
AINode
AINode
AINode is a native IoTDB node that supports the registration, management, and invocation of time-series-related models. It comes with built-in industry-leading self-developed time-series large models, such as the Timer series developed by Tsinghua University. These models can be invoked through standard SQL statements, enabling real-time inference of time series data at the millisecond level, and supporting application scenarios such as trend forecasting, missing value imputation, and anomaly detection for time series data.
Available since V2.0.5.1
The system architecture is shown below:
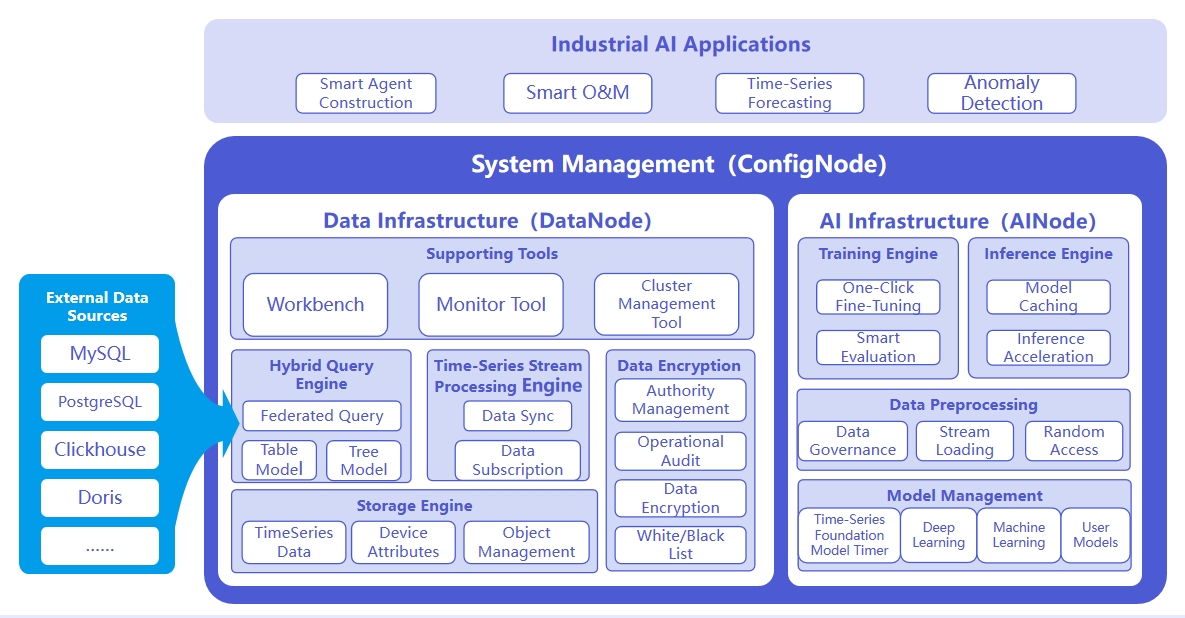
The responsibilities of the three nodes are as follows:
- ConfigNode:
- Manages distributed nodes and handles load balancing across the system.
- DataNode:
- Receives and parses user SQL queries.
- Stores time-series data.
- Performs preprocessing computations on raw data.
- AINode:
- Manages and utilizes time-series models (including training/inference).
- Supports deep learning and machine learning workflows.
1. Advantageous features
Compared with building a machine learning service alone, it has the following advantages:
Simple and easy to use: no need to use Python or Java programming, the complete process of machine learning model management and inference can be completed using SQL statements. Creating a model can be done using the CREATE MODEL statement, and using a model for inference can be done using the SELECT * FROM FORECAST (...) statement, making it simpler and more convenient to use.
Avoid Data Migration: With IoTDB native machine learning, data stored in IoTDB can be directly applied to the inference of machine learning models without having to move the data to a separate machine learning service platform, which accelerates data processing, improves security, and reduces costs.
