

12 月 3 日,2023 IoTDB 用户大会在北京成功举行,收获强烈反响。本次峰会汇集了超 20 位大咖嘉宾带来工业互联网行业、技术、应用方向的精彩议题,多位学术泰斗、企业代表、开发者,深度分享了工业物联网时序数据库 IoTDB 的技术创新、应用效果,与各行业标杆用户的落地实践、解决方案,并共同探讨时序数据管理领域的行业趋势。
我们邀请到宝武装备智能科技有限公司技术中心副主任赵刚参加此次大会,并做主题报告——《宝武集团设备智能运维超大规模分布式数据湖建设探索》。以下为内容全文。
大家好,今天我分享的题目是宝武集团在设备智能运维超大规模分布式数据湖建设的一个探索。我们公司和 IoTDB,实际上应该是在去年的时候,我们也是进行了一次全面的技术的对比,然后在 2023 年是全面的一个融合。
01 简介
我们公司全称是叫宝武装备智能科技有限公司,简称叫宝武智维。我们公司大概有 8000 人,是整个宝武集团设备智能运维专业化的一个平台化公司,我们的前身是宝钢检测和宝钢检修,这么一家公司。因为宝武集团这几年不断地在做吸收兼并,规模不断地扩大,那么公司跟着宝武集团的这么一个壮大的过程,我们也在不断地成长。我们的愿景是做产业生态圈智能运维的主体平台,我们的使命是为用户提供稳定可靠、智能高效的设备运行保障,我们的定位是中国宝武设备智能运维专业化平台公司,打造第三方的智能运维平台。

这是我们的一个拳头产品,我们把它叫宝武智维云。目前,宝武集团大概有接近 20 家的生产基地,已经全面覆盖了,就是它在我们每个基地都会部署一个设备智能运维的平台,负责将基地内的所有设备来接入其中,进行在线状态监测和一些智能运维业务。这个图中我们可以看出,我们是目前已经覆盖了 21 大基地,部署了有 27 个子平台,接入了 60 万以上的设备、240 万的数据项,总数据量超过了 5 个 PB。在平台上我们部署的这种具体规则超过 10 万条,我们现在已经沉淀下来的这种智能模型超过 40 大类,平台用户数超过了 1 万。

02 痛点
我们在全面的接入 IoTDB 之前,其实已经经过了多年的探索,在 2016 年的时候,宝武智维已经在开始这方面的探索了。我们之前的系统架构是,大家可以看右下角这个,我们实际上还是基于 Hadoop 的 HBase,上面用的是 OpenTSDB。应该说在初期,还是帮助我们的业务做到了非常好的一个效果,但是随着数据量的接入之后,现在慢慢的成为了制约我们企业发展的一个底层的瓶颈。
主要体现在两方面,一个是慢,包括什么呢?就是写入慢,常规的时候,正常情况下,可能勉勉强强。因为我们在每个基地的这个资源,也不可能说是在云上那么地丰富,所以说它的整个性能指标也是一个很一般的指标。特别是碰到比如网络断线的时候,大量的消息、数据堵塞之后,要快速的消费,但是后来大家就很心急,就看着那个消费的速度非常慢。
还有一个是查询慢,查询这个事情应该说还是非常影响用户使用效果的,对吧?我们那么多数据,有跨度为一年的,要快速的、要秒级的响应,这个基本上现在我们的平台上数据量之后,就是在未切换之前,基本上都是到 5 秒、10 秒、甚至半分钟才能刷出来,这个基本上就成为我们被诟病的很大的一点。
还有一个是加工慢。基于 OpenTSDB,要做各种各样的数据加工,包括聚合函数,这个里面的速度也是非常的慢,而且很容易导致整个数据架构的不稳定。
抽取也慢,当我们做这个数据资产的聚合的时候,我们不断地要往集团抽数据的时候,也发现这个瓶颈。在抽取的过程当中,一个是慢,另外一个对整个系统架构,它的这个稳定性的影响也比较大。
另一方面就是难。刚才讲了,一个是数据的汇聚难,还有一个是数据的清理难。因为大家知道基于 HBase 的这个数据清理,它非常的不灵活,我们基本上用一些 TTL 这种方式来进行一种删减,很麻烦。像我们有些数据给它定好,这个磁盘快爆了,然后我们必须还要写程序导出这部分数据,全部干掉,然后再导回去,所以这很多事情在我们运维上也是带来很大的痛苦。
还有备份难。我们一般做的是 3 节点的一个集群,那么这么大的一个体量之后,我们要备份,特别是策略化备份,非常困难,基本上就没有备份了,我们就是一个 3 节点的集群,来响应这个需求。
所以整体来讲就是,我们企业花大量的成本获取到了大量的这种高价值数据,但是变成了深不见底的一个数据黑洞。随着这个数据不断的增长,它的运行的效率得不到提升,成为了一种拖累。我们公司专门有个 AI 团队,AI 团队其实他经常给我诉苦,没办法去做,他做任何事情都是要小心翼翼的,因为一旦模型对数据的并发一上去之后,甚至会影响到我们在用平台的一个稳定性。所以这个带来了非常核心的一个问题,我们企业的发展必须要解决这个问题。

