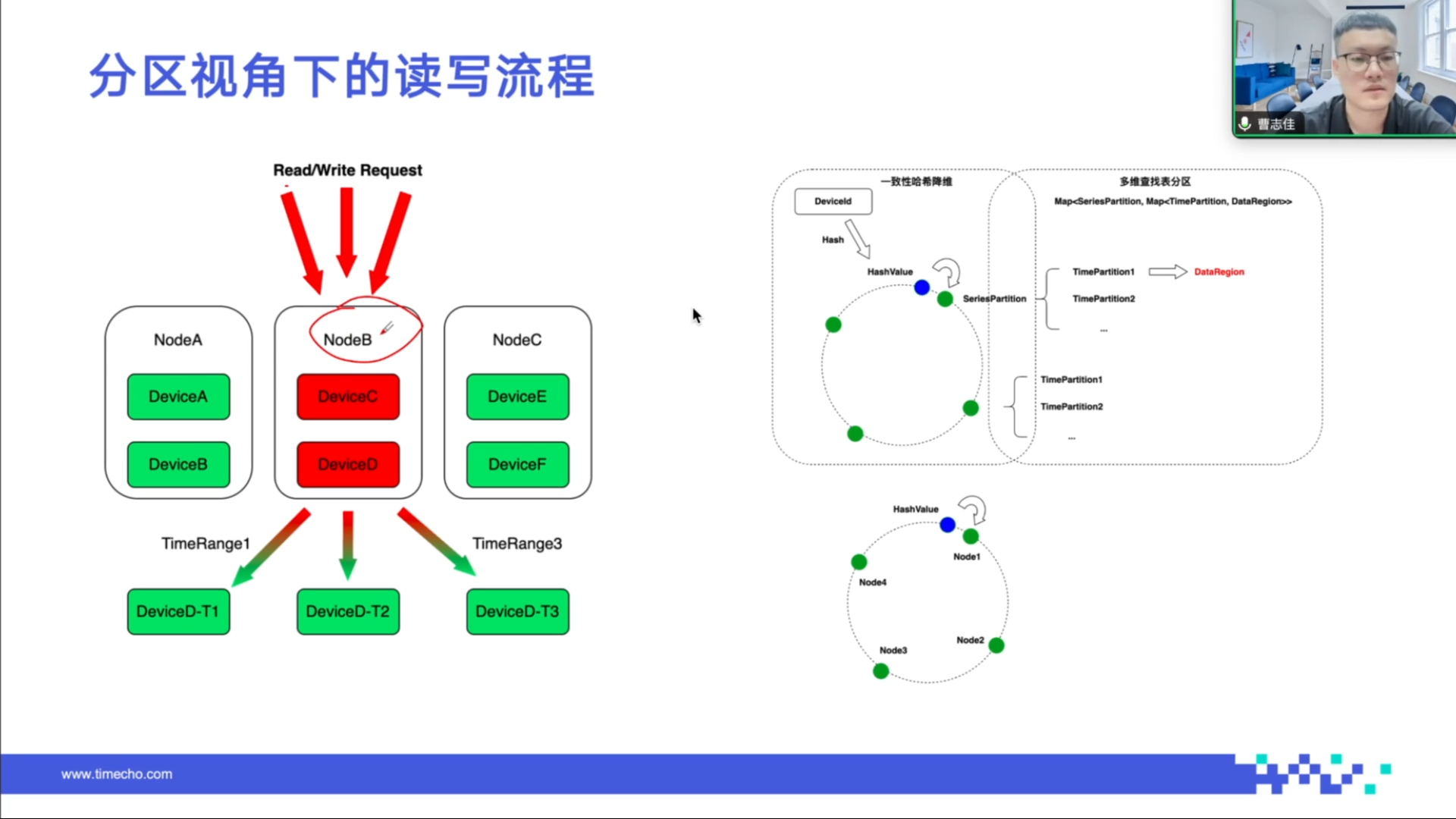
写入流程中,客户端将写入请求发送给 IoTDB 集群的任意节点,节点根据 device_id 做负载均衡算法,确定数据写入的节点,再根据数据携带的时间判断其所属的时间分区。
查询流程中,查询请求发送到数据库后,查询引擎通过 device_id 快速判断数据所在节点,将请求转发给该节点生成查询计划,再根据查询请求中的时间范围从相应时间分区中捞取数据,无需扫描其他时间分区,提升查询效率。
03 IoTDB 的数据同步机制
(1)数据同步的分类及场景
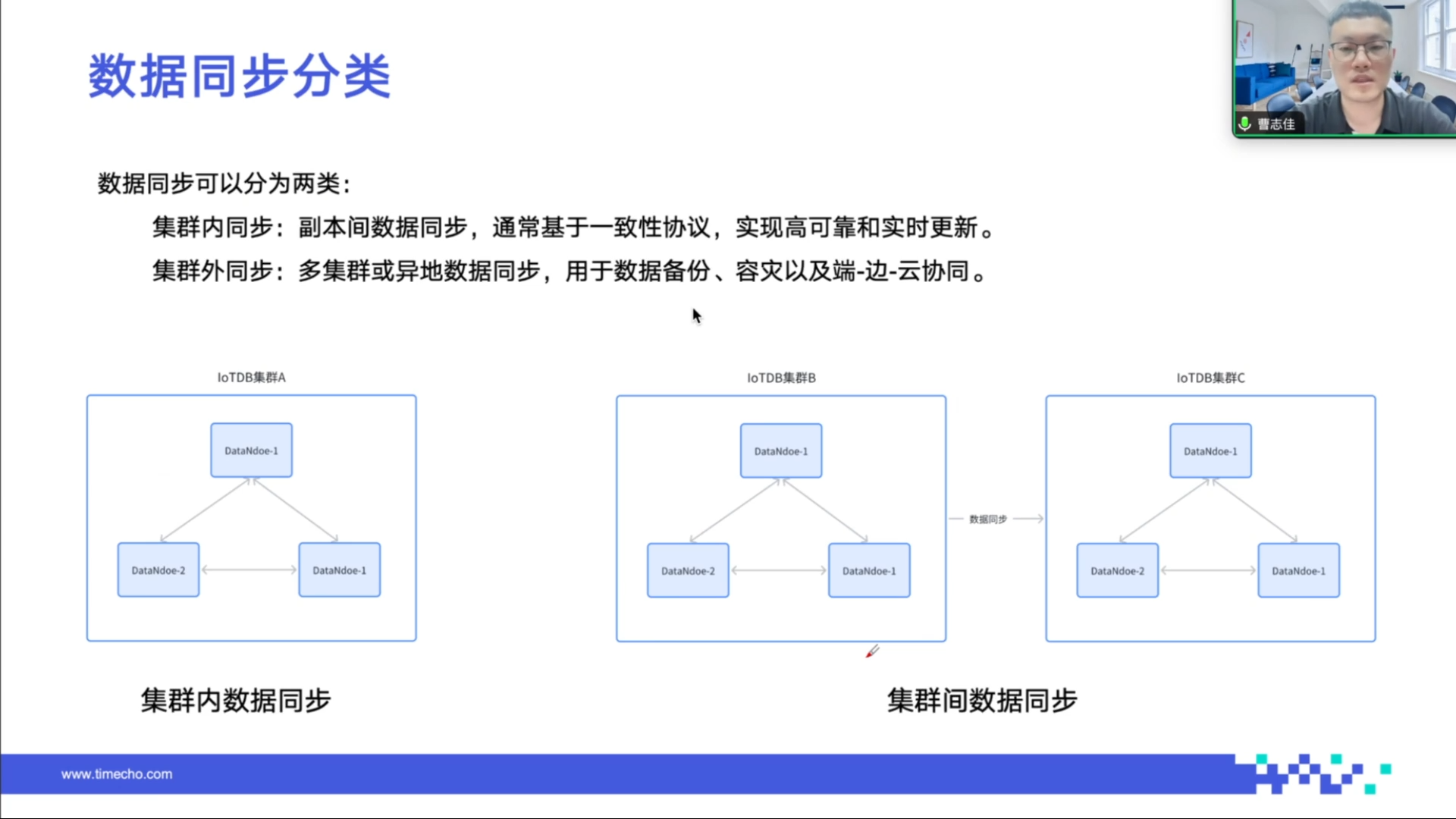
IoTDB 的数据同步机制分为集群内同步和集群外同步。
集群内同步是指集群不同节点之间的数据同步,基于一致性协议实现,目的是保证集群的高可用和数据副本的一致性。
集群外同步是指不同 IoTDB 集群之间的数据同步,可用于多集群间的数据协同,如热备份、容灾和端边云协同等场景。
