

12 月 3 日,2023 IoTDB 用户大会在北京成功举行,收获强烈反响。本次峰会汇集了超 20 位大咖嘉宾带来工业互联网行业、技术、应用方向的精彩议题,多位学术泰斗、企业代表、开发者,深度分享了工业物联网时序数据库 IoTDB 的技术创新、应用效果,与各行业标杆用户的落地实践、解决方案,并共同探讨时序数据管理领域的行业趋势。
我们邀请到美国国家工程院院士、清华大学杰出访问教授 Chandrasekaran Mohan 参加此次大会,并做主题报告——《物联网时代的数据库挑战、技术与方向》。以下为中文翻译全文。
非常高兴能在这里与大家相聚,这是我第一次参加以 IoTDB 为主题的活动。
我和 IoTDB 的渊源还要追溯到黄向东博士进行博士论文研究的时候,也就是 IoTDB 的萌芽阶段。2014 年的时候在杭州有一个活动,期间 IoTDB 的概念首次被提及。那是一个清华大学组织的大数据峰会,我负责邀请来自中国以外的专家学者。这张照片中包括一些接下来即将作报告的嘉宾,而王建民院长是向东博士期间的导师。我从 2004 年开始就经常来清华,但直到 2014 年我才加入软件学院。我曾多次在华盛顿特区访问。如你们所见,2016 年我再次来到中国,并在那时与向东合影。可惜我只能找到刚才那一张合影了,不过接下来你们将从合影中的一些讲师那里听到更多信息。
我必须承认,IoTDB 是一项重要的成就。据我所知,当这个项目成为 Apache 孵化项目时,这是第一个由一所中国大学提交的项目,并且后来晋升为顶级项目,这是一项重大的成就。特别要祝贺向东和所有其他为此做出贡献的人,不仅对来自中国的开发者,还有来自德国和其他地方的协作者。因此,你们应该将这看作是中国社区发起的一项重大成就。

在接下来的演讲中,我将主要涉及数据库方面的内容,以及部分物联网和物联网数据库相关的主题。我们注意到过去多年来硬件和软件领域都产生了各种发展,包括人工智能、云技术的崛起,以及混合云和完全公共云。不过,本地部署和在数据的使用方面非常受限的情况仍然存在,而不是所有东西都已经转移到了公共云。还有随着 LLM(大规模语言模型)更加流行,你们一定一直听到关于如何将它应用于数据库等方面的讨论。
此外,陆续有新的政策出台,有些已经实施,也有一些即将实施,这将影响各个公司的运营方式,特别是在西方,这要归功于 HIPAA 法规、《通用数据保护条例》(GDPR) 以及新的旨在监管人工智能的法案等。因此,在系统设计中肯定需要考虑所有这些因素。

我从不同的分析机构那里收集了一些信息,包括 Gartner、IDC 等公司。这张图片显示了 Gartner 对于今年及以后新兴技术和趋势的预测,他们提供了各种信息。你们会看到一些与本次会议主题相关的内容,比如边缘计算视图、边缘人工智能,以及超大规模边缘计算等。在休息时间或者会后,你们可以有充足的时间查看幻灯片并仔细研究这些图表。
