

12 月 3 日,2023 IoTDB 用户大会在北京成功举行,收获强烈反响。本次峰会汇集了超 20 位大咖嘉宾带来工业互联网行业、技术、应用方向的精彩议题,多位学术泰斗、企业代表、开发者,深度分享了工业物联网时序数据库 IoTDB 的技术创新、应用效果,与各行业标杆用户的落地实践、解决方案,并共同探讨时序数据管理领域的行业趋势。
我们邀请到清华大学软件学院长聘副教授龙明盛参加此次大会,并做主题报告——《IoTDB 新组件:内生机器学习》。以下为内容全文。
尊敬的各位来宾、各位老师、各位同学,大家上午好。今天非常荣幸在这里跟大家分享,我们在 IoTDB 新组件:内生机器学习这样一个新的引擎的发布。
01 背景起因
我们首先简单回顾一下我们的起因,就是工业物联网数据在它的采、存、算、管、用的阶段,其实是有各种挑战的,IoTDB 已经解决了其中相当一部分挑战。但是在现在的工业物联网场景下,我们的数据往往来说是静止存储于我们的数据库里面,然后我们可以在这个数据上做一些查询,或者说一些简单的聚合分析,但是这一部分却逐渐地成为了企业的一个成本中心。
我举个例子,比如说我们在跟中国气象局在做气象大模型的过程中,里面有非常多的时序数据,而这些时序数据库最终要变成一个强大的预报大模型。那这个过程就不能让数据再静置,而是应该要让它流动起来。