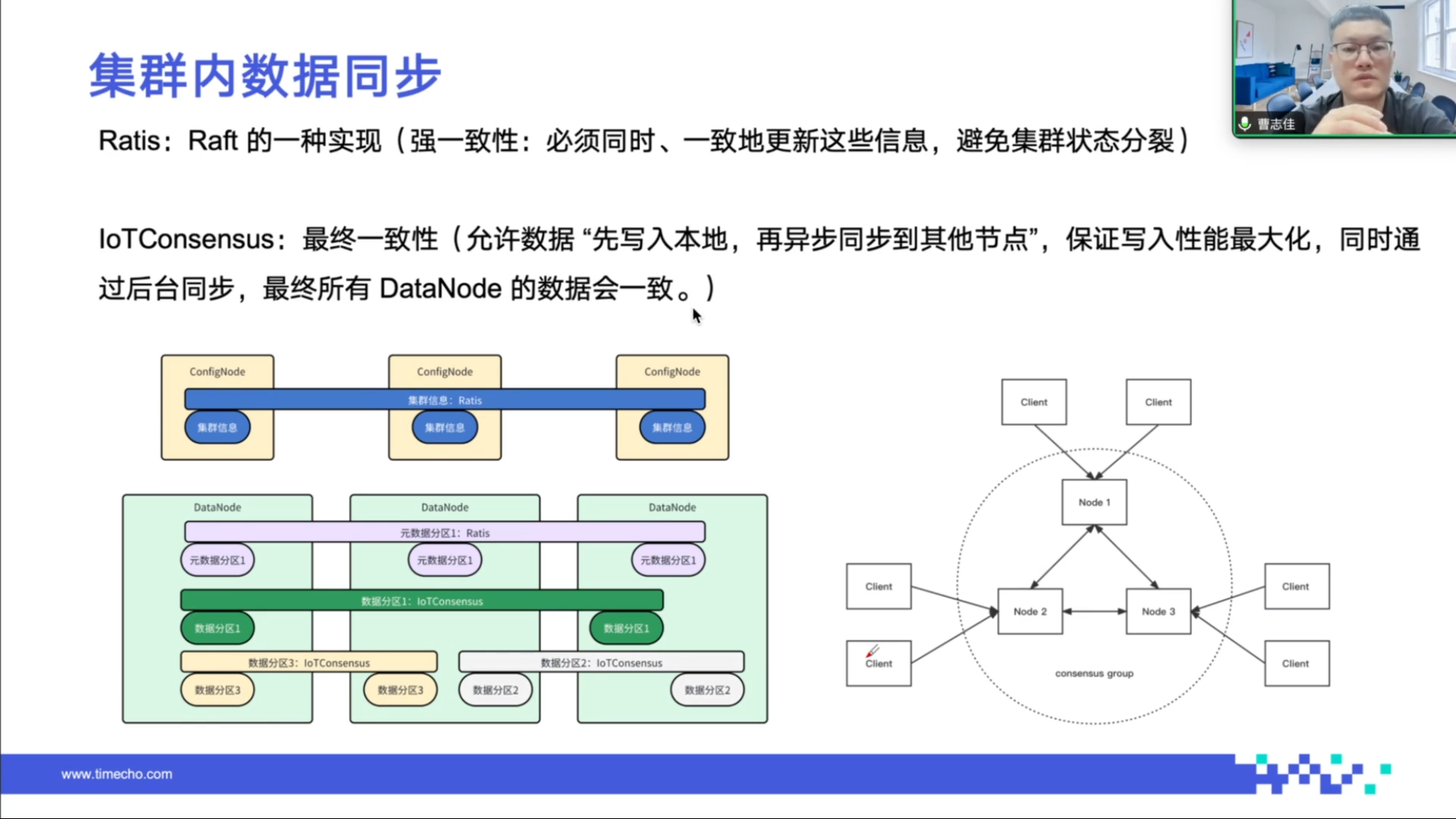
(2)集群内同步的协议及流程
IoTDB 支持的协议类型分为强一致性和弱一致性(最终一致性)协议。IoTDB 源数据分区和 ConfigNode 采用 Ratis 强一致性协议,确保请求在所有副本间成功更新才认为成功,但会产生数据延迟;DataNode 的读写采用团队自研的 IoTConsensus 协议,允许数据先写入本地,再异步同步到其他节点,可最大化提升写入性能。
同步流程中,服务端收到请求后,先由共识层处理,将请求下发给状态机,再由状态机下发给 DataRegion,DataRegion 调用存储引擎将请求写入内存表和 WL。日志分发线程异步将写入请求同步给副本节点,维护一个待同步队列,当队列无元素时向共识层索要请求。若副本节点掉线,主节点会记录同步进度,节点恢复后继续同步,保证数据的最终一致性。
集群内协议可用于集群内单点故障的容灾,当主节点出现问题时,备节点能自动升级为主节点继续提供读写服务。