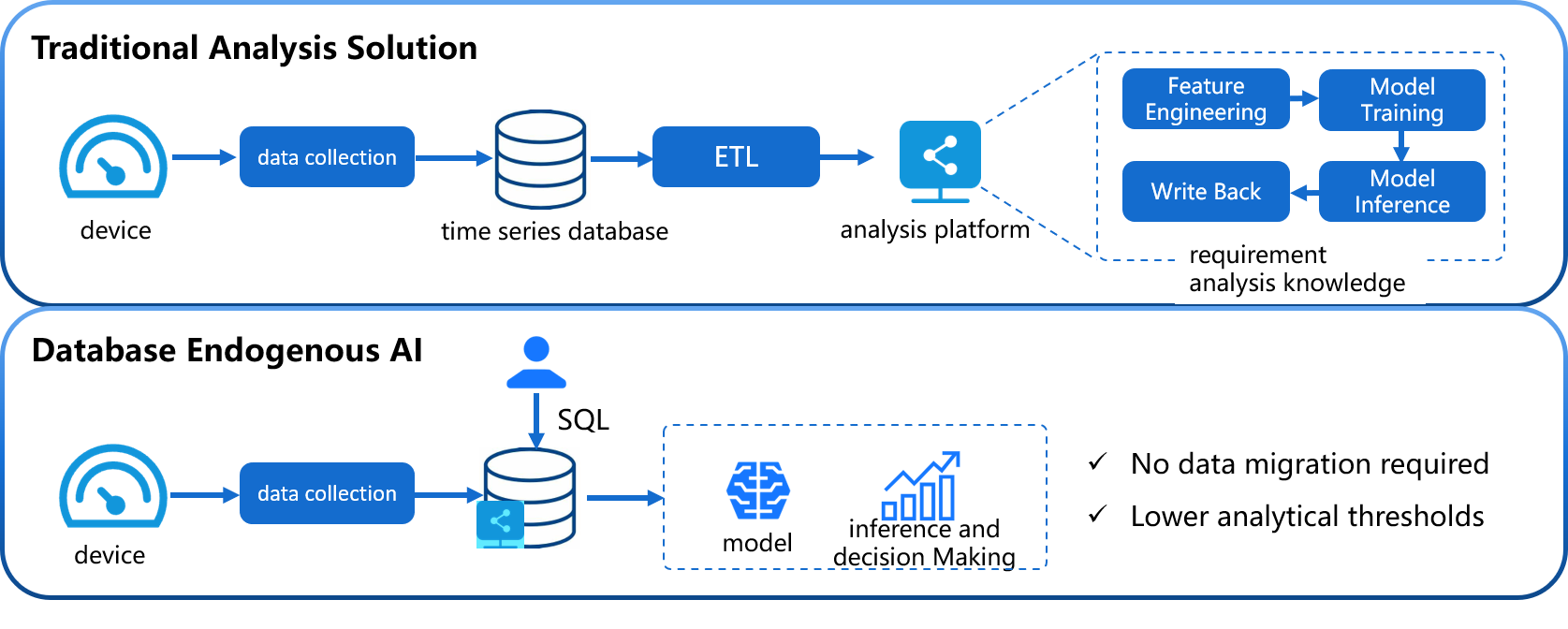
- Built-in Advanced Algorithms: supports industry-leading machine learning analytics algorithms covering typical timing analysis tasks, empowering the timing database with native data analysis capabilities. Such as:
- Time Series Forecasting: learns patterns of change from past time series; thus outputs the most likely prediction of future series based on observations at a given past time.
- Anomaly Detection for Time Series: detects and identifies outliers in a given time series data, helping to discover anomalous behaviour in the time series.
- Annotation for Time Series (Time Series Annotation): Adds additional information or markers, such as event occurrence, outliers, trend changes, etc., to each data point or specific time period to better understand and analyse the data.