重要的一点是,更多人需要真正了解这些分析报告所传递的信息,因为数据库系统的用户在很大程度上会受到这些专家的影响。从某种意义上说,中国公司必须要在宣传和推广上下更多功夫,向这些分析机构和具有影响力的人员传达更多信息,特别是对中国以外的地方。如果在座的听众想要帮助公司拓展中国以外的市场,你们需要注意到这一点,即使你们是技术而非商务人员,即使是程序员也应该关注这些事情。我一直是技术人员,但我也还是要关注这些事情。我在 IBM 研发部门工作了 38 年半的时间,那是关系型数据库的诞生地,也是 SQL 产生的地方,即位于加利福尼亚州圣何塞的 IBM 研究实验室。

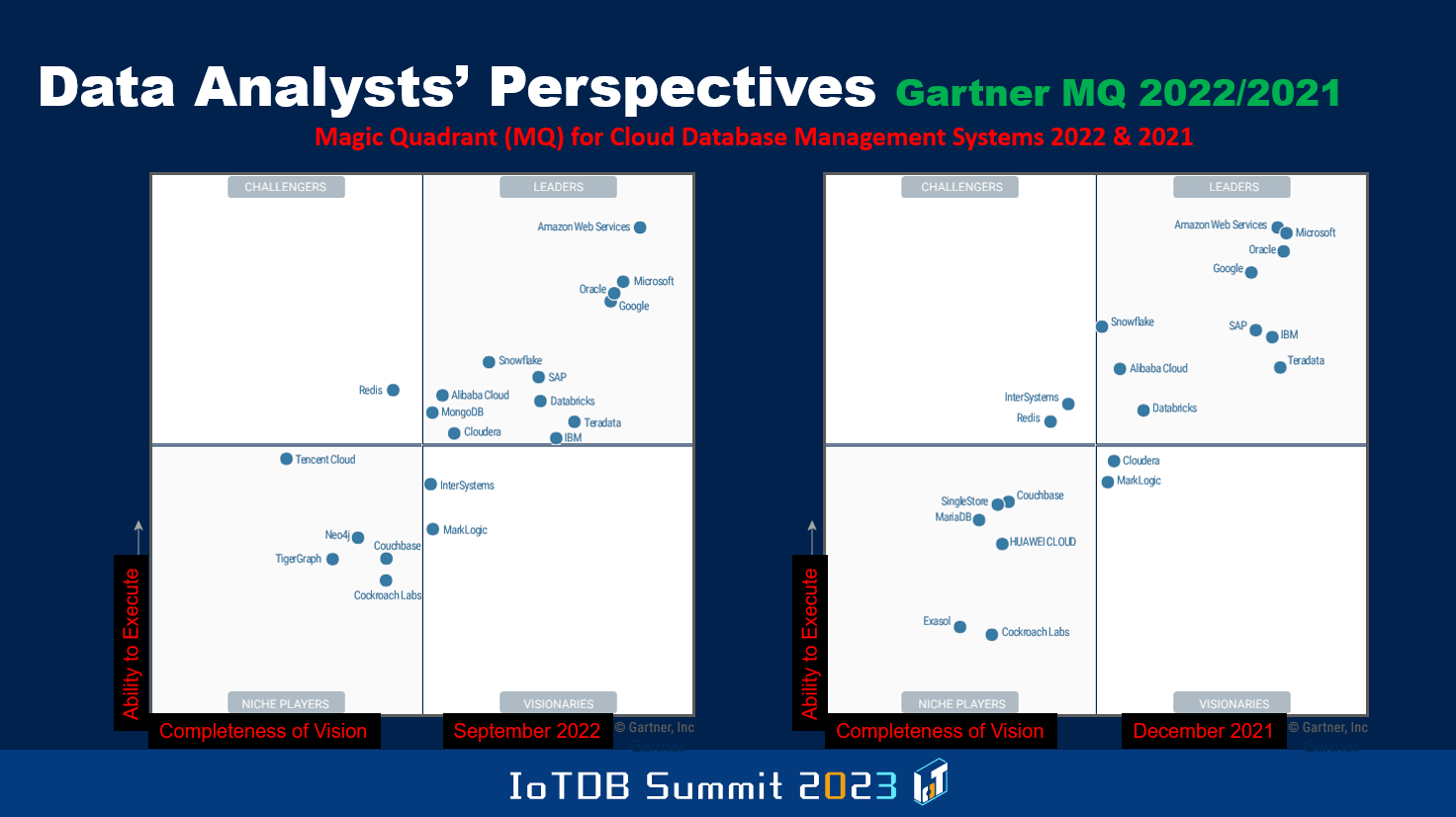
就对不同的厂商进行定位这一点而言,Gartner 每隔一段时间就会制作一份被称为"魔力象限"的图表,其中 x 轴与愿景的完整性有关,狭义与广义的愿景都会涵盖,特别是一些公司在某个领域的愿景。你们在这里看到的是云数据库管理系统厂商 2022 年和 2021 年的定位。y 轴与执行能力有关。有些公司可能有很好的愿景,但他们无法实现这个愿景,无法生产可靠的产品等等。
右上角是厂商都青睐的理想位置。如这里所展示的,由于 Gartner 定期更新这些图表,在 2021 年 12 月和 2022 年 9 月之间一些厂商的位置发生了变化。你也会在其中看到一些中国公司,比如阿里云和华为云。这类信息与表格的作用不可忽视。
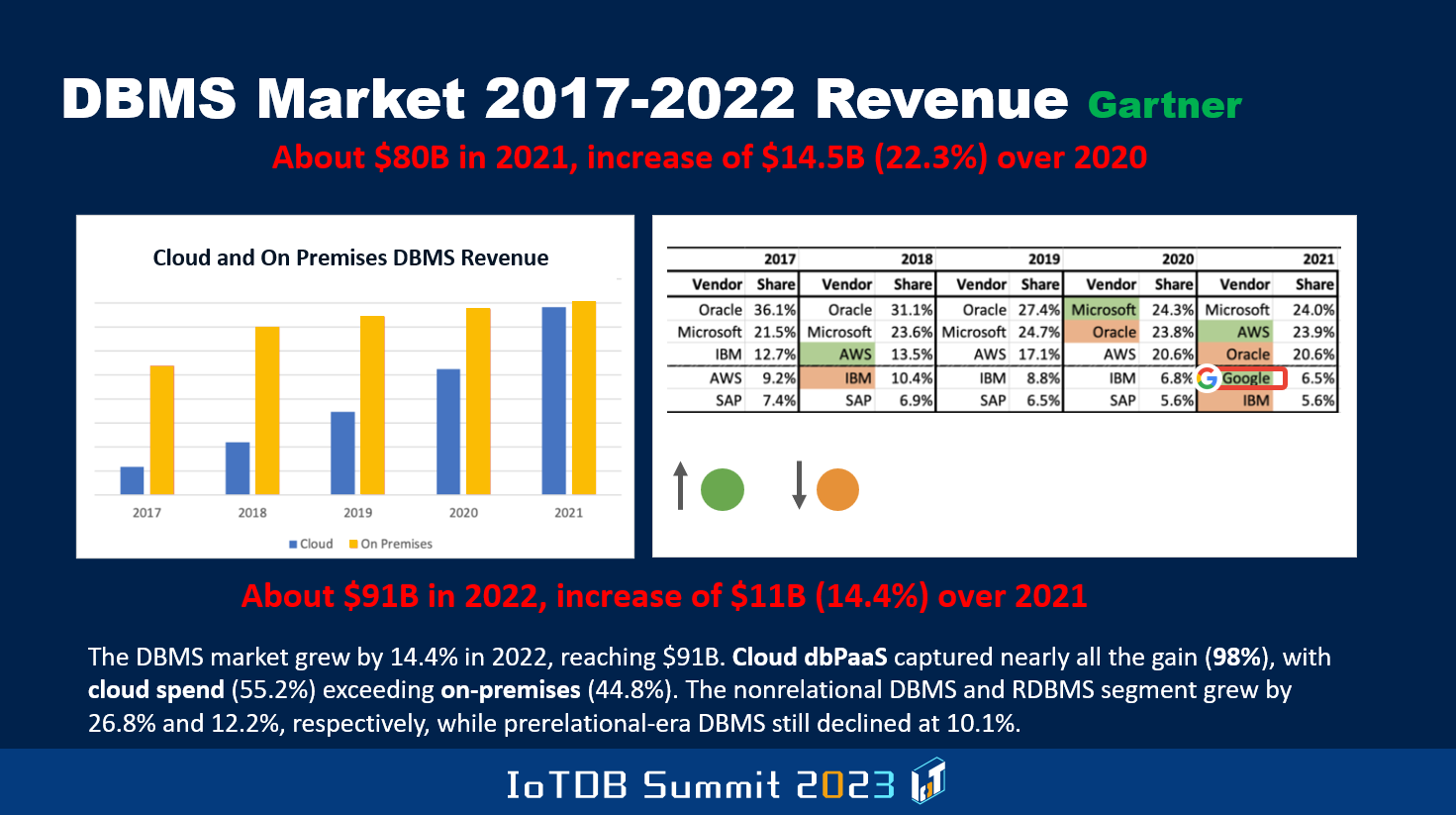
在这张图中,Gartner 展示了他们对从 2017 年到 2022 年整个数据库领域产值的估算,然后将其区分为本地部署领域与云端部署领域。随着时间推移,你可以看到云端部署的收入在整体收入中的所占比例一直在增加。整体市场规模正在扩大,但云端部署收入所贡献的比例越来越大,正如底部所示,在 2022 年已经超过了本地部署的收入。2022 年,云端数据库收入在整个数据库市场产值的占比达到了 55.2%,但你也会注意到,2022 年市场规模的增长不如 2020 年到 2021 年那么迅猛。去年,整体数据库市场规模被估计为 910 亿美元。其中一些数据是非常主观的,因此你会注意到,Gartner 和 IDC 提供的数据存在差异。
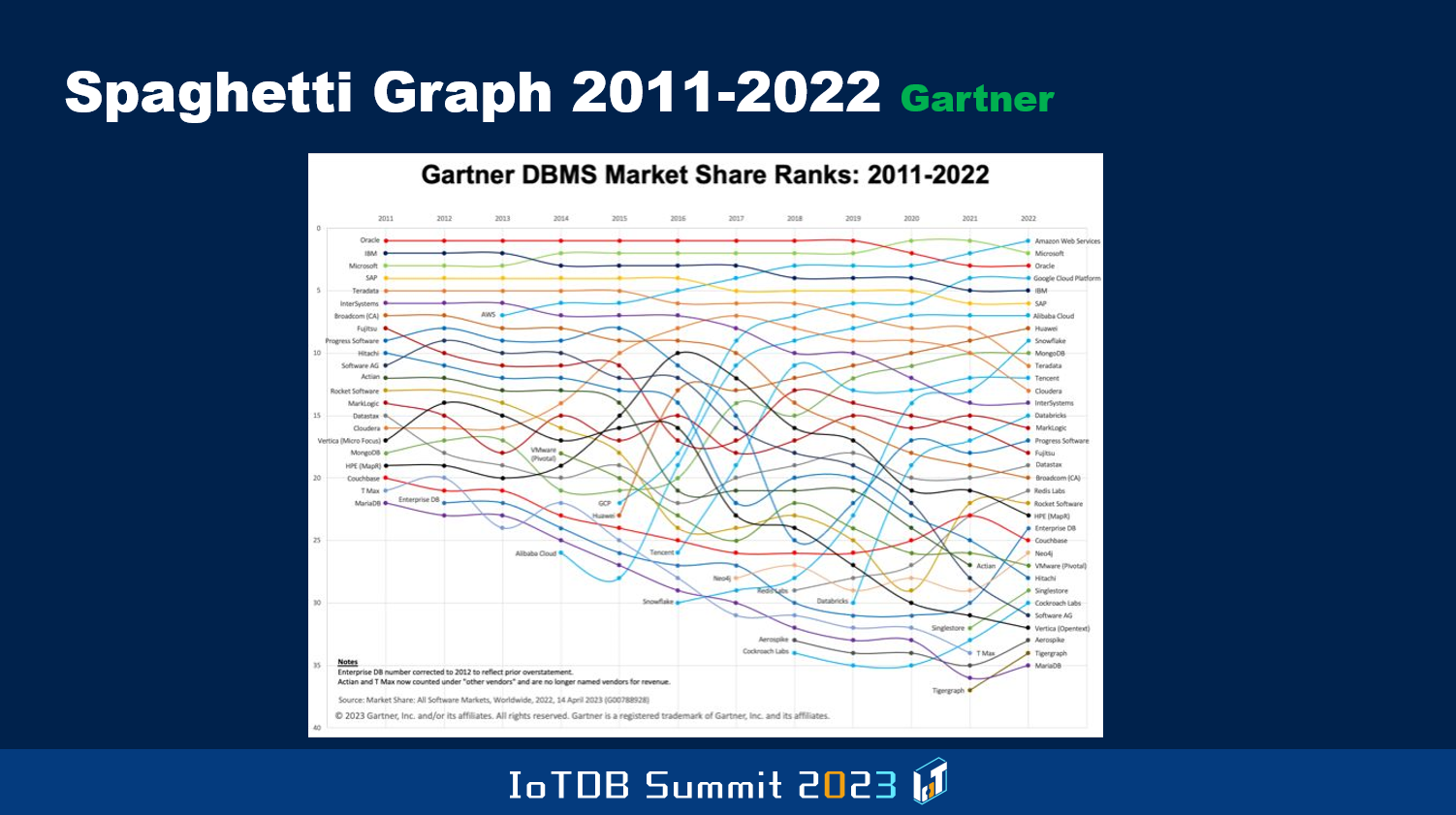