03 方案
在这个过程当中,我们特别是在去年,应该说是全面的在进行评估 IoTDB,不仅仅因为它是我们国产的数据库,更因为 IoTDB 它的高性能,在我们经过非常谨慎的一个对比当中,我们决定选用它来做我们的一个解决方案。
我们首先是全面地应用 IoTDB,替换掉 OpenTSDB 来做时序数据湖。这个其实代表了我们整体目前的一个架构,我们现在全宝武集团所有生产基地,大概我们还有一个基地没实施,马钢现在还没做,其他所有基地,我们的数据底层都换成了 IoTDB。然后,我们在整个宝武集团层,建了 E4 的一个大的数据湖。我们在集团层基本上是常态数据,是降频送上去的,还有就是所有的故障特征数据,是原始频率送上去的,这里面有我们所有的故障特征库。同时在集团层,它可以通过下发任务的方式,去各个基地抽取它所需要的一些数据,主要是用于一些模型团队,还有一些定制化的任务。
在这个数据之间的传送,其实我们现在是两种方式。第一种方式其实是 IoTDB 推荐的方式,就是 TsFile 一贯到底,用比如 Pipe 的方式,这个效率是最高的。但是我们现在大量的,其实还是通过我们叫数据总线,Kafka 数据总线,来数据上传的方式。因为各个基地之间,企业它的防火墙的要求是非常高的,所以宝武集团在各企业之间,基于 Kafka 数据总线是经过审批全贯通的,但是如果说要再走其他的防火墙,这个管理流程特别长。所以说我们在全宝武内优先是走 Kafka 数据,也很简单,一传上来就好了,但是我们在宝山基地,因为这个开通相对比较方便,我们就是用的 Pipe 方式,确实它的效率高很多。

这是我们抽上来之后,在集团层的一个数据湖的概念。我们的数据湖大致是这么设计的:我们在集团数据湖有一个主库收上来,同时我们形成了 n 个功能库,功能库包括了我的所有的,有 20 多个基地的所有的故障特征,全部会放在这个库里。我们每个基地一天的故障事件,大概是从几十条到几百条不等,那么所有这些故障事件所涉及到的相关数据,我们都会抽上来。然后还有一个库是 AI 训练库,那么这些都是一些,我们把它叫功能库。同时还专门做了一个叫备份库,这个当时也是因为我们是在云上,为了保险起见,我们还专门做了备份库的一个数据。那么在每个基地的数据湖,就是一个主库加一个功能库,再加一个备份库,功能库主要还是做同步库用。