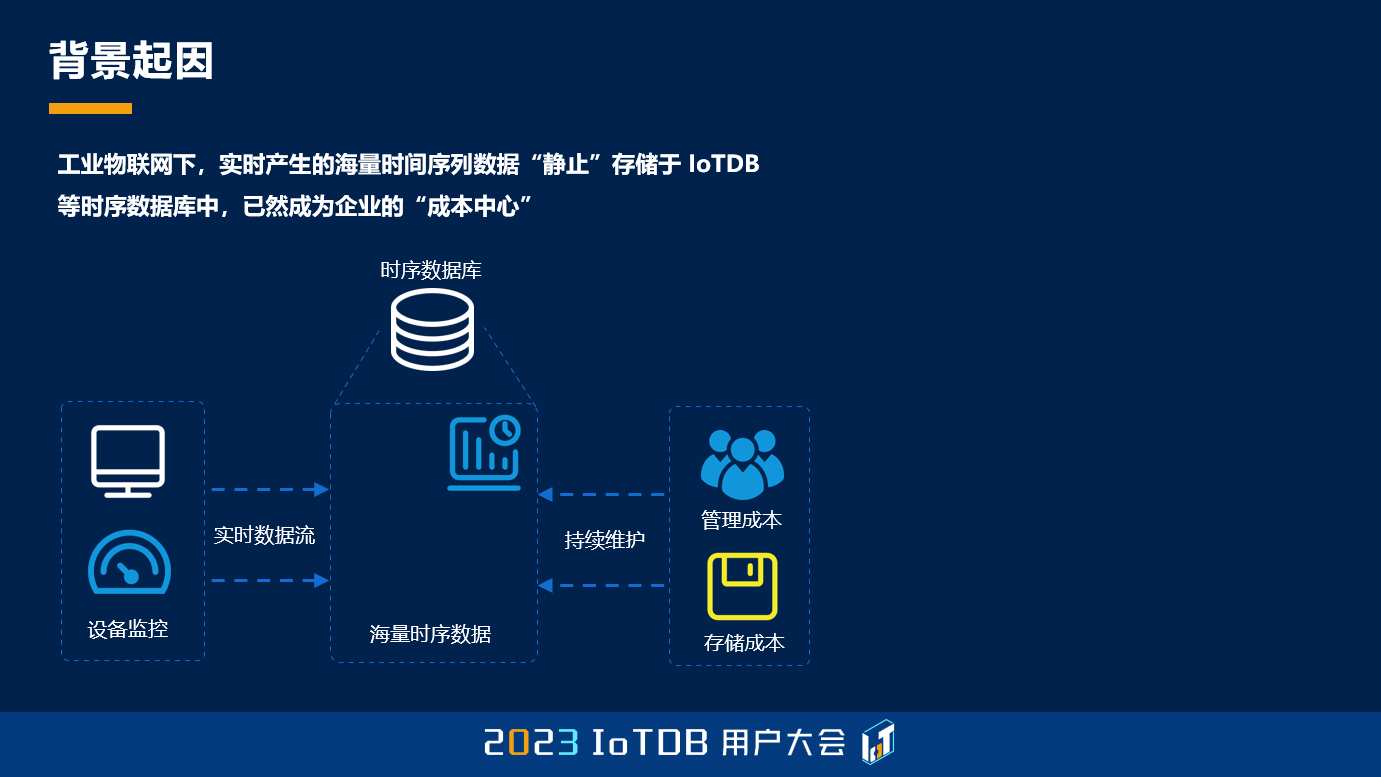
那么基于这样的一个背景,我们希望在传统的 OLAP 的基础上,进一步地去以机器学习技术作为新的智能技术的一个代表,然后去挖掘和释放我们的数据。我们可以看到,我们的数据可以通过机器学习、模型和算法构建,然后支撑时序预测、异常检测等等这样一系列的应用。
那么我们也可以看到现在,社区其实有很多的机器学习系统的这样一些支持,但是现在存在的一个问题就是说,这些数据的系统和智能的系统相对来说,它们之间隔阂还是比较严重的,往往需要进行大量的数据的导入、导出等等。
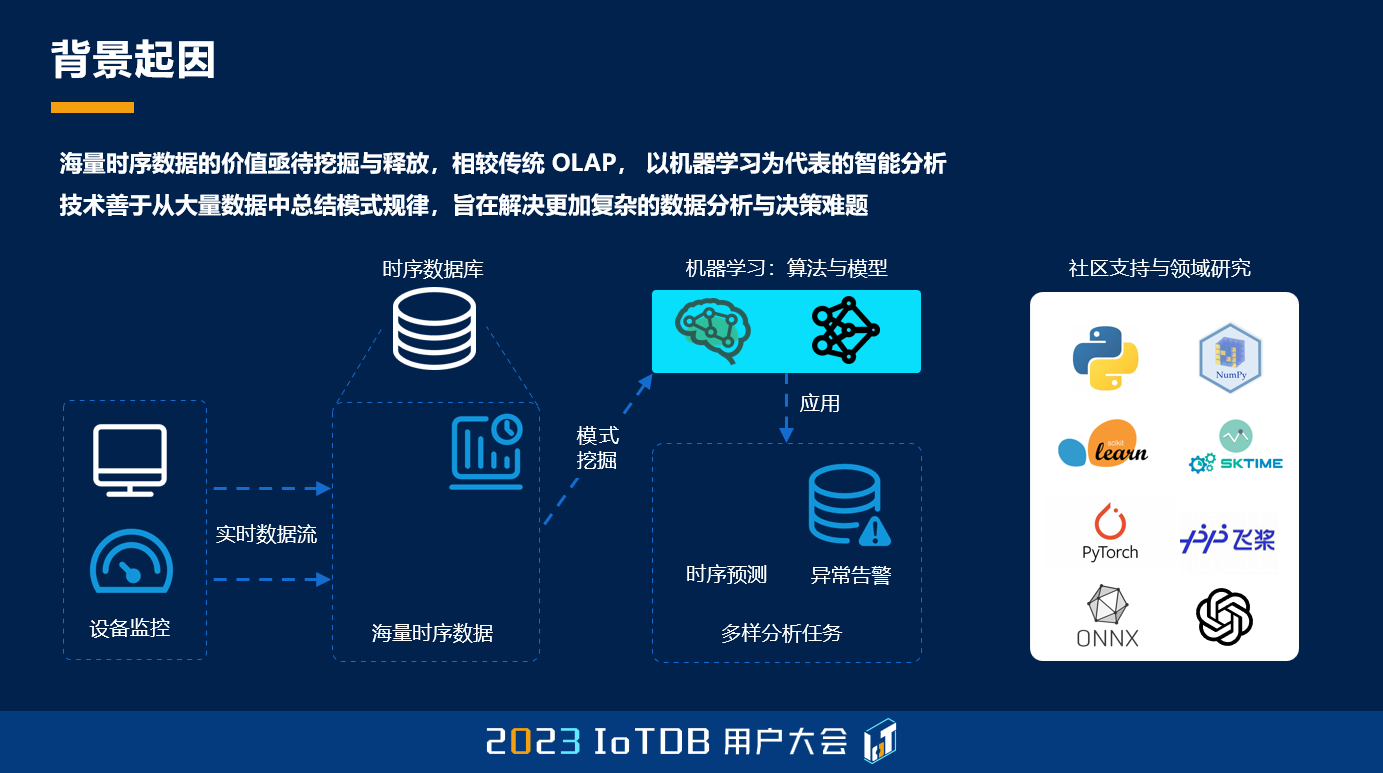
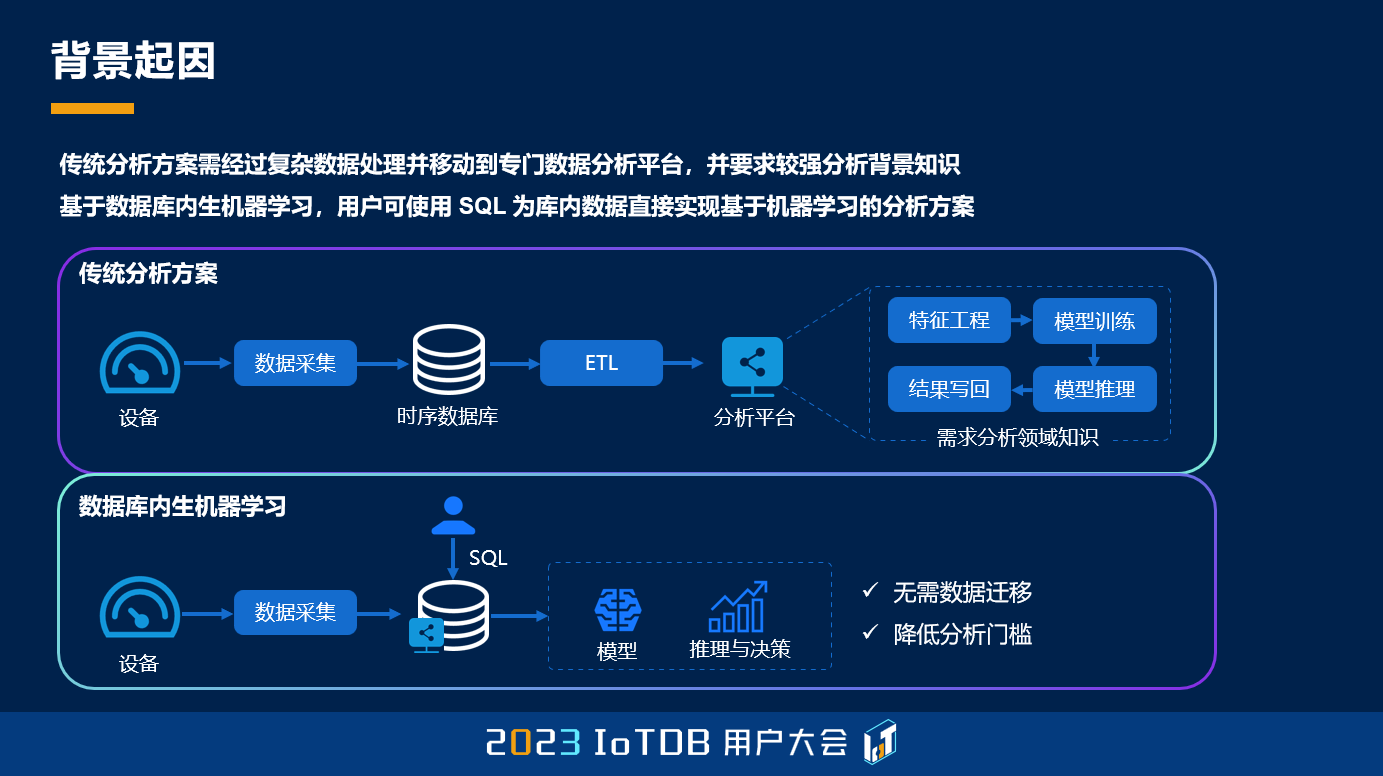
那么我们可以看到一个传统的数据分析方案,其实它的门槛比较高,成本也比较大。这其中,数据的迁移,数据的各种转换就非常的耗时。在机器学习工程化过程中,还需要进行特征的工程、模型的训练、结果的管理、实验的管理等等一系列非常复杂的工作。那如何将这样的一些工作更好地,在刚才我们讲的工业物联网的公共的底座,IoTDB 上进行支持就是我们的目的。我们希望能够尽量地做到无需数据迁移,并且降低数据分析的门槛。
02 系统实现