这个图表展示了从 2011 年到 2022 年不同供应商的市场份额排名情况。不知道你是否注意到,在前一个图表中展示了从 2017 年到 2021 年的前五名供应商的排名,其中在 2017 年,甲骨文曾经是第一名。然而到了 2021 年,微软取代了甲骨文成为第一名。在接下来的图表中,你会看到微软被 AWS 取代。截至 2011 年,甲骨文、IBM、微软、SAP 和 Teradata 是前五名供应商。然而,到了 2022 年,前五名变成了亚马逊、微软、甲骨文、谷歌,然后是 IBM 和 SAP。
这种图表被称为“意大利面图表”,因为它随着时间的推移的走势看起来像意大利面。它表现了在 2011 年并不存在的一些公司是怎样入局的,以及它们是如何逐渐进步的。我们也可以看到一些像 IBM 这样的参与者,市场份额下降了。再次强调,这些数字并非是由固定的算法产生的,因此来自不同供应商的结果之间会存在差异。
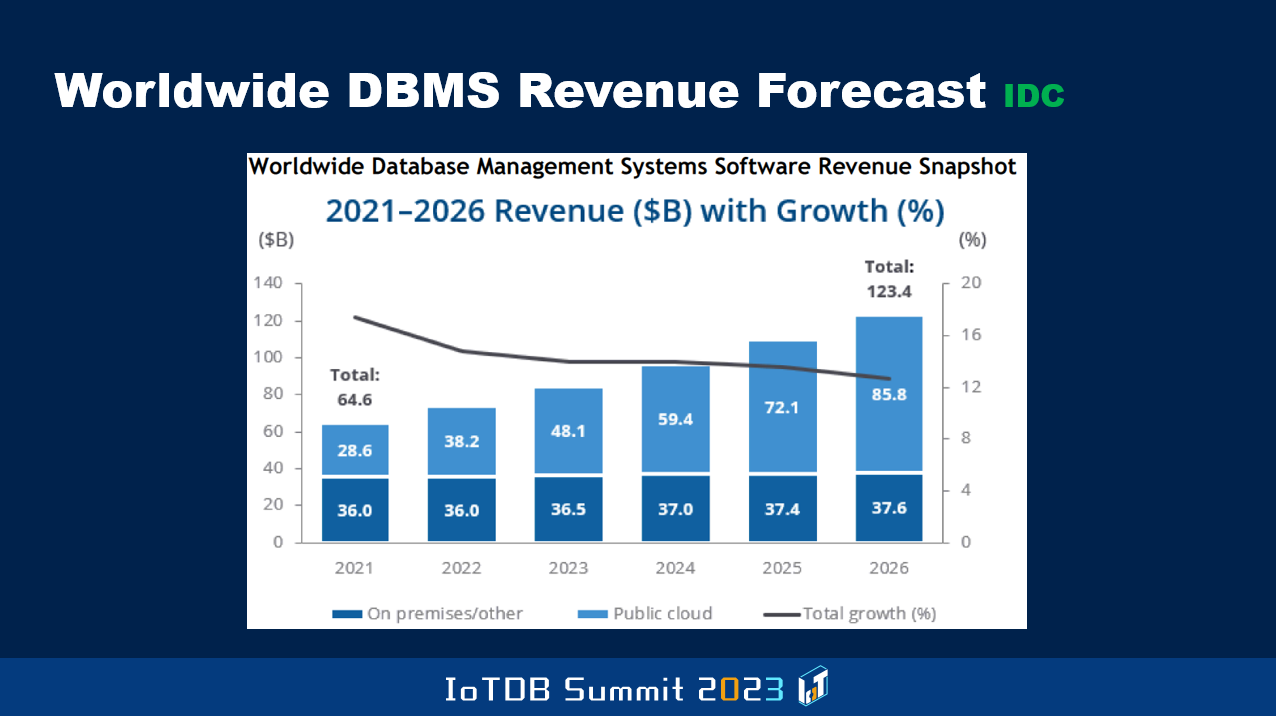
例如这张图表中,显示了 IDC 团队估计的 2021 年整体市场规模约为 646 亿美元,而前面提到的 Gartner 的估计为 800 亿美元,这是非常巨大的差异。由于涉及主观因素,这些数据在不同分析师视角中并不总是一致的。不过 IDC 团队预测到 2026 年,他们认为市场规模将达到 1230 亿美元,并表示市场增长速度将略有减缓,但仍然会继续增长。与 Gartner 的数据所显示的趋势一致,IDC 估计云端部署收入所占比例也将不断增加,以至于在 2026 年,估计云端部署收入将达到 850 亿美元,而本地部署收入将仅为 370 亿美元。
Gartner 定期制作技术成熟度曲线,即他们所谓的“炒作周期”。他们会制作不同主题的版本,其中之一就是数据管理技术成熟度曲线。这张图是在一年多前的 2022 年 6 月制作的。在这里,他们讨论了新的观念如何逐渐变得炙手可热,会有很多期望由炒作产生。但是随后实际效果不如人意,于是就有了幻灭的低谷,曲线走到最低点。最后逐渐地,一些未实现的承诺至少在某种程度上会逐步得以实现,这时将会有一个稳定的发展期。但是有一些技术会在达到成熟阶段之前就已经消失,而其他一些则需要更长的时间达到成熟等等,因此了解这些情况也是很有帮助的。
这里我将点出一些物联网强相关的领域。根据这个图表,边缘侧数据管理仍处于这个攀升阶段,而在库内分析和事件流处理方面,它们已经进入了成熟期的最后阶段,然后将趋于稳定。这意味着在这个特定的主题中不会再有太多的创新。而宽表数据库管理系统处于更加成熟的状态,诸如此类。
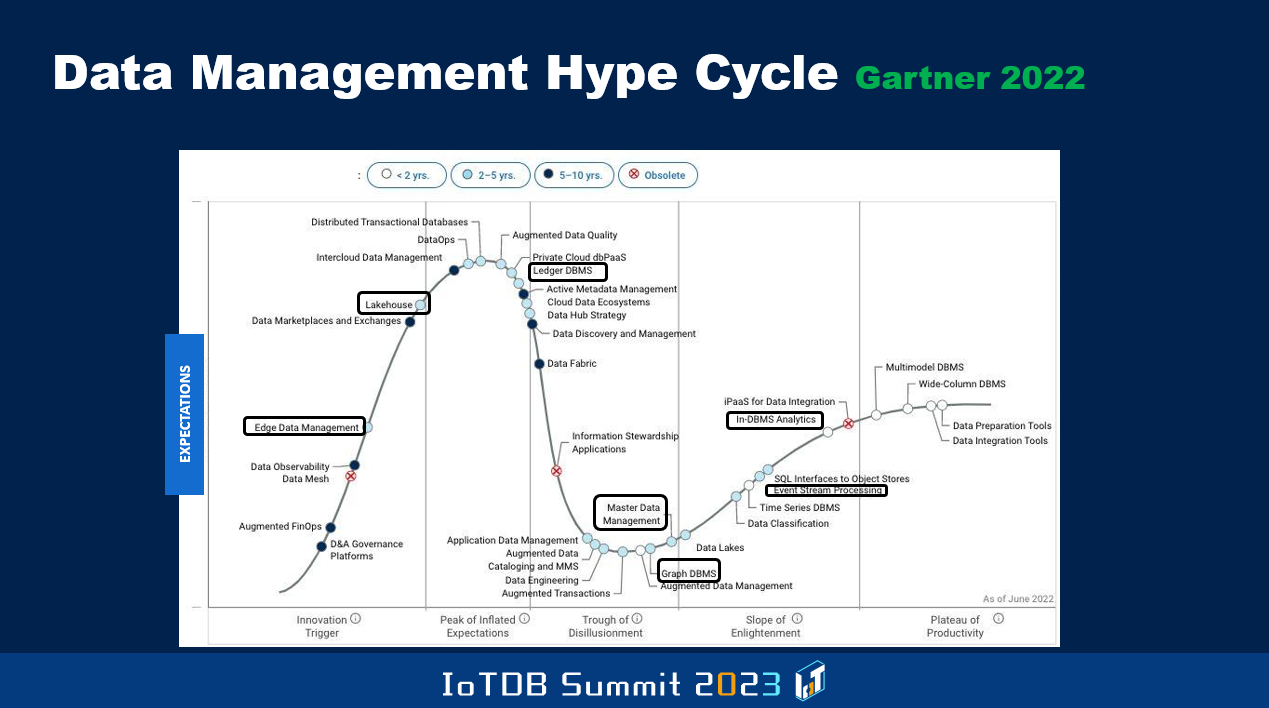
Gartner 特别在分析和商业智能(BI)的子领域内制作了一张图表,与之前那张覆盖整个数据库领域的图表不同,在这里,你可以更详细地了解与分析和商业智能相关的领域。在这里你还会注意到诸如事件流处理、边缘分析等方面的内容,这些领域正在从炒作的高峰下来,进入人们可能会因为没有满足所有炒作时设定的期望而感到失望的阶段,而预测性分析则处于更加稳定的状态朝着最终成熟阶段发展。