应该说在今年下半年,大概是从 7 月份还是 8 月份开始,我们是在两个月之内就完成了我们全宝武集团,接近 20 个基地数据底座的替换,直接就全部换 IoTDB 了。我们这个效果还是非常明显,我们把它总结了几个词:性能提升了 1 个量级、存储成本大幅地下降、运维的手段丰富了、数据的资产汇聚了、AI 模型训练加速,这些是有效的一些成果。
我们可以看一下最底下,存储成本:压缩比基本上通过实际实践,我们压缩比能实现 7 到 8 倍,是普遍的能实现的压缩的一个成绩。特别还有一个信号数据,待会还要单讲一下,信号数据其实这个存储成本是非常高的,那么通过这个 IoTDB,我们也是得到了一个提升。
运维手段:我们的备份策略、清理策略都是可以策略化的了,而不是像之前的方式,非常的僵化、非常的暴力,现在我们可以有一种非常灵活的策略化的方式来处理,也有一些比较丰富的指标、监测信息。
性能指标:写入的速度我们基本上达到 1 秒 100 万点,现在是没有任何问题。查询的速度,现在我们一年的这个数据,我们基本上在基地测试是秒级数据为主,在边缘侧我们还会有毫秒级,秒级数据一年的数据量,大概我们的查询时间就是在秒级,这个应该说提升还是非常明显,用户基本上对这一点的体验也是非常好的。包括这个加工的速度,因为有相对比较丰富的一些聚合函数,那么我们基于聚合函数做的很多加工的这种场景也丰富了。同时它这个加工的速度好了之后,我们就可以上规模的去运用,这个以前其实还是非常大的一个痛点。汇聚速度,我们现在数据的抽取也流畅了。
所以整个一来,这底下的水就活了,整个湖它就通了,不至于像之前是束手束脚,所以说这个对我们的助力还是非常大的。所以说我们讲数据加模型,有了数据你才能谈模型,没有数据,那模型就是空中楼阁了。
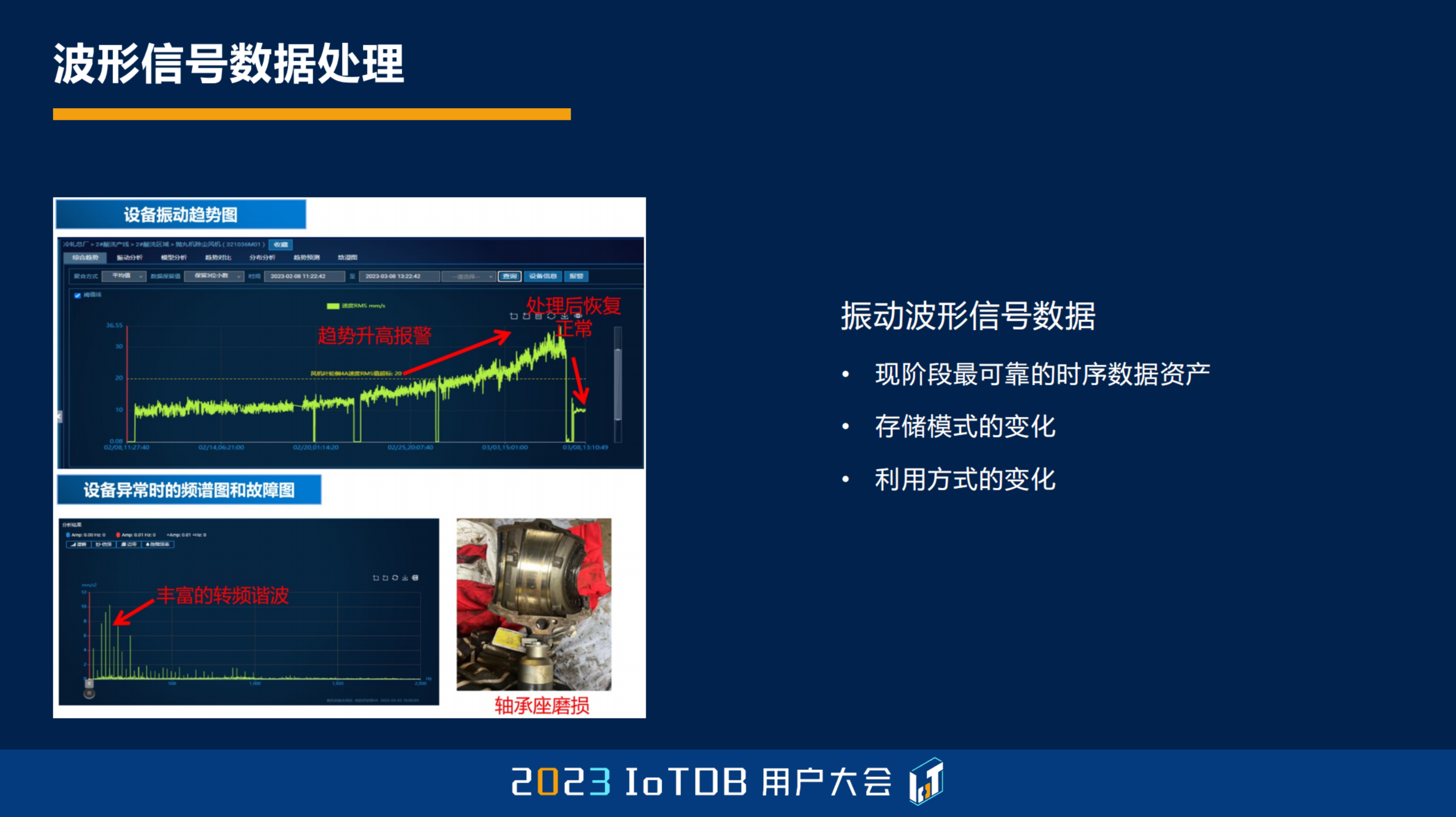
包括我们在这里面对波形信号数据的处理。刚才我讲了,其实在我们冶金行业里面,振动波形现阶段应该是要最可靠的一种时序数据资产。我们一般数据分两类,一类是所谓的供应量数据,通过 PLC、DCS 采上来的,另外一类是通过加装大量的,比如温振传感器,采集上来的。实际上我们的振动传感器数据装了很多,这些数据在我们基地,原来在 OpenTSDB 的时候,大部分它是对象存储的方式存到 HBase 里面去,它的存储的量大概在某些基地还要占到 20:1,就是存储了一个基地的数据,有 20 份都是振动数据,有 1 份才是供应量数据。
那么我们在这个 IoTDB 引入之后,其实这是一个 IoTDB 公司(天谋科技)技术人员给我们提了一个建议,我们实践下来感觉是非常好的,就是把这个振动数据不再当对象进行存储,而是直接把它拆散之后,用纳秒级的方式以后,存到我们的 IoTDB 去。存进去之后,存储模式发生变化之后,我们的应用模式也发生变化。我们可以直接在 IoTDB 层面上对这些波形数据进行它的处理,这个我们认为是非常颠覆性的一个设计。在我们的很多应用场景里面,一个是压缩比很高,另外一个,真正的把数据当成时序数据来进行管理,可以做很多的一些数据加工。
还有些创新应用场景。刚才讲的,数据有了之后,我们大量抽取上传之后,我们的 AI 团队从找数据,现在是要数据了。数据有了之后,我们列了一些数据湖的场景,我们正在做的,包括一些通用数据集的自动构建,自动标签化;包括基于同类故障的数据集的构建;同类设备的数据集的构建;振动信号的特征提取;趋势特征的提取;数据对齐和数据融合;还有文本对象数据集的构建;还有我们有个 AI 平台,和我们 IoTDB 的一个双向通讯。这些时间所限,我不细讲了,但这些就是说有了这么一个流畅的数据湖之后,那么我们在数据的应用上面才有一个更大的发展空间。