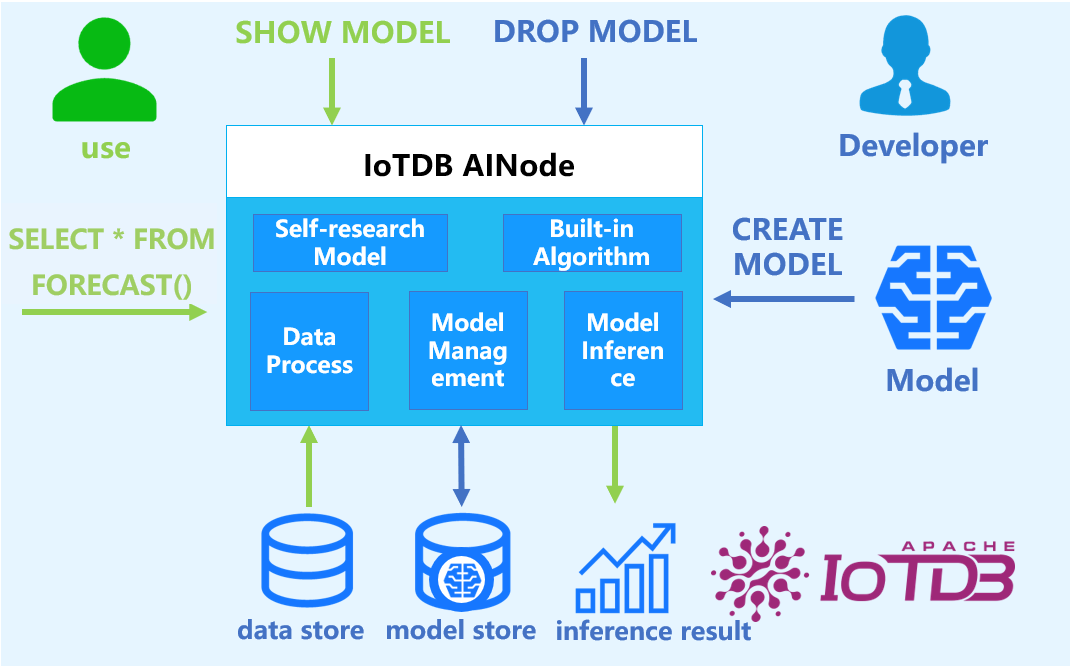
2. Basic Concepts
- Model: A machine learning model takes time series data as input and outputs analysis task results or decisions. Models are the basic management units of AINode, supporting model operations such as creation (registration), deletion, query, modification (fine-tuning), and usage (inference).
- Create: Load externally designed or trained model files/algorithms into AINode for unified management and usage by IoTDB.
- Inference: Use the created model to complete time series analysis tasks applicable to the model on specified time series data.
- Built-in Capabilities: AINode comes with machine learning algorithms or self-developed models for common time series analysis scenarios (e.g., forecasting and anomaly detection).
3. Installation and Deployment
The deployment of AINode can be found in the document AINode Deployment .
4. Usage Guide
AINode provides model creation and deletion functions for time series models. Built-in models do not require creation and can be used directly.
4.1 Registering Models
Trained deep learning models can be registered by specifying their input and output vector dimensions for inference.
Models that meet the following criteria can be registered with AINode:
- AINode currently supports models trained with PyTorch 2.4.0. Features above version 2.4.0 should be avoided.
- AINode supports models stored using PyTorch JIT (
model.pt), which must include both the model structure and weights. - The model input sequence can include single or multiple columns. If multi-column, it must match the model capabilities and configuration file.
- Model configuration parameters must be clearly defined in the
config.yamlfile. When using the model, the input and output dimensions defined inconfig.yamlmust be strictly followed. Mismatches with the configuration file will cause errors.
The SQL syntax for model registration is defined as follows:
create model <model_id> using uri <uri>Detailed meanings of SQL parameters:
model_id: The global unique identifier for the model, non-repeating. Model names have the following constraints:
- Allowed characters: [0-9 a-z A-Z _] (letters, digits (not at the beginning), underscores (not at the beginning))
- Length: 2-64 characters
- Case-sensitive
uri: The resource path of the model registration files, which should include the model structure and weight file
model.ptand the model configuration fileconfig.yamlModel structure and weight file: The weight file generated after model training, currently supporting
.ptfiles from PyTorch training.Model configuration file: Parameters related to the model structure provided during registration, which must include input and output dimensions for inference:
Parameter Name Description Example input_shape Rows and columns of model input [96,2] output_shape Rows and columns of model output [48,2] In addition to inference, data types of input and output can also be specified:
Parameter Name Description Example input_type Data type of model input ['float32', 'float32'] output_type Data type of model output ['float32', 'float32'] Additional notes can be specified for model management display:
Parameter Name Description Example attributes Optional notes set by users for model display 'model_type': 'dlinear', 'kernel_size': '25'
In addition to registering local model files, remote resource paths can be specified via URIs for registration, using open-source model repositories (e.g., HuggingFace).