除此之外,表格中还囊括了不同的成熟时间周期。对于某些领域,Gartner 预计其短时间内就将趋于成熟。而对于另一些领域,Gartner 预测需要更长的时间达到成熟等等。因此在底部有一个图例,阐述了曲线中不同颜色的点的含义,不同的领域被不同的颜色标注,并不是所有的领域都是一样的成熟周期。
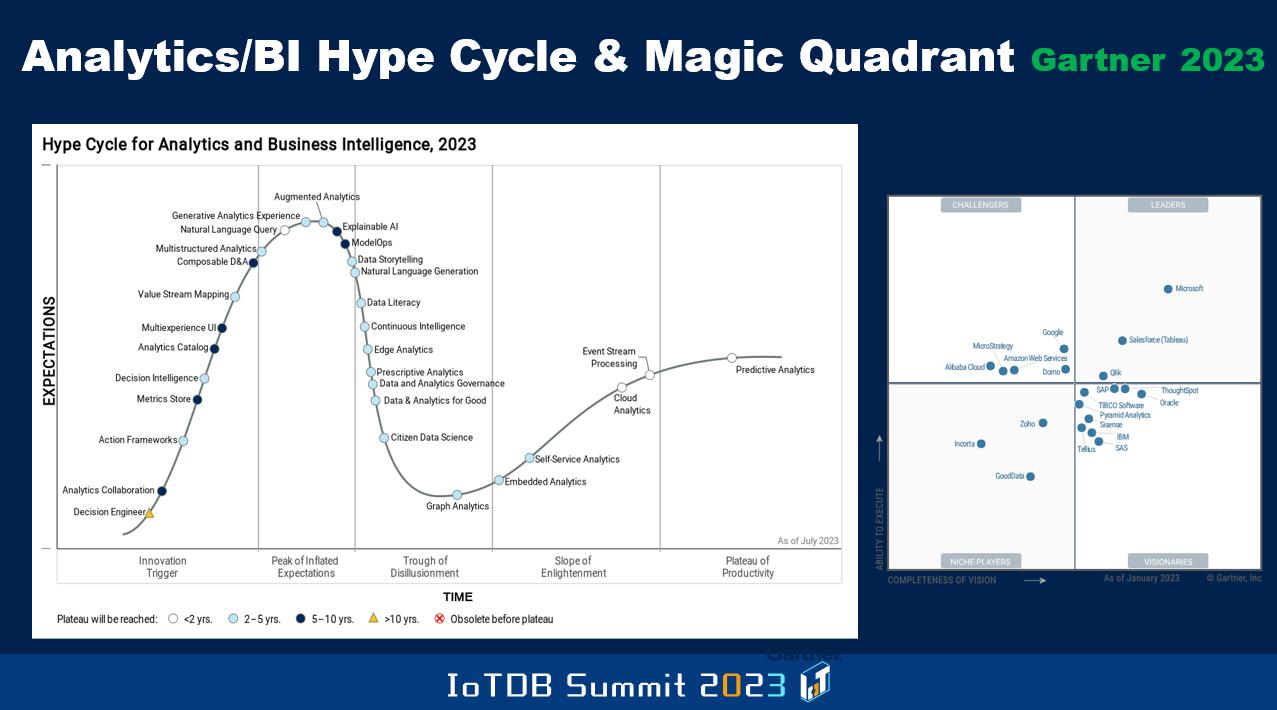
现在让我们具体看一下物联网市场。有一个名为“财富市场洞察”的机构,他们制作了这些图表。令人震惊的是,他们声称去年的物联网市场规模竟然达到了 5440 亿美元。他们预计到 2030 年,这个规模将达到 3.3 万亿美元。这是一个非常可观的市场与可能的收入规模。当然,这是整个物联网市场的规模,而其中的一个子集将是物联网数据库市场,希望你们 Timecho 公司能够从中获得不菲的收入。
作为该分析的一部分,“财富市场洞察”机构还绘制了一幅包含多种颜色的饼状图。这些是他们调查并发现的物联网领域的各种用例,例如政府、医疗、制造业、农业等。前面的演讲者提到了其中的一些,对吧?今天稍后,你们将会听到使用 Apache IoTDB 的不同用户的发言,其中也将包括交通、可持续能源等领域。
下面可以看到右侧这幅图,它来自于一个最早在 2017 年开发和发布的基准测试。这是事务处理性能委员会的物联网基准测试,被称为 TPCx-IoT。这项基准测试聚焦边缘层,然后连接到网关层,再到用于对数据进行长期存储的后端数据中心的数据链路。其目标是使物联网设备能够有效地以适当的方式与网关层进行通信。这就是 IoTDB 这类软件运行的场景。因为受到可用资源的限制,在设备上运行的客户端可能没有那么强大。我相信在后续的演讲中,你们会听到更多关于这方面的内容。
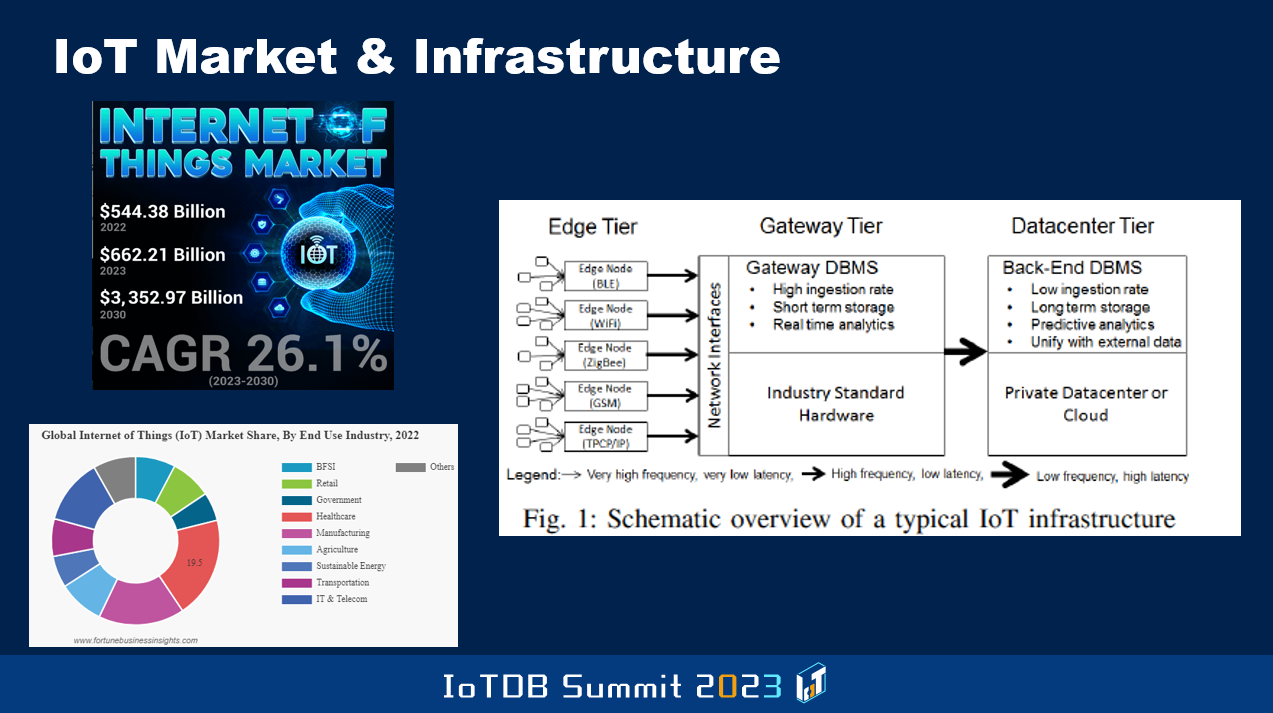
那么这个基准测试的重点是什么呢?它们选择关注制造业、发电和传输等相关用例。你在这里看到的图片体现了这个基准测试关注的行业焦点。
就在昨天,我听到了清华软件学院的一位博士生的报告,他正在评估 IoTDB 在这个基准测试中的性能表现。他计划依据基准测试对 IoTDB 进行改进,因为已经有了一些公开发表的数据,以及其他供应商的一些数据,抱歉我忘记具体的名字了,其中一个产品我甚至是前几天才第一次听说。不过有一个我较为熟知的,Cloudera。他们已经发布了一些数字,这正为后续 IoTDB 的演进提供了很好的目标。
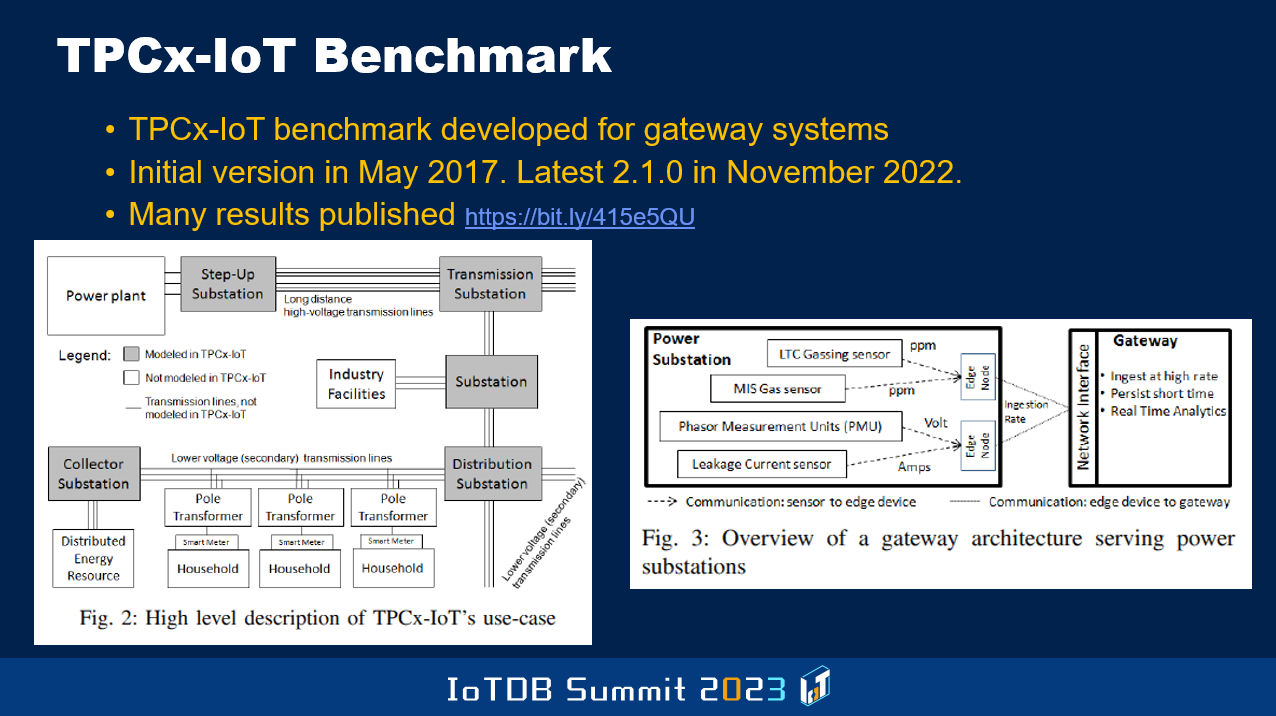