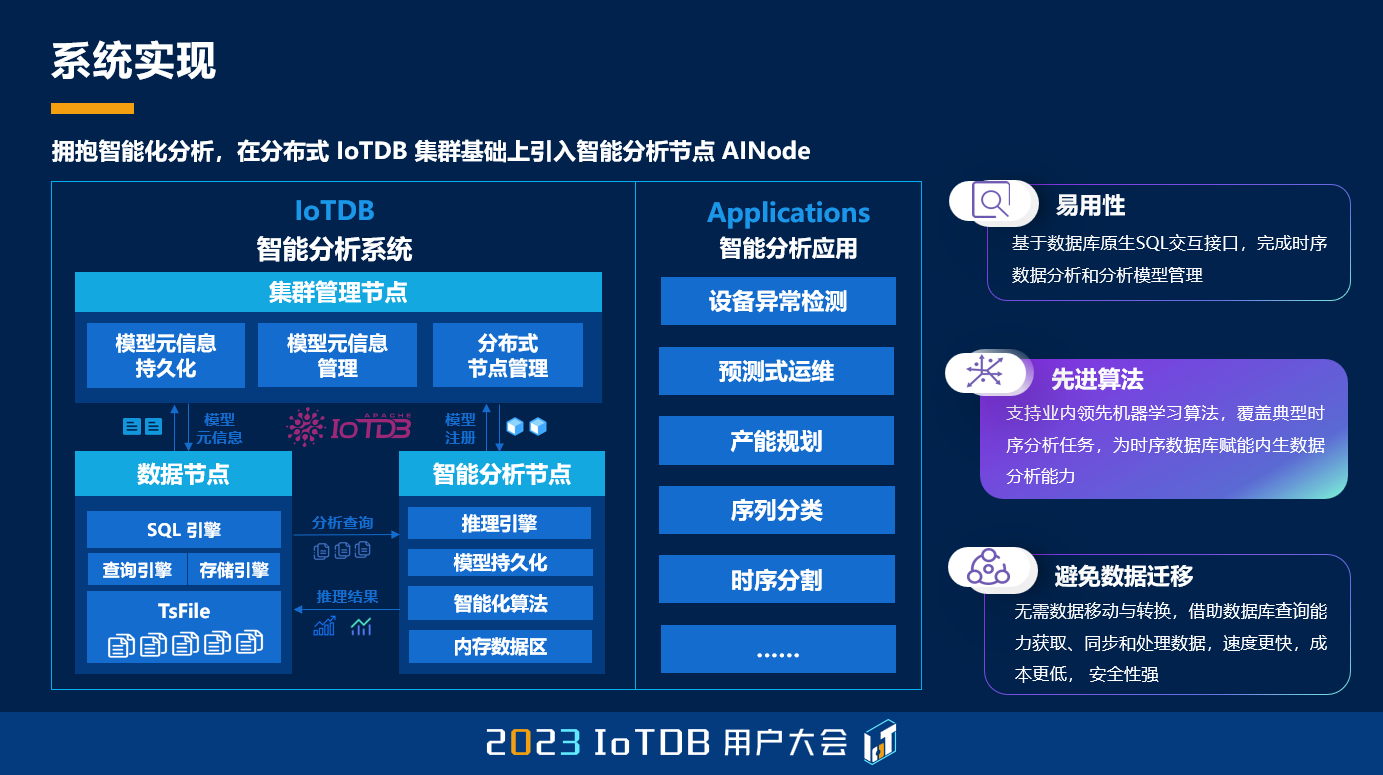
这是我们进行的系统的实现,它的一个典型的特点就是数据库内生。我们知道现在其实机器学习系统非常多,对吧?那如果说它是一个数据库外的机器学习系统,其实大家有各种框架,比如像 Scikit-learn、比如像 Tensorflow、Pytorch 等等,那么这样一些系统其实无法解决我们前面讲的一系列的问题。
我们可以看到,采用数据库内生的机器学习框架和引擎之后,我们可以利用 SQL,并且对这个语言进行拓展,从而实现像 SHOW MODEL、DROP MODEL、CREATE MODEL、还有 CALL INFERENCE 这样一些最基本的机器学习的能力。在这个过程中,我们其实是在这个系统中,在数据的基础上,用前面王院长的话来说,将数据变成模型,然后再将模型变成决策。模型也是这个系统中的一种重要的资产,我们需要将它进行管理,我们除了能够创建它,我们还能够使用它进行推理,变成一种内建的能力。
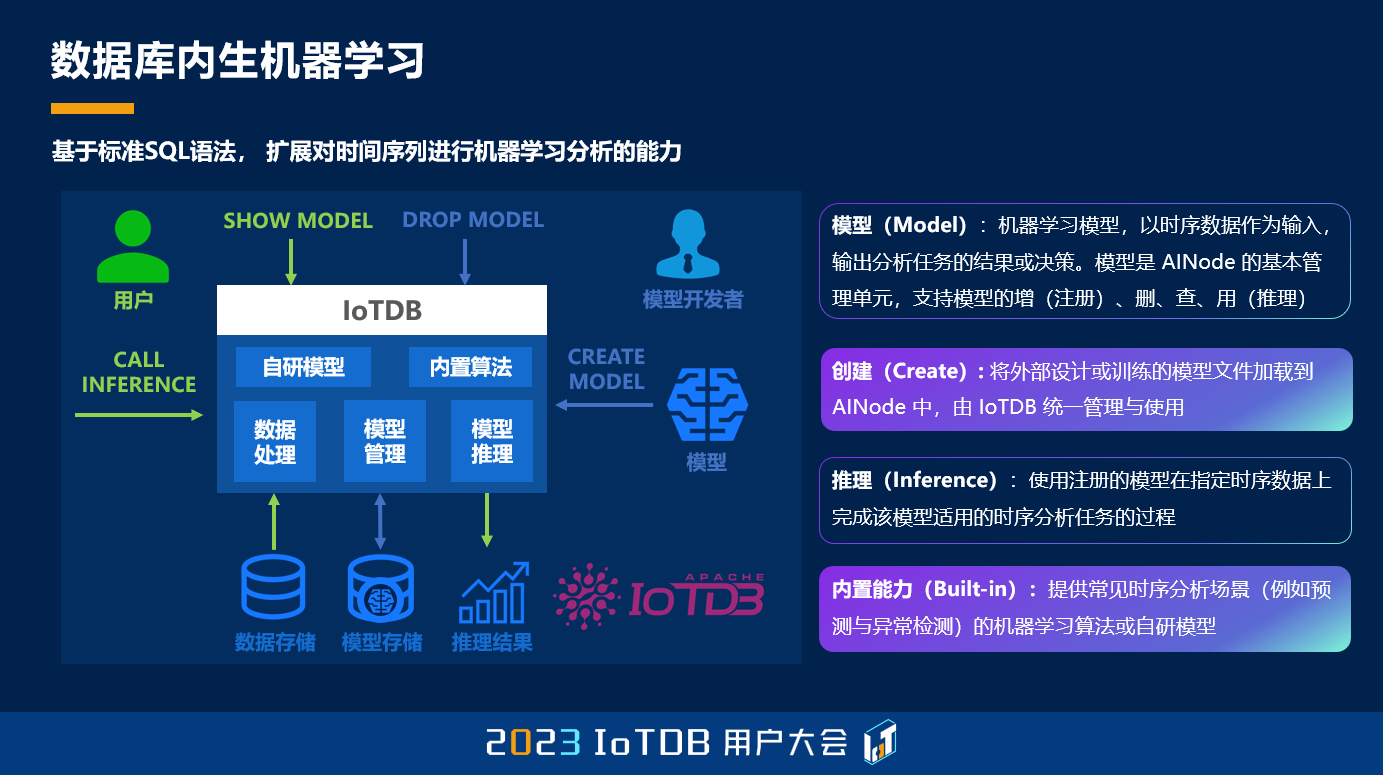
那么应该来说,前面乔老师也讲了,我们在 IoTDB 的基础上扩展了一个新的节点,就是 AINode。其实扩展这个节点,刚开始去想这个事,好像没那么容易。