Example
The example folder contains model.pt (trained model) and config.yaml with the following content:
configs:
# Required
input_shape: [96, 2] # Model accepts 96 rows x 2 columns of data
output_shape: [48, 2] # Model outputs 48 rows x 2 columns of data
# Optional (default to all float32, column count matches shape)
input_type: ["int64", "int64"] # Data types of inputs, must match input column count
output_type: ["text", "int64"] # Data types of outputs, must match output column count
attributes: # Optional user-defined notes
'model_type': 'dlinear'
'kernel_size': '25'Register the model by specifying this folder as the loading path:
IoTDB> create model dlinear_example using uri "file://./example"Models can also be downloaded from HuggingFace for registration:
IoTDB> create model dlinear_example using uri "https://huggingface.co/google/timesfm-2.0-500m-pytorch"After SQL execution, registration proceeds asynchronously. The registration status can be checked via model display (see Model Display section). The registration success time mainly depends on the model file size.
Once registered, the model can be invoked for inference through normal query syntax.
4.2 Viewing Models
Registered models can be queried using the show models command. The SQL definitions are:
show models
show models <model_id>In addition to displaying all models, specifying a model_id shows details of a specific model. The display includes:
| ModelId | ModelType | Category | State |
|---|---|---|---|
| Model ID | Model Type | Model Category | Model State |
- Model State Transition Diagram
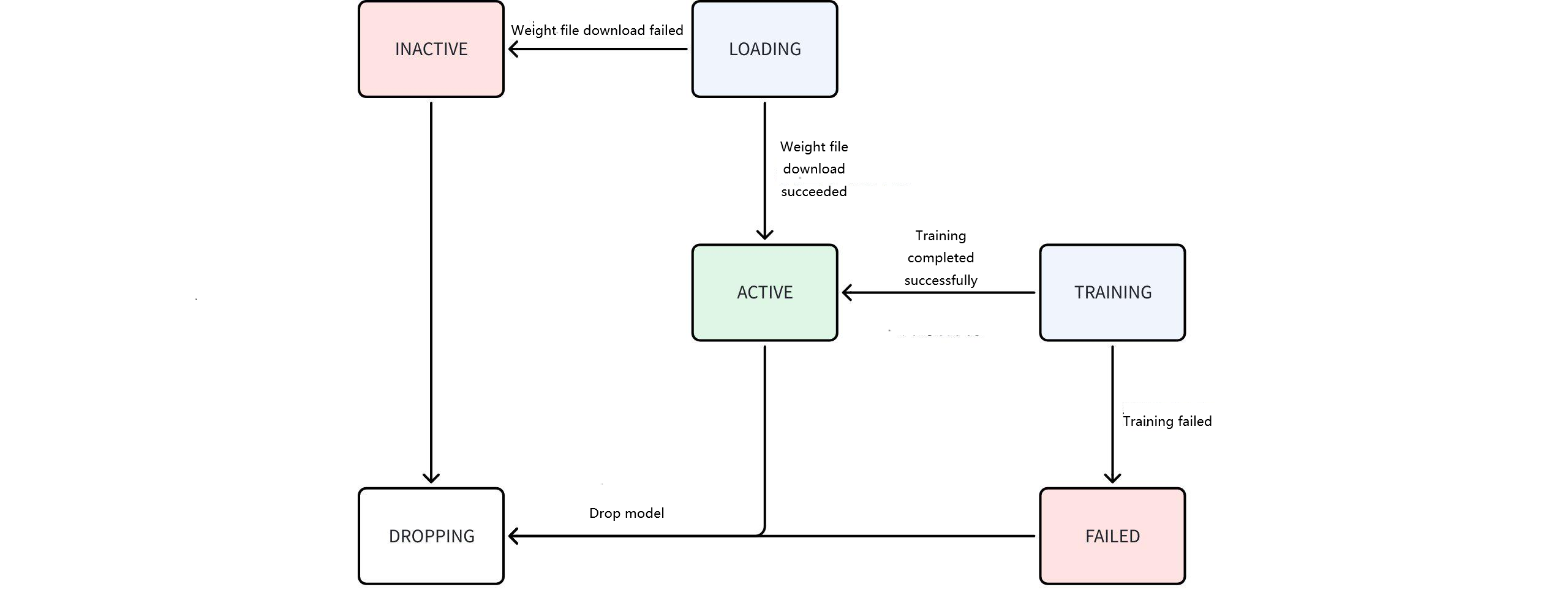
Instructions:
- Initialization:
- When AINode starts, show models only displays BUILT-IN models.