这个基准测试是借鉴了雅虎团队之前开发的一个基准测试,名为 YCSB(Yahoo Client Server Benchmark)。这里展示了这个基准测试的一些详细信息,以及它们在进行哪些测量。与典型的 TPCx 基准测试一样,它不仅关注事务速率,还关注价格性能,即需要花费多少美元才能实现一定的事务吞吐量。
可能会注意到,这整个领域并不是全新的。有些产品现在才被标记为物联网数据库,且整个领域以流处理、事件处理系统等形式已经存在很长时间了。它们不一定是在当前一些受关注的实际用例的背景下进行的,而更多是在研究背景、研究原型下进行的。
即使几十年前引入的 SQL 语言中的触发器等功能,现在也演进为与物联网领域中,对实时事项的响应相关。甚至在数据库领域内有一个子学科叫做实时数据库,我们在三、四十年前就开始研究了。但是现在像 IoTDB 这样的数据库正在将以前这些分开演进的不同功能集成在一起,成为一个软件系统,甚至是一个研究系统。这就是现在与以前行业发展的区别所在。SQL 语言也随着时间的推移发生了演变,引入了时态 SQL 等架构,而且窗口函数也已经引入 SQL 中很久了。类似的时间序列管理支持功能已经存在一段时间了,但在实际工业场景中的运用还有待发展,工业 4.0 等趋势也是推动这一切发展的动力。

这里讲到一些进行边缘端分析的原因。有时涉及主权问题,一些国家会规定关于其公民、产品或其他机械设备的信息不能被发送到境外的数据中心。所以一些云端部署的需求,可能因为在本国内并没有相关数据中心,而无法实现。因此,通过在本国内进行处理,并仅向境外发送隐藏了详细信息的聚合信息,有时可以满足这些主权要求。一些法规,如《通用数据保护条例》(GDPR)都迫使了这类的操作的实现。
当然,边缘设备与数据存储位置之间的连接可能也不够稳定。出于这些原因,用户可能希望在边缘端执行更多数据处理任务。但这是一个权衡,因为如果边缘设备没有足够强大的性能和计算能力等,你可能无法执行非常复杂的处理任务。目前的发展,可能待会儿龙明盛教授会谈到,甚至需要考虑在边缘设备上进行机器学习等方面的操作。
因此,在边缘端分析这个领域有很多需要考量的因素。当然,其中一个重要因素是,如果边缘设备需要返还一些结果,如果结果可以直接在边缘设备返回,或者通过在边缘设备缓存大量信息,以更快的方式进行返回,可以提高响应时间。

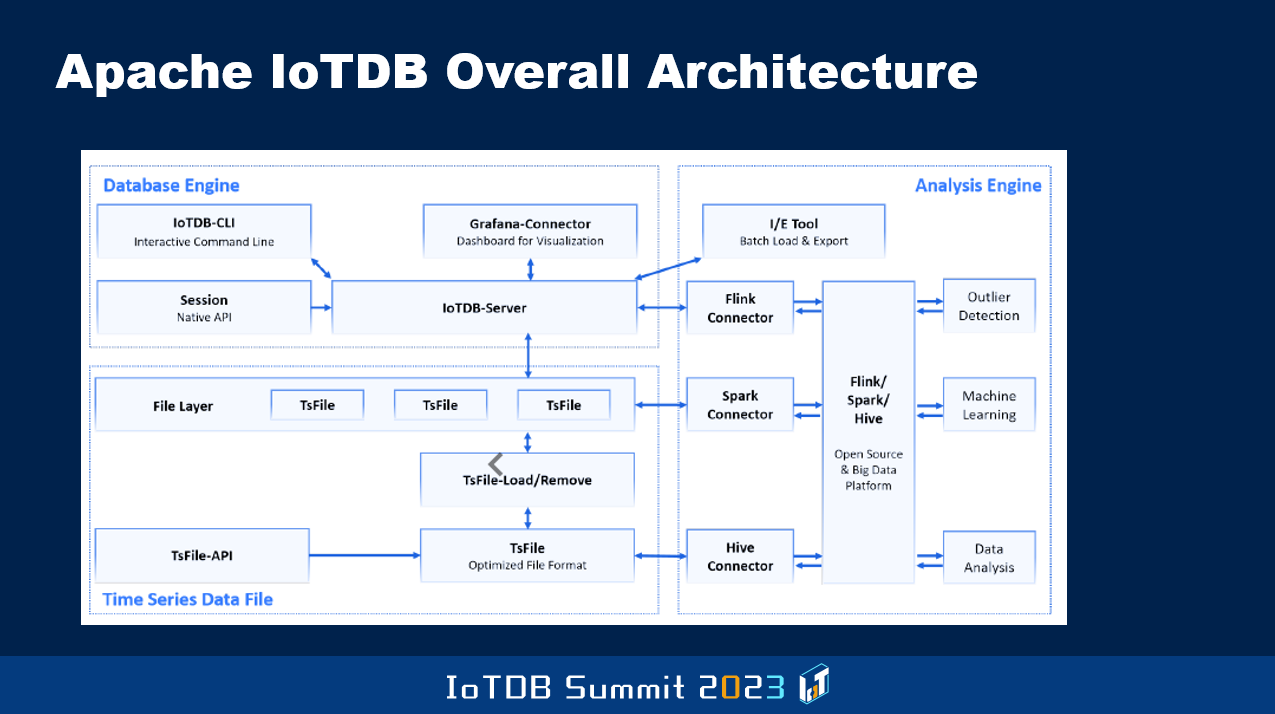
下面这张图待会儿其他人可能也会展示,它展示了 Apache IoTDB 中数据库引擎和分析引擎的整体架构,以及团队推出了一种被称为 TsFile 的新文件格式,以高效地存储压缩后的数据。这方面我就不多介绍了,请关注接下来其他讲师分享的有关 IoTDB 服务器、IoTDB 客户端及其他各类功能的详细描述,以及他们如何进行演进,数据是如何高效加载的。就在昨天,我还听到了关于其中一些内容的演讲。