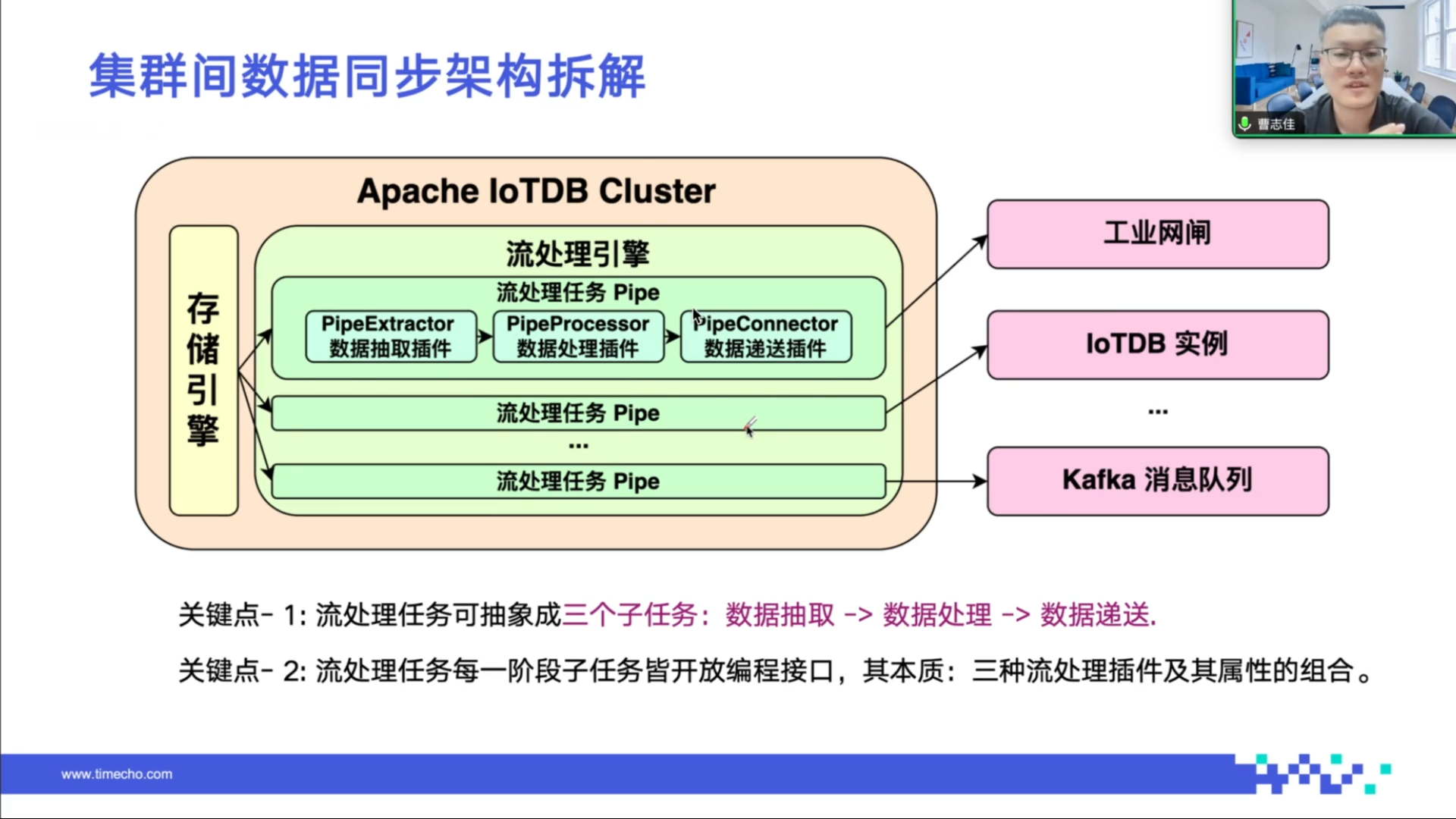
(3)集群间同步的框架及应用场景
IoTDB 提供的流处理框架包括数据抽取、数据处理和数据发送三个阶段。数据抽取决定从 IoTDB 中取出的数据范围,包括测点范围和时间范围;数据处理可对抽取的数据进行编程化处理,如删除离散值、转换数据类型等;数据发送由用户决定将处理后的数据发送到何处。框架支持用户基于官方提供的标准化编程框架自定义逻辑,官方也提供了一些内置插件。
IoTDB 的流处理框架可用于备份和容灾,通过简单 SQL 即可创建数据同步任务,无需依赖第三方组件,实现异地容灾,延迟可达毫秒级。还可应用于数据库内的实时告警、流计算、实时聚合和数据写回等场景,数据库间的双活集群、降采样同步、跨网闸传输和数据加密等场景,以及数据库外的数据订阅、发送到消息队列、Flink 数据加工和离线历史备份等场景。
04 问答环节信息汇总
(1)Ratis 协议使用建议