因为 IoTDB 现在本身有配置节点 ConfigNode,和数据节点 DataNode,当这个系统是一个集中式的系统的时候,或者说是一个单机的系统的时候,实际上这件事情是有一定的困难的。那么随着 IoTDB,它的分布式的版本已经研发成熟,那么我们可以在一个分布式系统体系的架构下,再去审视这一个结构,我们就会发现,我们的 AINode 其实和 DataNode 是在一个相同的地位上。在一个分布式的集群上,它们其实都是对数据进行加工,只不过到底是浅层的处理加工,还是深度的、模型的加工。
那在这个过程中,我们也需要去处理分布式系统中,我们的训练数据和我们的模型之间,到底是模型找数据还是数据找模型,这样的一个关系。那前面我们 Mohan 院士也提到了,在 HTAP 这样一个新型的框架下,内存式的这样一种存储方式,其实是同时能够兼顾它的效率和它的成本的。那么因此的话,我们可以在 IoTDB 现有的框架下,进一步基于分布式内存的这样一个新型的副本机制,能够将我们的数据和模型更好地联系在一起。
03 功能支持
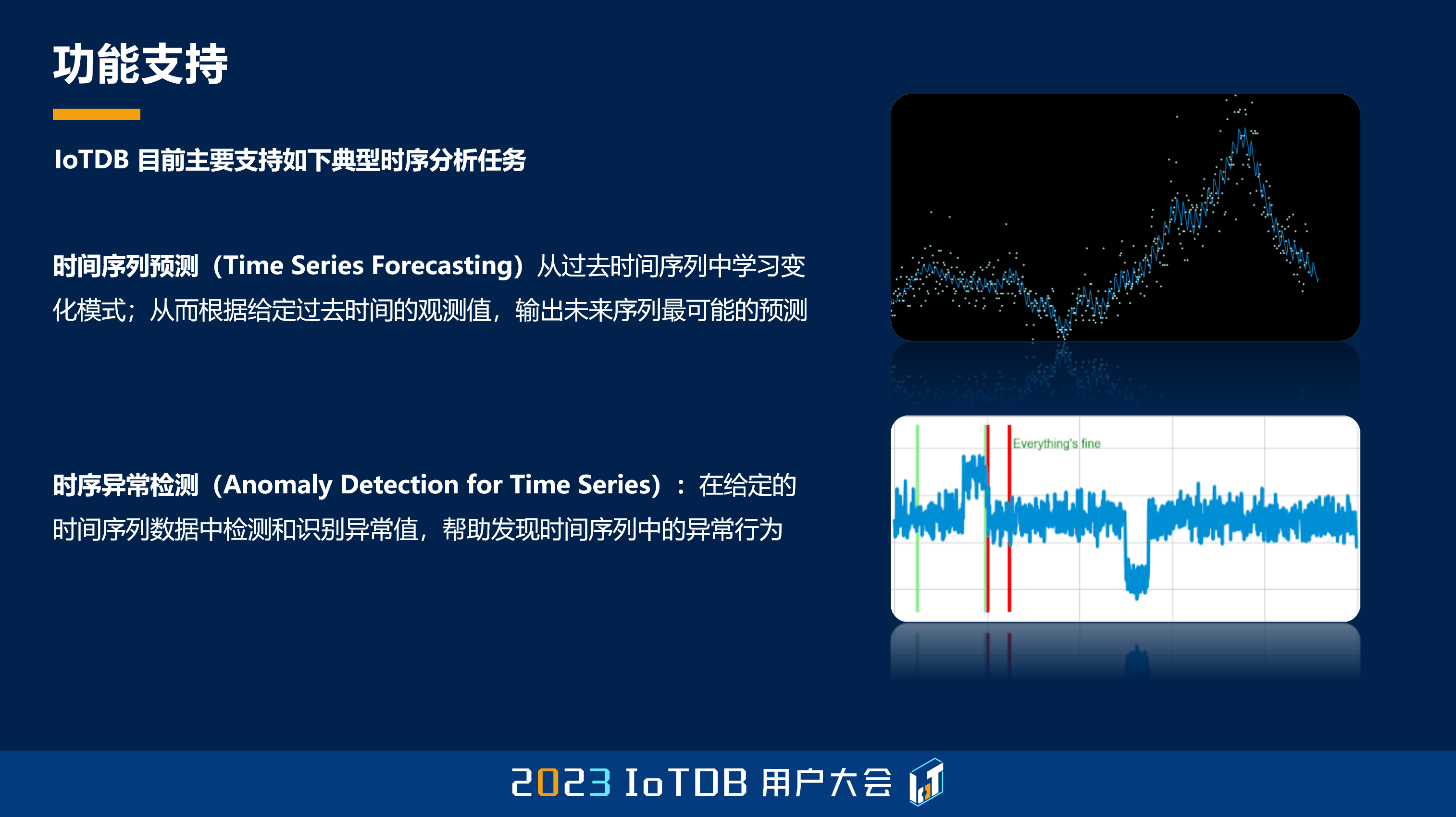
那目前来说,我们功能支持方面,支持时序的一些典型的分析任务,比如说像时间序列预测,还有时间序列的异常检测等等。