总的来说,除了所有这些与物联网环境特定的内容之外,现在图数据库领域也有很大的发展势头。我列举了一些该领域的事件。有面向图的传统查询语言,以及在 SQL 中添加面向图的原语,所以一直以来,面向对象的数据库系统与面向关系的数据库系统之间存在博弈。类似地,在图数据库领域,去年 SIGMOD 发表了一篇关于 SQL/PGQ 和 GQL 语言的论文。所有这些都涉及导航式与声明式管理之间的权衡等问题。阿里巴巴也有一个叫做 GraphScope 的图计算平台。

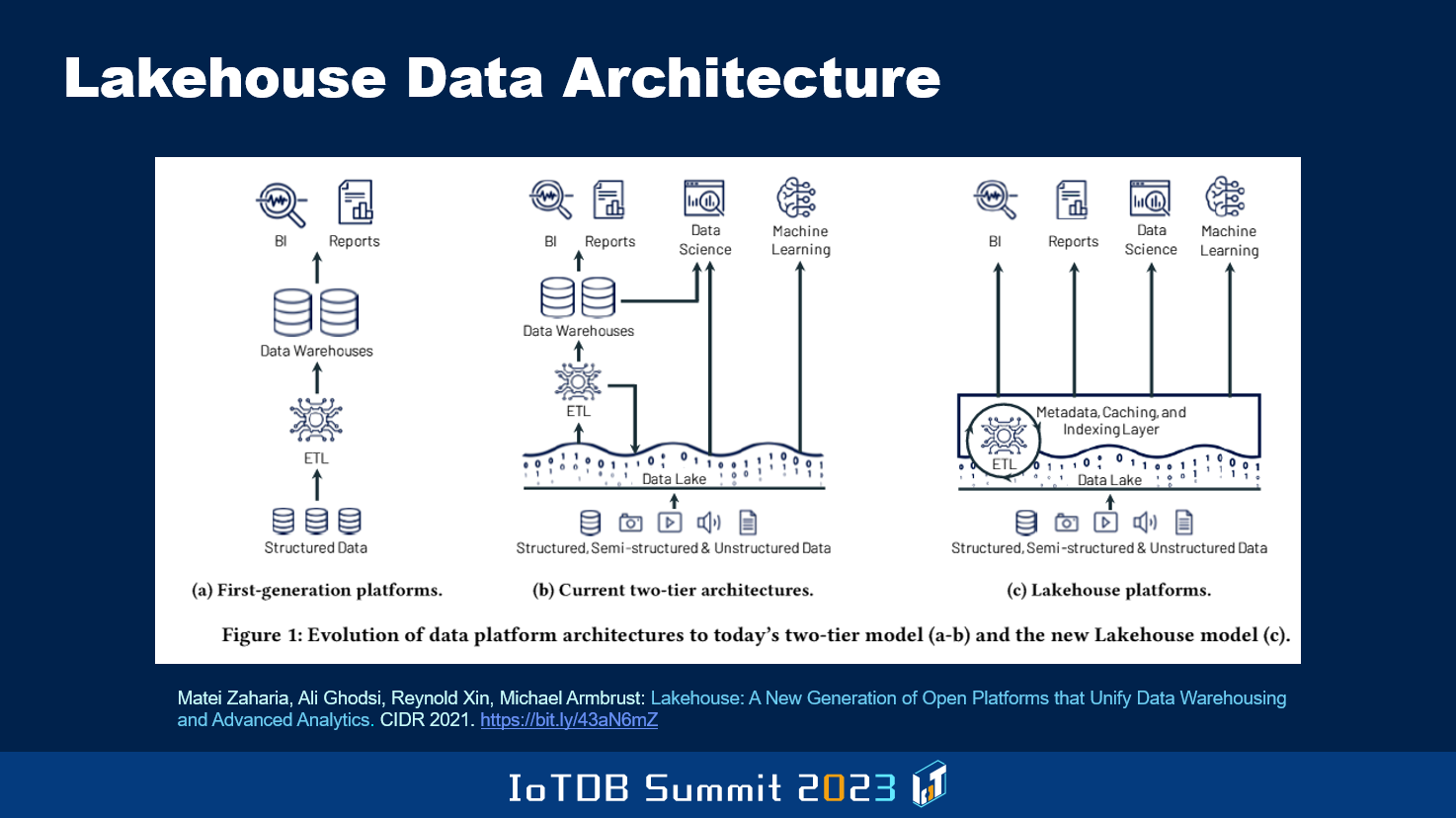
当前行业关注的另一焦点是从管理结构化数据到管理非结构化和半结构化数据的过渡,包括数据湖等基础设施。但随后人们发现,为了能够以传统处理结构化数据的方式处理数据湖中的数据,必须从数据湖中提取非结构化数据,然后使用诸如 BI、报告、机器学习等工具进行处理。Spark,也就是 Databricks 背后的团队最新提出的思想是湖仓一体(lakehouse)的概念,他们试图将以前必须通过将数据移动到更结构化的数据库管理系统环境中,进而完成的一些工作,推进到数据湖进行处理。
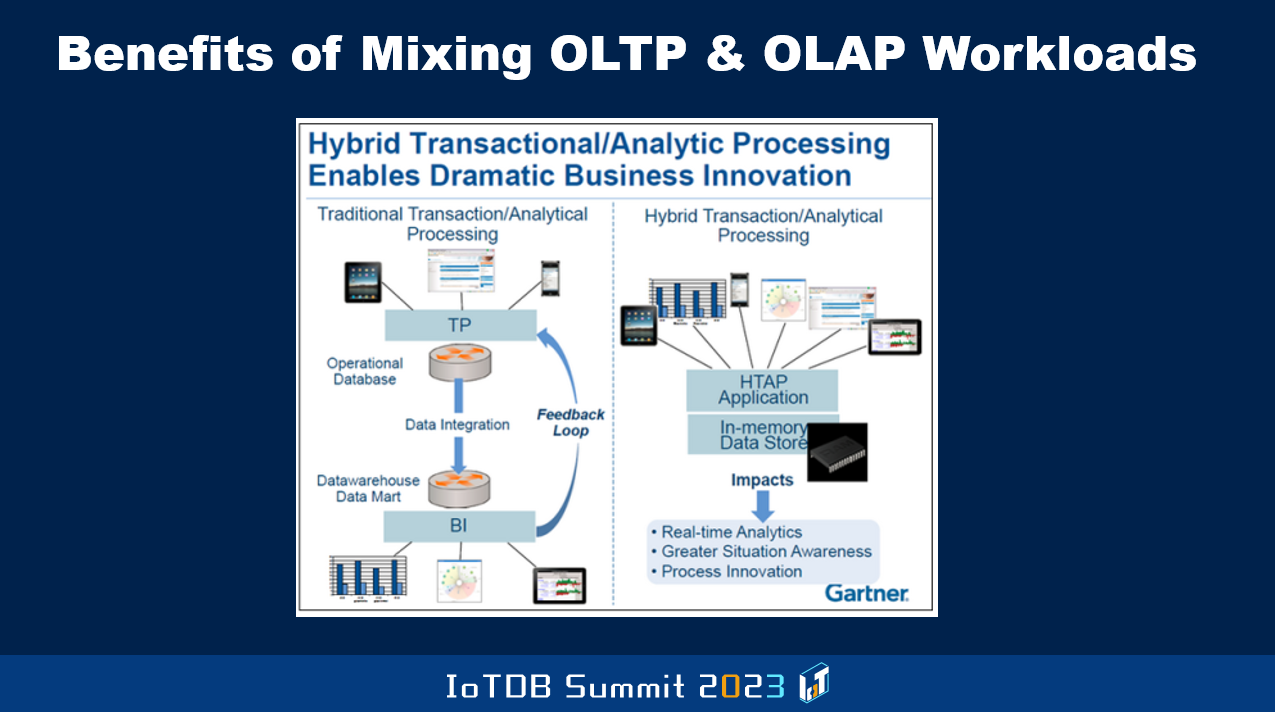
此外发生变化的事情是,传统意义上 OLTP 系统与数据仓库系统是分开的。随着新数据的写入或现有数据的修改,数据会定期地从 OLTP 系统传输到数据仓库。但这意味着如果在数据仓库上进行分析,它是基于比 OLTP 系统中的最新数据更旧的数据。解决这类问题取决于迁移数据的速度,而且还伴随着一些成本。
因此,现在的思维是所谓的混合事务和分析处理系统,也就是在同一个单一的数据库中,可以运行 OLTP 事务及长时间运行的分析类型、OLAP 类型的工作负载。对于像我这样的算法人员来说,这为数据库管理系统增加了更多复杂性,我们只能基于数据库管理系统的传统知识,试图弄清楚如何进行并发控制恢复、存储管理、索引等工作。
因此,OLTP 处理行式存储的数据效果最佳,但 OLAP 处理列式存储数据时效果最佳。现在,如果你要在同一个系统中结合这两类工作负载,该怎么办呢?一些现在应用的需求要求将这两者结合起来,因此这是一个充满创新的领域,有许多学术、应用论文成果亟待撰写,也有新的系统可以构建。一些新型的数据格式和定期以批处理方式,将数据从行式转换为列式等,都是已经在一些产品中衍生出来的想法,很遗憾我没有时间一一介绍。
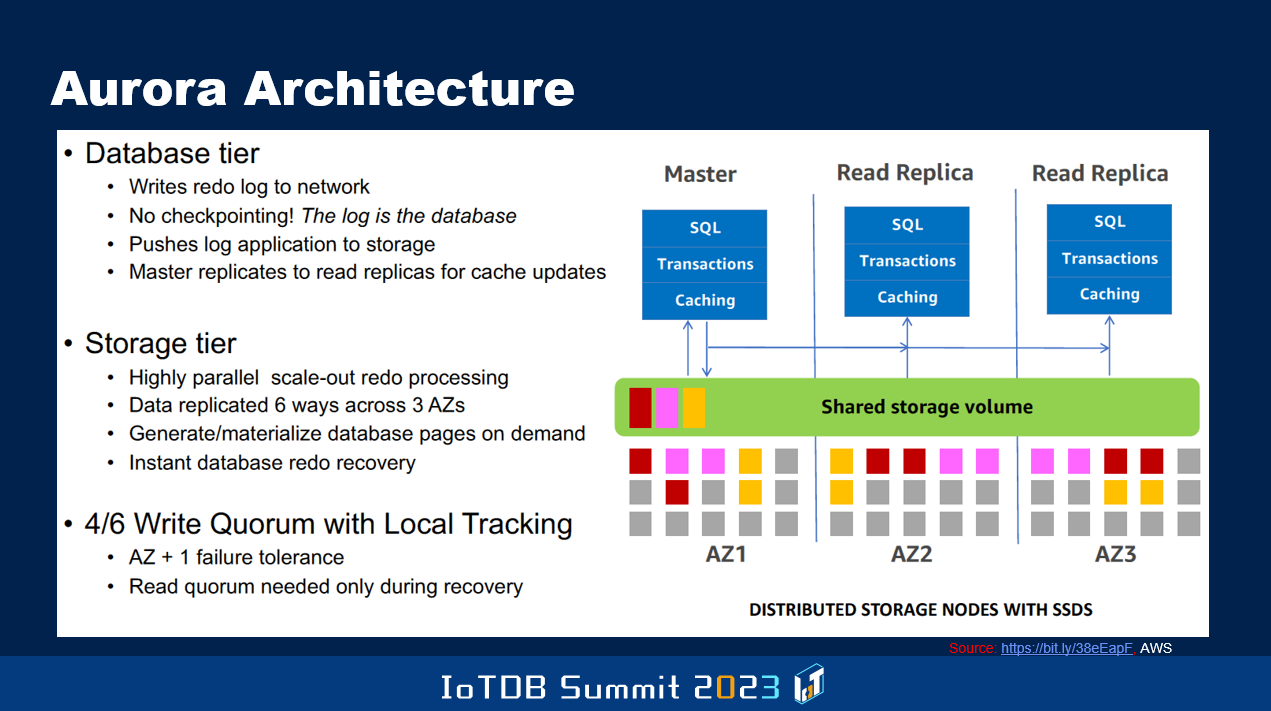