- Custom Model Import:
- Users can import custom models (marked as USER-DEFINED).
- The system attempts to parse the ModelTypefrom the config file.
- If parsing fails, the field remains empty.
- Foundation Model Weights:
- Time-series foundation model weights are not bundled with AINode.
- AINode automatically downloads them during startup.
- Download state: LOADING.
- Download Outcomes:
- Success → State changes to ACTIVE.
- Failure → State changes to INACTIVE.
- Fine-Tuning Process:
- When fine-tuning starts: State becomes TRAINING.
- Successful training → State transitions to ACTIVE.
- Training failure → State changes to FAILED.
Example
IoTDB> show models
+---------------------+--------------------+--------------+---------+
| ModelId| ModelType| Category| State|
+---------------------+--------------------+--------------+---------+
| arima| Arima| BUILT-IN| ACTIVE|
| holtwinters| HoltWinters| BUILT-IN| ACTIVE|
|exponential_smoothing|ExponentialSmoothing| BUILT-IN| ACTIVE|
| naive_forecaster| NaiveForecaster| BUILT-IN| ACTIVE|
| stl_forecaster| StlForecaster| BUILT-IN| ACTIVE|
| gaussian_hmm| GaussianHmm| BUILT-IN| ACTIVE|
| gmm_hmm| GmmHmm| BUILT-IN| ACTIVE|
| stray| Stray| BUILT-IN| ACTIVE|
| custom| | USER-DEFINED| ACTIVE|
| timerxl| Timer-XL| BUILT-IN| LOADING|
| sundial| Timer-Sundial| BUILT-IN| ACTIVE|
| sundialx_1| Timer-Sundial| FINE-TUNED| ACTIVE|
| sundialx_2| Timer-Sundial| FINE-TUNED| ACTIVE|
| sundialx| Timer-Sundial| FINE-TUNED| ACTIVE|
| sundialx_4| Timer-Sundial| FINE-TUNED| TRAINING|
| sundialx_5| Timer-Sundial| FINE-TUNED| FAILED|
+---------------------+--------------------+--------------+---------+4.3 Deleting Models
Registered models can be deleted via SQL, which removes all related files under AINode:
drop model <model_id>Specify the registered model_id to delete the model. Since deletion involves data cleanup, the operation is not immediate, and the model state becomes DROPPING, during which it cannot be used for inference. Note: Built-in models cannot be deleted.
4.4 Inference with Built-in Models
SQL syntax:
SELECT * FROM forecast(
input,
model_id,
[output_length,
output_start_time,
output_interval,
timecol,
preserve_input,
model_options]?
)Built-in models do not require prior registration for inference. Simply use the forecast function and specify the model_id to invoke the model's inference capabilities.
- Note: Inference with built-in time series large models requires local availability of model weights in the directory
/IOTDB_AINODE_HOME/data/ainode/models/weights/model_id/. If weights are missing, they will be automatically downloaded from HuggingFace. Ensure direct network access to HuggingFace.