那么大家都知道,其实我本人是做机器学习的,我做了十几年的机器学习。我发现大概在 2020 年之前,时间序列数据不是我们人工智能社区的一等公民,也就是我们做人工智能的人,一般都做机器学习的算法,或者是做比如说图像、自然语言这样一些处理。但是 2020 年之后,随着时间序列数据越来越重要,因此在机器学习社区已经成为一个非常热门的话题。
比如近年来,我们团队就提出了像 Autoformer、TimesNet、还有 iTransformer 这样一些非常好的模型,并且我们的这样一些模型具有数据通用和任务通用的能力。也就是说一个模型,它既可以支持时序预测,也可以支持异常检测,也可以支持时序分类等等这样一些通用的能力。同时我们这些模型具有一定的可扩展性,未来可能进一步拓展成大模型。我们的相关技术也在《自然-机器学习》子刊,这样的一些顶级期刊上进行封面文章的发表,我们这些模型在支持实际的应用中发挥了比较重要的作用。这也让我们看到,将时序数据分析作为工业物联网基建中的一等公民的这样一个至关必要性。

我们现在可以支持机器学习模型的基本的模型管理和模型编译、模型加速,通过这样的一个方式,可以使用 IoTDB 的 AINode 进行推理。那由于机器学习社区发展的时间已经非常久了,像 Pytorch 还有 Python 已经变成机器学习社区的第一语言,因此 IoTDB 在之前的 Java 语言的基础上,努力拓展了 Python 这样的一种语言的支持,从而使得我们在 IoTDB 上进行机器学习变成非常自然、非常友好的一个过程。