04 展望
最后来讲讲我们的一个展望部分。宝武智维计划在明年,大概会有这几方面会做一些研究,包括一些视图功能,因为这是天谋科技给我们宣讲的一个很重要的功能。我们准备切实结合着我们的需求,比如第一个,我们叫测点数据的一个扁平化。我们都知道天谋的数据,实际上它是一个 root,对吧?实际上是一个树的结构。但是我们在现实中确实碰到一个很大的问题,就是在很多业务场景,随着这个测点,数据的应用它是需要视图的再组织的,就是我们不单是从设备运维的角度,需要从生产角度、质量角度,不同的角度来组织这个数据资产,而在测点数据项这个本身,回归它的存数据的本色。从业务的视角来再组织成 n 棵树,这是我们目前想得非常多的一个刚需的场景。
还有一个就是中台功能上的一个应用。我们在进行一个叫通用数据 API 和专用数据 API 的一个研发,那么形成我们的这个数据资产管理之后,会在这个数据中台之上,做 APP 的轻量化,以及数据可视化的一些自主探索。
还有一个是 UDF 函数。因为我们目前,IoTDB 在宝武里面还只是将数据底座部署完成,包括查询性能、写入性能、抽取性能都很好,UDF 函数其实我们还没有真正大规模地应用,我们计划明年要用,为什么呢?其实在宝武,我们有沉淀了很多的算法,比如光振动波形,我们就归纳了有 6 大类、将近 35 种振动波形的算法,原来通通都是外挂的 Python 程序,需要诊断分析时去外部调用的。那么我们看了看 UDF,我们计划明年就是针对于振动波形、信号数据、长周期的趋势分析等关键场景,要研发这个 UDF 自定义函数,内嵌到我们的数据湖当中。结合着数据 API、AI 模型,全面提升我们工业数据的应用分析能力。
还有最后一个,也是我们这个宣讲中的 AINode。我们看看明年是不是有这么一个机会,通过这个 AI 节点的引入,提供机器学习推理框架,支持 IoTDB 内部来做。因为原来这块东西,传统方式其实我们还是通过一些数据的再组织抽取上来,在外面再进行这个训练的,这个流程肯定要长一些。所以说 AINode,特别是基于纯数据的特征,那么它到底能做到什么样的程度?我们也是拭目以待。
好,今天我的分享就到这里,谢谢!

更多内容推荐:
• 了解更多 IoTDB 应用案例
• 回顾 IoTDB 2023 大会全内容