Parameter descriptions:
| Parameter | Type | Attribute | Description | Required | Notes |
|---|---|---|---|---|---|
| input | Table | SET SEMANTIC | Input data for forecasting | Yes | |
| model_id | String | Scalar | Name of the model to use | Yes | Must be non-empty and a built-in model; otherwise, errors like "MODEL_ID cannot be null" occur. |
| output_length | INT32 | Scalar (default: 96) | Size of the output forecast window | No | Must be > 0. |
| output_start_time | Timestamp | Scalar (default: last input timestamp + output_interval) | Start timestamp of the forecast results | No | Can be negative (before 1970-01-01). |
| output_interval | Time interval | Scalar (default: inferred from input) | Time interval between forecast points (supports ns, us, ms, s, m, h, d, w) | No | If > 0, uses user-specified interval; else, infers from input. |
| timecol | String | Scalar (default: "time") | Name of the timestamp column | No | Must exist in input and be of TIMESTAMP type; otherwise, errors occur. |
| preserve_input | Boolean | Scalar (default: false) | Retain all input rows in the output | No | |
| model_options | String | Scalar (default: empty) | Model-specific key-value pairs (e.g., normalization) | No | Unsupported parameters are ignored. See appendix for built-in model parameters. |
Notes:
- The
forecastfunction predicts all columns in the input table by default (excluding the time column and columns specified inpartition by). - The
forecastfunction does not require the input data to be in any specific order. It sorts the input data in ascending order by the timestamp (specified by theTIMECOLparameter) before invoking the model for prediction. - Different models have varying requirements for the number of input data rows. If the input data has fewer rows than the minimum requirement, an error will be reported.
- Among the current built-in models in AINode:
- Timer-XL requires at least 96 rows of input data.
- Timer-Sundial requires at least 16 rows of input data.
- Among the current built-in models in AINode:
- The result columns of the
forecastfunction include all input columns from the input table, with their original data types preserved. Ifpreserve_input = true, an additionalis_inputcolumn will be included to indicate whether a row is from the input data.- Currently, only columns of type INT32, INT64, FLOAT, or DOUBLE are supported for prediction. Otherwise, an error will occur: "The type of the column [%s] is [%s], only INT32, INT64, FLOAT, DOUBLE is allowed."
output_start_timeandoutput_intervalonly affect the generation of the timestamp column in the output results. Both are optional parameters:output_start_timedefaults to the last timestamp of the input data plusoutput_interval.output_intervaldefaults to the sampling interval of the input data, calculated as: (last timestamp - first timestamp) / (number of rows - 1).- The timestamp of the Nth output row is calculated as:
output_start_time + (N - 1) * output_interval.
Example: Database and table must be pre-created
create database etth
create table eg (hufl FLOAT FIELD, hull FLOAT FIELD, mufl FLOAT FIELD, mull FLOAT FIELD, lufl FLOAT FIELD, lull FLOAT FIELD, ot FLOAT FIELD)Using the ETTh1-tab dataset:ETTh1-tab。
View supported models
IoTDB:etth> show models
+---------------------+--------------------+--------+------+
| ModelId| ModelType|Category| State|
+---------------------+--------------------+--------+------+
| arima| Arima|BUILT-IN|ACTIVE|
| holtwinters| HoltWinters|BUILT-IN|ACTIVE|
|exponential_smoothing|ExponentialSmoothing|BUILT-IN|ACTIVE|
| naive_forecaster| NaiveForecaster|BUILT-IN|ACTIVE|
| stl_forecaster| StlForecaster|BUILT-IN|ACTIVE|
| gaussian_hmm| GaussianHmm|BUILT-IN|ACTIVE|
| gmm_hmm| GmmHmm|BUILT-IN|ACTIVE|
| stray| Stray|BUILT-IN|ACTIVE|
| sundial| Timer-Sundial|BUILT-IN|ACTIVE|
| timer_xl| Timer-XL|BUILT-IN|ACTIVE|
+---------------------+--------------------+--------+------+
Total line number = 10
It costs 0.004sInference with sundial model:
IoTDB:etth> select Time, HUFL,HULL,MUFL,MULL,LUFL,LULL,OT from eg LIMIT 96
+-----------------------------+------+-----+-----+-----+-----+-----+------+
| Time| HUFL| HULL| MUFL| MULL| LUFL| LULL| OT|
+-----------------------------+------+-----+-----+-----+-----+-----+------+
|2016-07-01T00:00:00.000+08:00| 5.827|2.009|1.599|0.462|4.203| 1.34|30.531|
|2016-07-01T01:00:00.000+08:00| 5.693|2.076|1.492|0.426|4.142|1.371|27.787|
|2016-07-01T02:00:00.000+08:00| 5.157|1.741|1.279|0.355|3.777|1.218|27.787|
|2016-07-01T03:00:00.000+08:00| 5.09|1.942|1.279|0.391|3.807|1.279|25.044|
......