此外,其他的图表讨论了数据库领域内的一般趋势和具体趋势。一般趋势与从本地部署到云端部署的演变有关。有一些数据库在这方面经历了这种转变,例如,PostgreSQL 和 MySQL 是通过亚马逊的 Aurora 项目演变的,谷歌也做了类似的演变,称为 AlloyDB,微软也以这种方式演变了 SQL Server。
但随后出现了新的数据库系统,它们是云原生的数据库系统。有各种各样的公司在此领域变得非常活跃,特别是中国公司。与过去相比,它们现在在行业重要会议的工业赛道上不仅表现活跃,甚至在研究赛道上也是如此,在进行大量的产出。因此,我一直在告诉我生活了四十年的硅谷里的人们:“各位,留心一下其他地方发生了什么。不要老是一直看着附近,认为硅谷发生的一切就是全部。其他人可能在你们察觉之前就已经抢占了所有的市场。”
因此,在这个意义上,市场竞争的存在以及新技术的发展是件好事。我很高兴看到很多的技术演变,也很高兴看到越来越多的学者,比如王建民院长及其学生们,深度参与到中国的创业公司中来。这在过去的很长一段时间内是不太常见的,即使对于欧洲和美国等地也是如此。

有关数据存储方面还有更多趋势,比如在云环境中,分散存储的概念变得非常流行,其中存储层与计算层是动态分离的,计算层节点可以根据工作负载,分配或解除分配事务。这使得我和其他人在几十年里深耕的传统数据库架构变得复杂。正如我之前描述的,一些公司,如微软、谷歌和亚马逊,已经采取了一些非常不同的做法,不过我就不做太详细的介绍了。

当然,在机器学习领域也发生了一些变化,利用机器学习技术在数据库管理系统内部进行操作,旨在自动化处理各种数据事务,而无需数据库管理员的人工介入。

数据分析是我已经提到的另一个领域。Databricks 的团队开发了一个名为 Photon 的新查询引擎,以更好地处理我之前介绍到的湖仓一体架构。

在分布式数据库领域,也出现了很多的开源活动与事件,前面的报告中已经谈到了开源的重要性。比如苹果收购并随后开源了 FoundationDB,在该领域还有像 CockroachDB 等公司。

如我之前提到的,现在有很多云数据库管理系统。其中一些是云原生的,而另一些是本地部署版本的转化。这里有更多的细节,我就不一一介绍了。

这是在线事务处理(OLTP)类型的数据库。
这是亚马逊开发的数据仓库 Redshift。
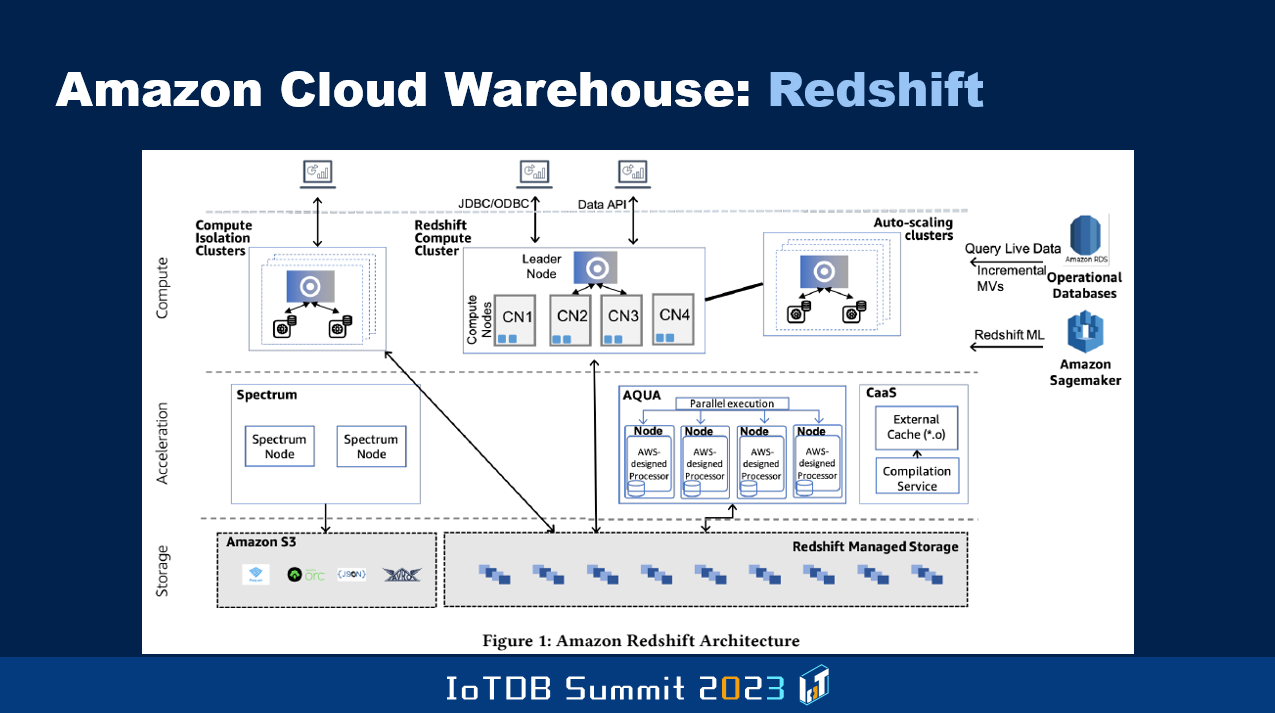
还有微软开发的 SQL Server,正如我讲过的,也正在发展演进。但是许多这类数据库有一个限制,即只能有一个节点进行读写操作,其他节点,即计算节点,只能进行读取操作。这都是古老的设计思路,我在 90 年代末曾在数据库本地部署行业中分享“多个节点可以同时具有读写功能”这样的架构。甲骨文也通过其研发的 Oracle Parallel Server 来解决这个问题。这些思想需要纳入云数据库系统。