04 应用实例
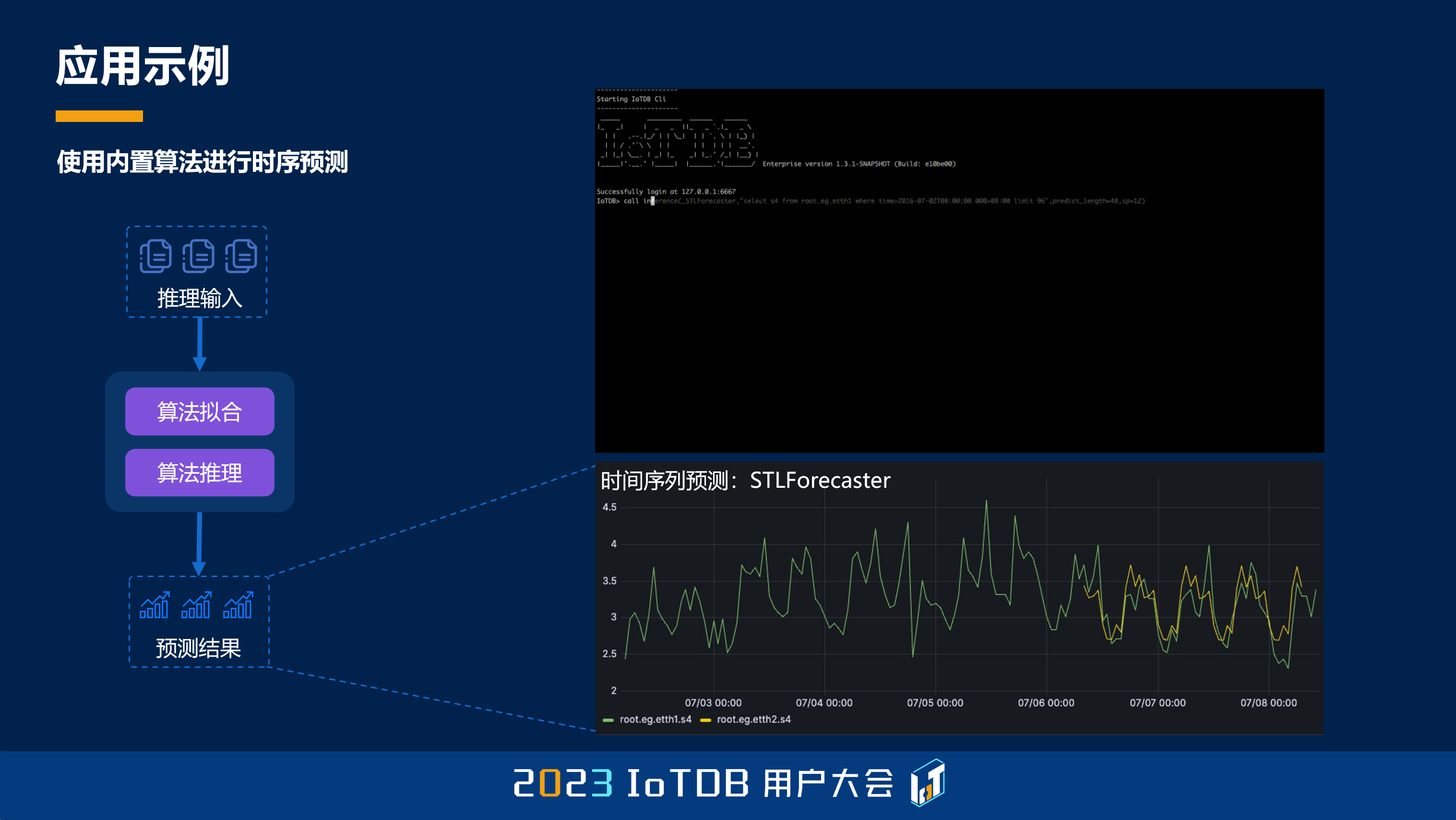
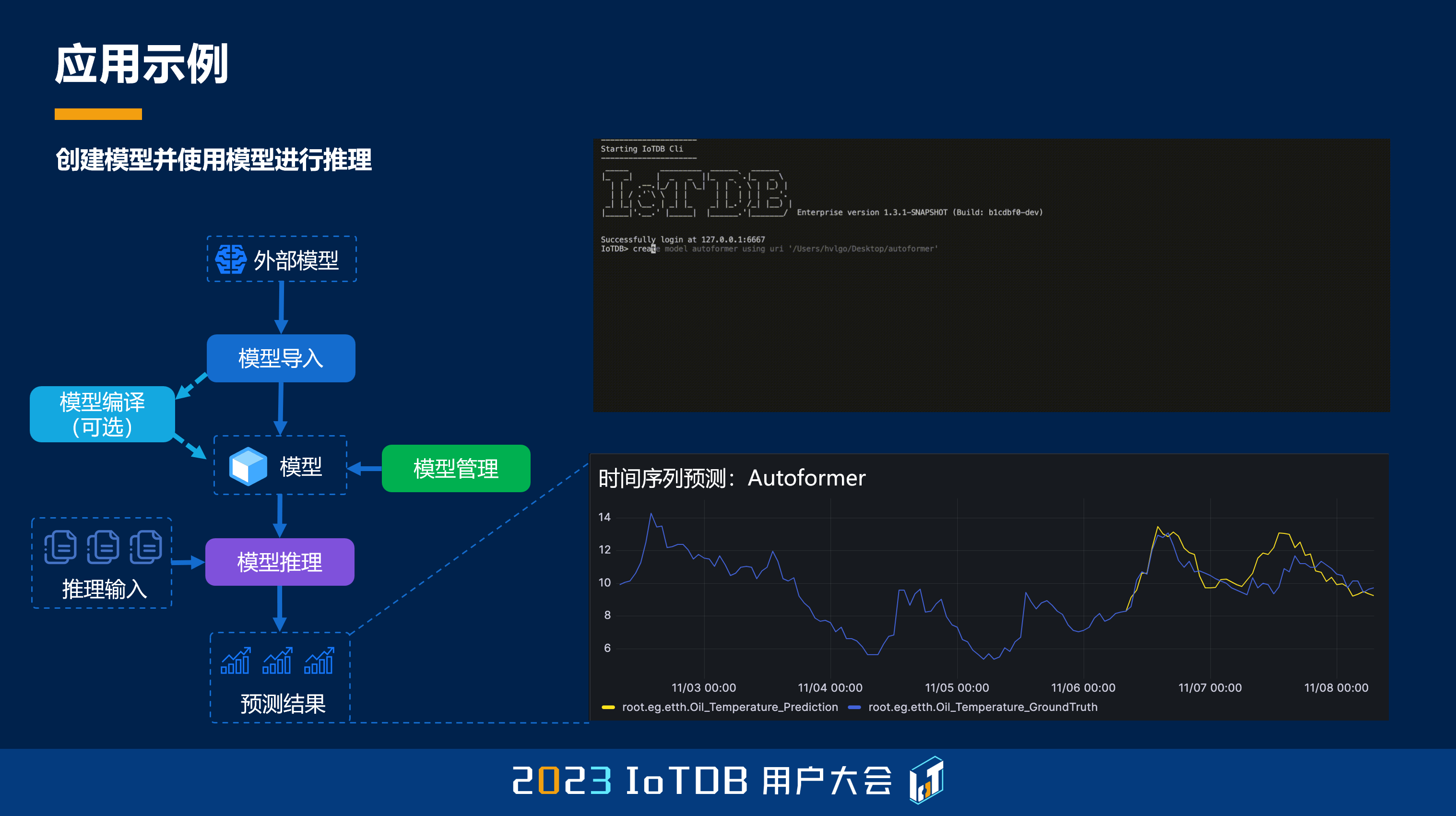
好,我们举几个典型的应用吧。比如说在时间序列里面,我们比如说像用电量,还有前面我们讲的气象、风速等等,都需要做一些时间序列的预测。这个时候我们可以在 IoTDB 上非常简单地完成这个集群的部署,然后在这个过程中启动 AINode 这样的一个脚本,从而能够自动地载入相关的依赖,从而进行 IoTDB 上的机器学习模型的推理。

目前来看,我们有多种方式来使用这个模型。一种是我们内置的算法,也就是前面我提到,我们团队自研了很多时间序列的算法,我们可以对这些算法进行一个原生的支持。
除此之外,我们还可以支持外部的一些模型。在前面各位老师都强调了开源的力量,就是我们肯定不是一个封闭的系统,那么随着社区中有一些比较好的模型,我们可以通过类似 Hugging Face 的方式,将这些模型注册到 IoTDB 的系统中,从而使它变成 IoTDB 系统中的一种资产,从而利用我们的 AINode 进行这样一些模型的推理、服务。