Total line number = 96
It costs 0.119s
IoTDB:etth> select * from forecast(
model_id => 'sundial',
input => (select Time, ot from etth.eg where time >= 2016-08-07T18:00:00.000+08:00 limit 1440) order BY time,
output_length => 96
)
+-----------------------------+---------+
| time| ot|
+-----------------------------+---------+
|2016-10-06T18:00:00.000+08:00|20.781654|
|2016-10-06T19:00:00.000+08:00|20.252121|
|2016-10-06T20:00:00.000+08:00|19.960138|
|2016-10-06T21:00:00.000+08:00|19.662334|
......
Total line number = 96
It costs 1.615s4.5 Fine-tuning Built-in Models
Only Timer-XL and Timer-Sundial support fine-tuning.
The SQL syntax is as follows:
create model <model_id> (with hyperparameters
(<parameterName>=<parameterValue>(, <parameterName>=<parameterValue>)*))?
from model <existing_model_id>
on dataset (inputSql)Example
- Select the first 80% of data from the measurement
otas the fine-tuning dataset, and create the modelsundialv3based onsundial.
IoTDB> set sql_dialect=table
Msg: The statement is executed successfully.
IoTDB> CREATE MODEL sundialv3 FROM MODEL sundial ON DATASET ('SELECT time, ot from etth.eg where 1467302400000 <= time and time < 1517468400001')
Msg: The statement is executed successfully.
IoTDB> show models
+---------------------+--------------------+----------+--------+
| ModelId| ModelType| Category| State|
+---------------------+--------------------+----------+--------+
| arima| Arima| BUILT-IN| ACTIVE|
| holtwinters| HoltWinters| BUILT-IN| ACTIVE|
|exponential_smoothing|ExponentialSmoothing| BUILT-IN| ACTIVE|
| naive_forecaster| NaiveForecaster| BUILT-IN| ACTIVE|
| stl_forecaster| StlForecaster| BUILT-IN| ACTIVE|
| gaussian_hmm| GaussianHmm| BUILT-IN| ACTIVE|
| gmm_hmm| GmmHmm| BUILT-IN| ACTIVE|
| stray| Stray| BUILT-IN| ACTIVE|
| sundial| Timer-Sundial| BUILT-IN| ACTIVE|
| timer_xl| Timer-XL| BUILT-IN| ACTIVE|
| sundialv2| Timer-Sundial|FINE-TUNED| ACTIVE|
| sundialv3| Timer-Sundial|FINE-TUNED|TRAINING|
+---------------------+--------------------+----------+--------+- The fine-tuning task starts asynchronously in the background, and logs can be viewed in the AINode process. After fine-tuning is complete, query and use the new model
IoTDB> show models
+---------------------+--------------------+----------+------+
| ModelId| ModelType| Category| State|
+---------------------+--------------------+----------+------+
| arima| Arima| BUILT-IN|ACTIVE|
| holtwinters| HoltWinters| BUILT-IN|ACTIVE|
|exponential_smoothing|ExponentialSmoothing| BUILT-IN|ACTIVE|
| naive_forecaster| NaiveForecaster| BUILT-IN|ACTIVE|
| stl_forecaster| StlForecaster| BUILT-IN|ACTIVE|
| gaussian_hmm| GaussianHmm| BUILT-IN|ACTIVE|
| gmm_hmm| GmmHmm| BUILT-IN|ACTIVE|
| stray| Stray| BUILT-IN|ACTIVE|
| sundial| Timer-Sundial| BUILT-IN|ACTIVE|
| timer_xl| Timer-XL| BUILT-IN|ACTIVE|
| sundialv2| Timer-Sundial|FINE-TUNED|ACTIVE|
| sundialv3| Timer-Sundial|FINE-TUNED|ACTIVE|
+---------------------+--------------------+----------+------+4.6 Time Series Large Model Import Steps
AINode supports multiple time series large models. For deployment, refer to Time Series Large Model
5 Permission Management
AINode uses IoTDB's authentication for permission management. Users need USE_MODEL permission for model management and READ_DATA permission for inference (to access input data sources).