对于追求数据高一致性且对写入性能要求不高的场景,可考虑使用 Ratis 协议,IoTDB 对数据分区支持 Ratis 协议,但性能不如 IoTConsensus 协议。
(2)序列分区设计原因
面对超海量的源数据,如储能和气象场景,为减少内存管理资源消耗,采用序列分区槽的降维方式进行管理。
(3)跨网闸传输适配
流处理框架已对常见网闸(如南瑞、科东)做过适配,未适配的网闸只需进行简单适配即可使用。
(4)高性价比软硬件存储方案
IoTDB 支持多级存储,可将高频数据存储在 SSD 上,低频数据存储在机械硬盘或 S3 上,且支持查询时从 S3 拉回数据,用户对此过程无感。
(5)主节点磁盘损坏数据丢失问题
主节点给副本节点发数据延迟低,基本可控制在 1 毫秒以内,但极端情况下可能有数据丢失,这是最终一致性协议相对于强一致性协议的小弊端。
(6)高一致性与最终一致性对比
写入时,使用 Ratis 协议和 IoTConsensus 协议性能相差一半以上;查询时,IoTDB 默认查主节点,只要数据写入,查询效率不受影响。
(7)主副本掉线数据丢失问题
主节点会在共识层维护写入请求的 index,记录数据同步进度,节点恢复后能继续同步未完成的数据,不会丢失。
(8)多副本影响
多副本保证数据高可用,但会增加存储空间需求。写入时,副本同步为异步操作,一般不影响主线程,但在服务器资源瓶颈时可能有影响。
(9)主节点带宽要求
IoTDB 采用多主协议,每个节点都可对外提供查询服务,数据查询负载相对均衡。若带宽有限,可在网络传输中对数据进行压缩,但会降低传输效率。
(10)查询优化
客户端知道每个设备所在的 leader 节点,可自动连接该节点进行查询,减少请求转发。
(11)client 存储配置
cache leader 功能可配置,客户端资源好时可开启,资源不足时可关闭。
(12)指定节点存储副本问题
目前不支持指定节点存储数据副本,但支持手动迁移。可通过创建多个集群进行实时数据同步,实现异地双活。
更多内容推荐:
• 下载时序数据库 IoTDB 开源版
• 了解如何使用 时序数据库 IoTDB 企业版