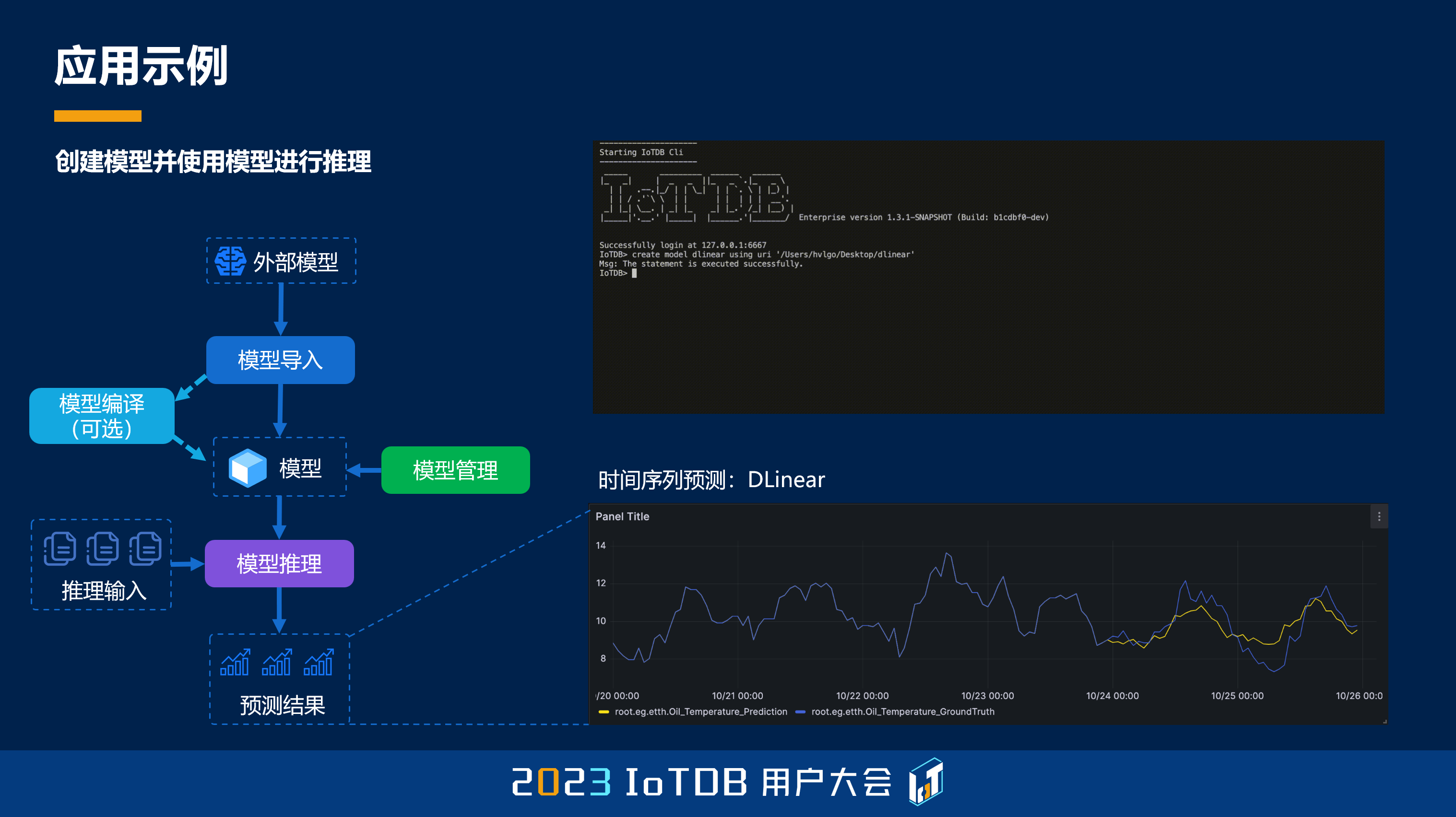
那么在这个过程中,我们可以对不同类型的时序模型进行一个标准的统一,从而能够轻松地支持不同类型的,前面我们提到像 Autoformer,比如说像 DLinear 这样的一些模型。
05 未来展望
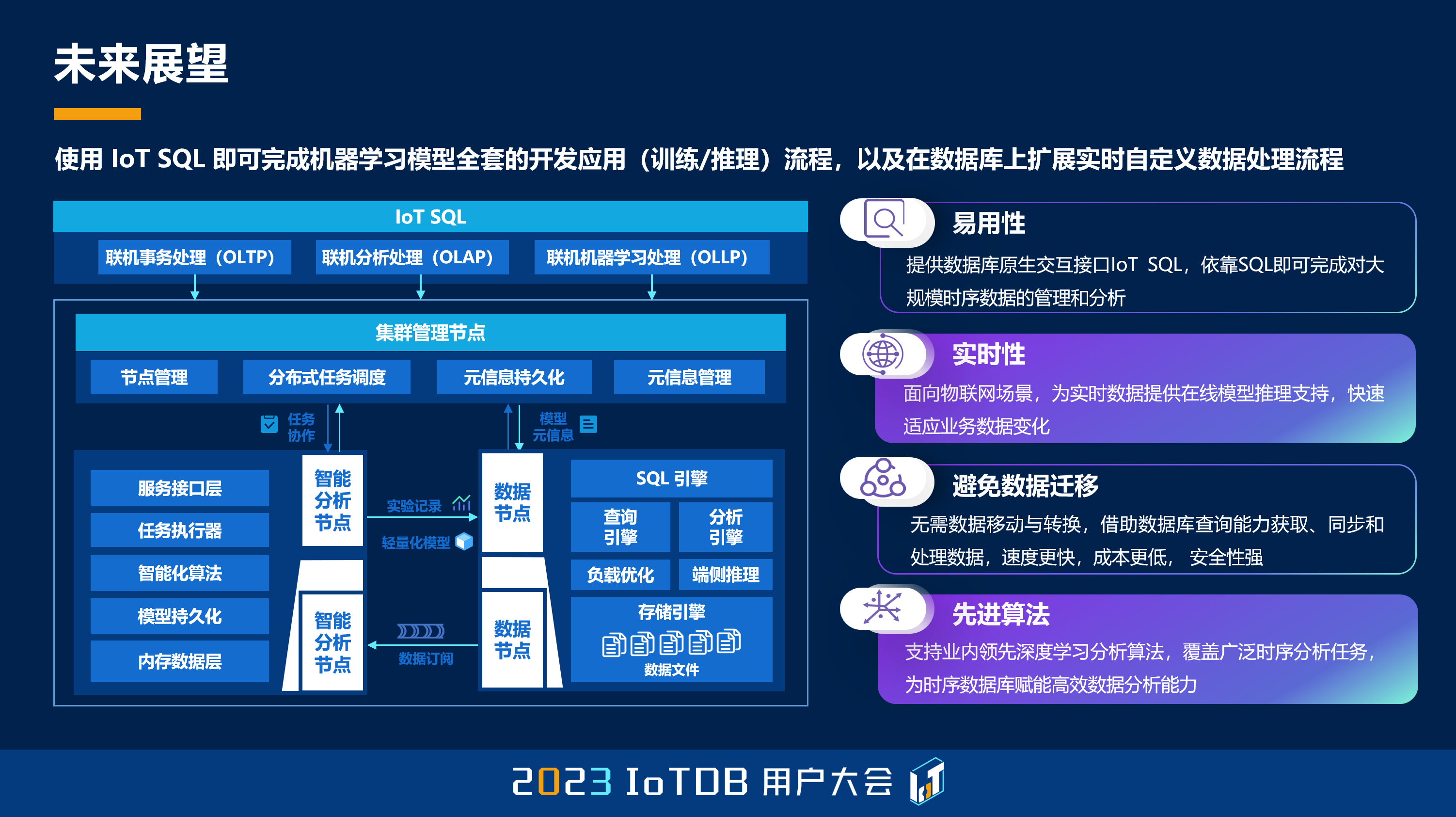
未来展望方面,我们希望构建 IoT SQL 这样一种拓展的语言,这样的语言可以更好的支持 HTAP 这样一些多样化的数据分析,尤其是机器学习的能力,从而在易用性、实时性、避免数据迁移和支持先进算法方面做更多的工作。
大家都知道,时间序列领域,我们的算法在数据库中的支持其实是挺少的,对吧?可能大家听说有一些经典算法,像 Holt-Winters,有一些支持,但是这些先进的算法要想支持进来,明显超出了现有的数据库的体系架构的一种支撑能力。这也是之前数据库领域大家一直在讲的,数据库是不是一个小马拉大车,对吧?上面的 AI 的负载是一个大的负载,对吧?有可能会把数据库压垮,这样的一些问题。那恰好由于时间序列数据它的特殊性,它是轻量级的,那我们构建的机器学习模型也可以是轻量级的,那么整个就是一个轻量级的结构,它就不会出现水土不服。