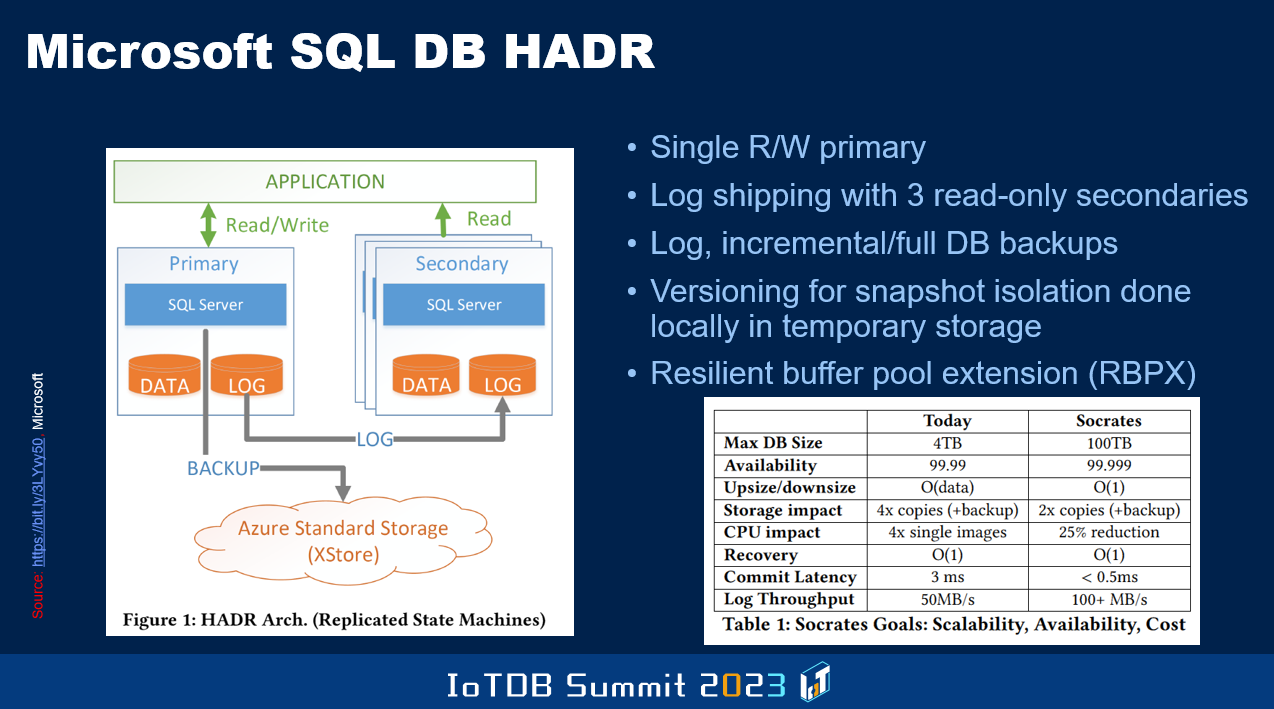
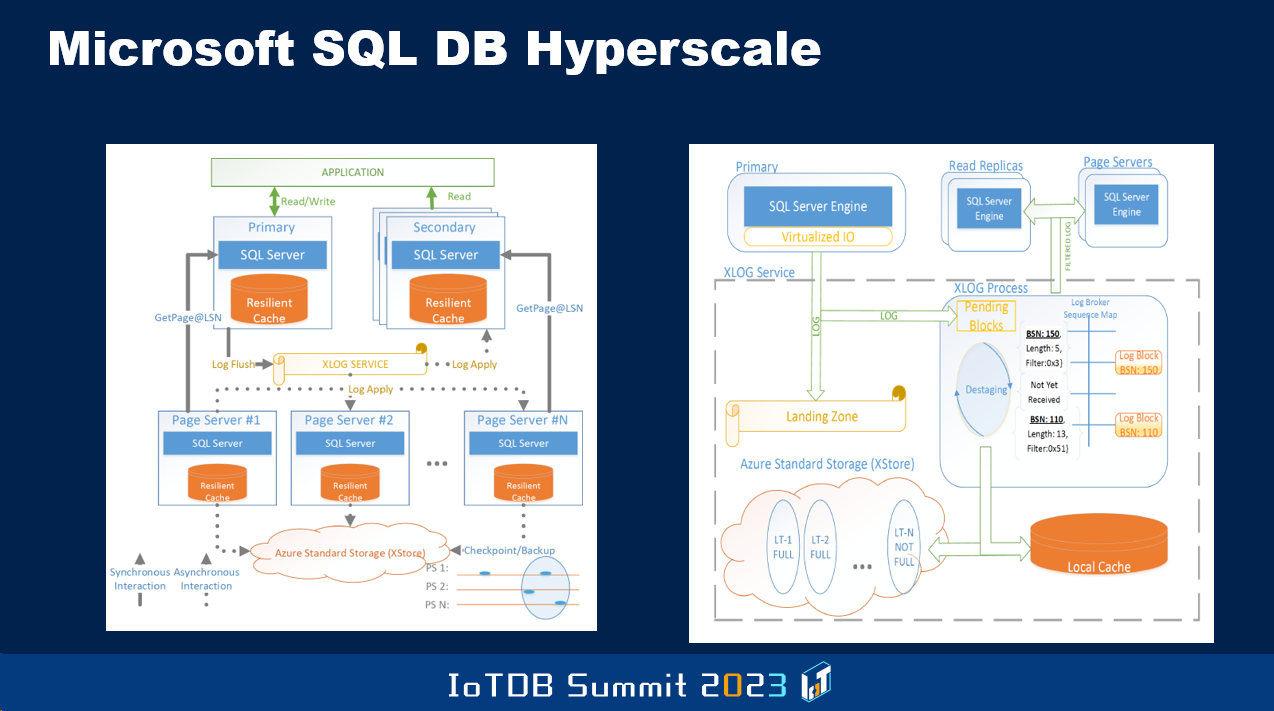
还有一些改进需要实现,以使得数据库单个节点的性能不受读写任务的限制。目前这是一个局限,同时也是可用性的瓶颈。如果该节点崩溃,到其他节点获得权限、能够承担读写任务之前,可能需要一段时间。
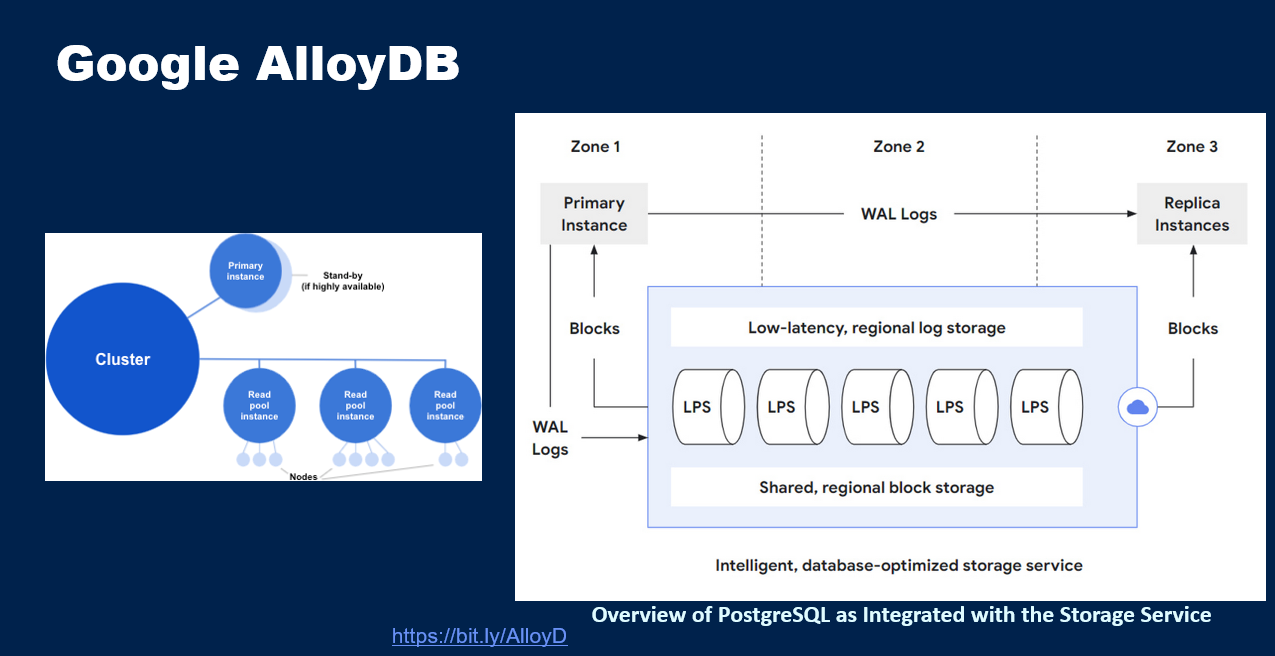
相较于亚马逊通过 Aurora 项目演变的 PostgreSQL,谷歌的 AlloyDB 是一个超级版本,因为它是一个混合事务分析处理(HTAP)系统。
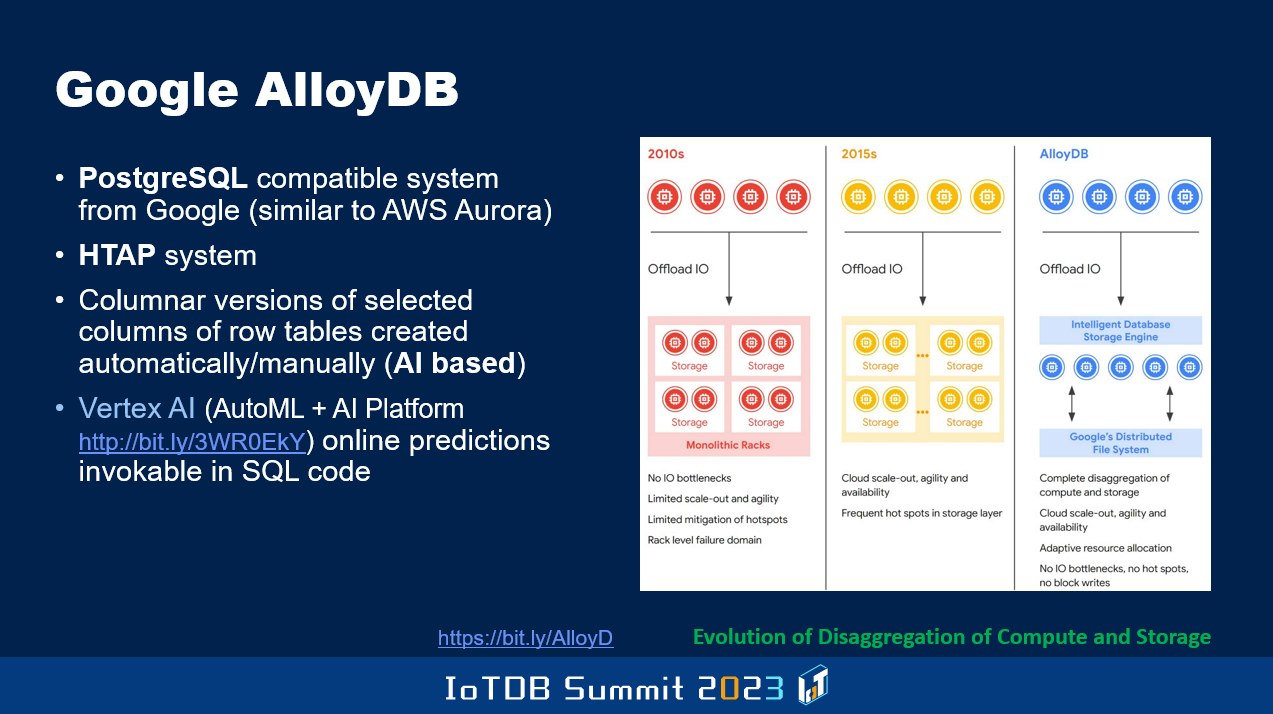
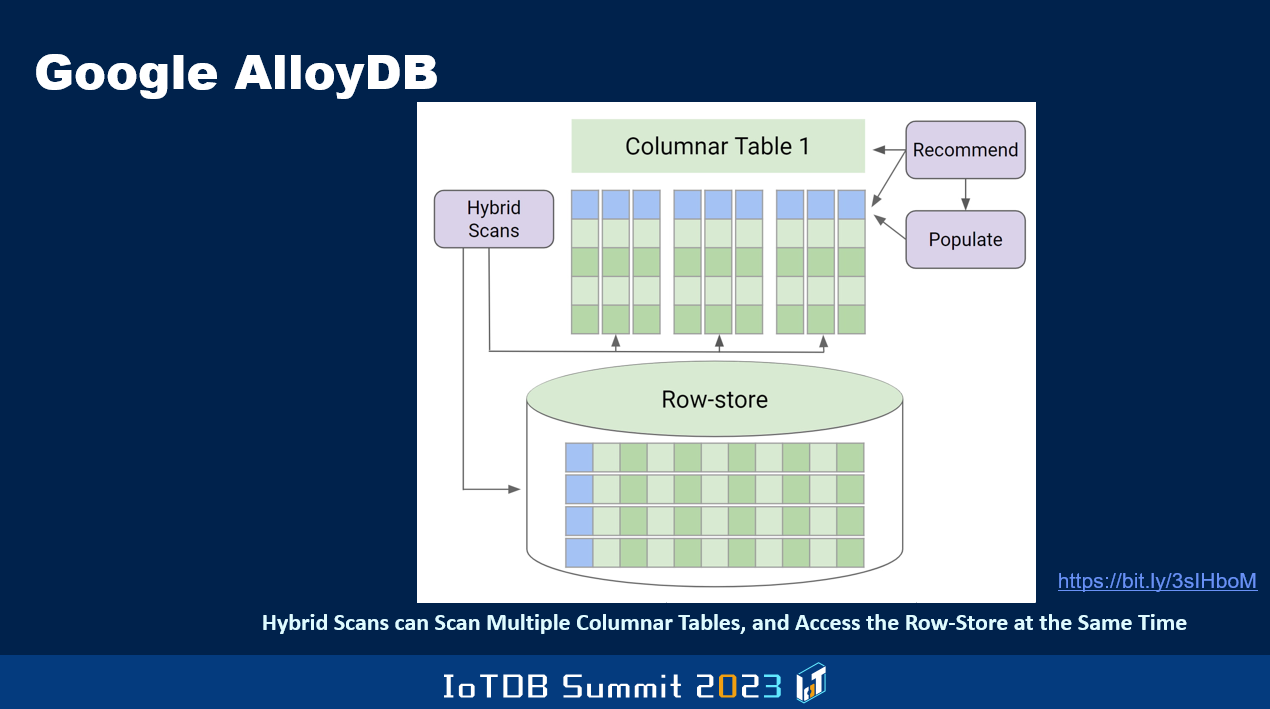
为了提高联机分析处理(OLAP)的性能,不仅可以保留数据的行版本,还可以保留数据的列版本。实际上,AI 被应用于动态监控工作负载和性能表现等场景,以确定特定数据表的哪些列可以以列版本形式进行维护,以便有助于查询性能。这与 Oracle 完全不同,因为在 Oracle 中,行表除行版本之外,还必须在内存中维护包含所有列的列版本。如果系统崩溃,由于列版本只存在于内存中,它将损坏,并且在恢复系统时必须重新进行创建。而谷歌还致力于实现从 SQL 查询中直接调用 AI 功能,于是在执行机器学习等操作之前,不需要将数据导出数据库管理系统再进行操作,可以直接从数据库管理系统内部进行 Vertex AI 调用。
总之,我告诉技术人员不要认为只有在研究领域才需要写论文。即使作为产品人员,写论文也有很多好处,因为这将使你的产品思维更加清晰,而且你将能够成为公司产品的布道师,让其他人了解它的优点,甚至可能是不足之处,讨论不足之处同样重要。这样,市场用户可以更全面地比较不同类型的产品。
举例来说,很长一段时间,谷歌的中间件产品仅被他们自己内部使用,比如 YouTube、Google 搜索、Android 等,因此没有费心在外部进行宣讲。但突然间,当谷歌云出现时,他们选择将其中一部分中间件系统提供给使用谷歌云的客户,试图通过这些客户赚钱。结果,以前可能存在的产品特性问题,如性能、标准合规性、完整的工具生态系统的可用性等,都变得明显了。因为其他公司的技术人员写了论文,他们在外部将更有存在感,并可以与其他的产品、研究人员互动,所以我们对其他公司的一些产品会有更多的了解。因此,我建议,即便是 Timecho 的团队,也要考虑这一点,就像我前几天提到的那样。
我的报告就到这里,谢谢。

更多内容推荐:
• 回顾 IoTDB 2023 大会全内容