| Permission | Scope | Admin (ROOT) | Regular User | Path-Related |
|---|---|---|---|---|
| USE_MODEL | Create/Show/Drop models | ✔️ | ✔️ | ❌ |
| READ_DATA | Call inference functions | ✔️ | ✔️ | ✔️ |
6 Appendix
Arima
| Parameter | Description | Default |
|---|---|---|
| order | ARIMA order (p, d, q): p=autoregressive, d=differencing, q=moving average. | (1,0,0) |
| seasonal_order | Seasonal ARIMA order (P, D, Q, s): seasonal AR, differencing, MA orders, and season length (e.g., 12 for monthly data). | (0,0,0,0) |
| method | Optimizer: 'newton', 'nm', 'bfgs', 'lbfgs', 'powell', 'cg', 'ncg', 'basinhopping'. | 'lbfgs' |
| maxiter | Maximum iterations/function evaluations. | 50 |
| out_of_sample_size | Number of tail samples for validation (not used in fitting). | 0 |
| scoring | Scoring function for validation (sklearn metric or custom). | 'mse' |
| trend | Trend term configuration. If with_intercept=True and None, defaults to 'c' (constant). | None |
| with_intercept | Include intercept term. | True |
| time_varying_regression | Allow regression coefficients to vary over time. | False |
| enforce_stationarity | Enforce stationarity of AR components. | True |
| enforce_invertibility | Enforce invertibility of MA components. | True |
| simple_differencing | Use differenced data for estimation (sacrifices first rows). | False |
| measurement_error | Assume observation errors. | False |
| mle_regression | Use maximum likelihood for regression (must be False if time_varying_regression=True). | True |
| hamilton_representation | Use Hamilton representation (default is Harvey). | False |
| concentrate_scale | Exclude scale parameter from likelihood (reduces parameters). | False |
NaiveForecaster
| Parameter | Description | Default |
|---|---|---|
| strategy | Forecasting strategy: - "last": Use last training value (seasonal if sp>1). - "mean": Use mean of last window (seasonal if sp>1). - "drift": Fit line through last window and extrapolate (non-robust to NaN). | "last" |
| sp | Seasonal period. None or 1 means no seasonality; 12 means monthly. | 1 |
STLForecaster
| Parameter | Description | Default |
|---|---|---|
| sp | Seasonal period (units). Passed to statsmodels' STL. | 2 |
| seasonal | Seasonal smoothing window (odd ≥3, typically ≥7). | 7 |
| seasonal_deg | LOESS polynomial degree for season (0=constant, 1=linear). | 1 |
| trend_deg | LOESS polynomial degree for trend (0 or 1). | 1 |
| low_pass_deg | LOESS polynomial degree for low-pass (0 or 1). | 1 |
| seasonal_jump | Interpolation step for season LOESS (larger = faster). | 1 |
| trend_jump | Interpolation step for trend LOESS (larger = faster). | 1 |
| low_pass_jump | Interpolation step for low-pass LOESS. | 1 |
ExponentialSmoothing (HoltWinters)
| Parameter | Description | Default |
|---|---|---|
| damped_trend | Use damped trend (trend flattens instead of growing infinitely). | True |
| initialization_method | Initialization method: - "estimated": Fit to estimate initial states - "heuristic": Use heuristic for initial level/trend/season - "known": User-provided initial values - "legacy-heuristic": Legacy compatibility | "estimated" |
| optimized | Optimize parameters via maximum likelihood. | True |
| remove_bias | Remove bias to make residuals' mean zero. | False |
| use_brute | Use brute-force grid search for initial parameters. |