如果老师们问,像大模型 ChatGPT,能不能用在 IoTDB 里面?大家都知道,ChatGPT 背后有几十万张 GPU 的支持,对吧?像这样一些很重的技术,要想放在数据库里面,很有可能会把数据库压垮。那么因此我们认为对这样的一种技术,有可能是采用现在更流行的 API 调用的这样一种方式,对吧?而把这些大模型放在另外一个基础设施上面去做。
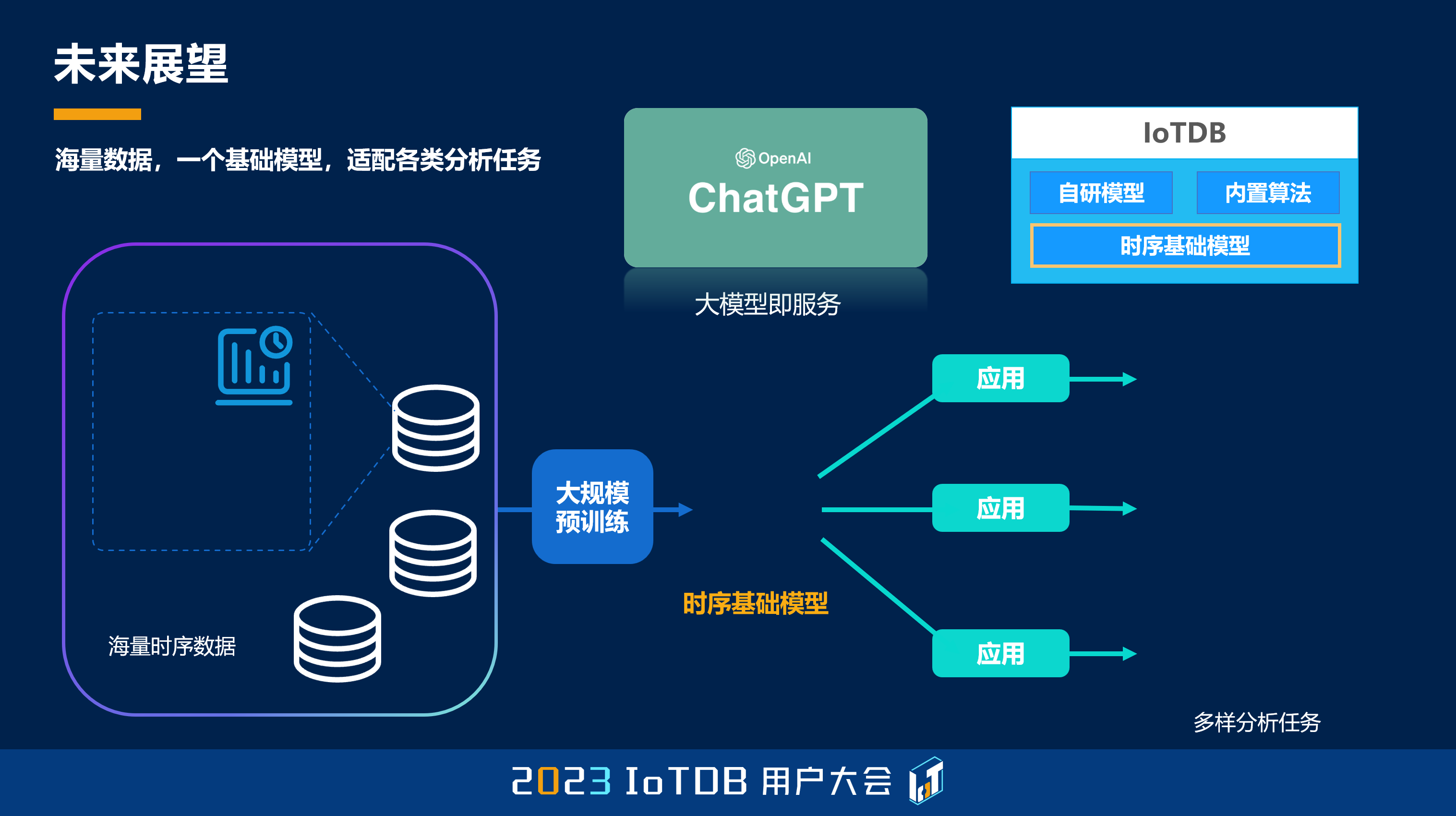
好,这是我最后一页,我做一个未来的展望。我们团队在研发时序数据基础机器学习模型的过程中发现,时序数据目前的一个痛点就是没有大家公认的、好的机器学习模型,大家都是一事一议,今天我做我用这个模型,明天我做我用那个模型。那为什么会这样呢?我个人认为就是基础模型的发展没有引起大家足够的重视。那另外一个原因就是时序数据它自己的特殊性,它的这种变量的多样性,它的采样频率的多样性,它的数据的这样一个长周期的多样性等等,都会让我们构建一个基础的时间序列模型变得比较的挑战。
但是我们团队也在这方面进行相关的攻关,已经取得了一些初步的进展。我们构建出来的时序基础模型,或者说大模型,已经具有比较好的跨变量的这样一些泛化能力。我们期待着我们时间序列基础模型的研究成果,能够更好地提高 IoTDB 作为时序数据基座的能力。
今天我的分享就到这里,谢谢大家。
更多内容推荐:
• 回顾 IoTDB 2023 大会全内容


