

12 月 3 日、4日,2022 Apache IoTDB 物联网生态大会在线上圆满落幕。大会上发布 Apache IoTDB 的分布式 1.0 版本,并分享 Apache IoTDB 实现的数据管理技术与物联网场景实践案例,深入探讨了 Apache IoTDB 与物联网企业如何共建活跃生态,企业如何与开源社区紧密配合,实现共赢。
我们邀请到 Apache IoTDB PMC Chair 黄向东参加此次大会,并正式发布 Apache IoTDB 1.0 版本,题为《为工业物联网而生——Apache IoTDB 1.0 全新版本》。以下为内容全文。
大家好,欢迎大家来到 2022 年 Apache IoTDB 生态大会,我是 Apache IoTDB 项目管理委员会主席黄向东。今天,今天很有幸能在这里向大家介绍 Apache IoTDB 的最新版本,1.0。
Apache IoTDB 是 Apache 基金会旗下迄今为止唯一的时序数据库管理系统项目, 我们将 1.0 版本的主题定为“端边云协同,为工业物联网而生”。
01 从 0 到 1:Apache IoTDB 走过的十年
社区里一直有一个呼声,说 IoTDB 只有零点几的版本,什么时候才能出1.0?
我们回顾大数据的起源软件之一 Hadoop,它的学术论文发表于 2003 年,2006 年推出 Hadoop 0.1 版本,2011 年才发布 1.0 版本。
在 Apache 这样一个国际顶级开源软件基金会,Hadoop 用了5年时间,从 0.1 成长为 1.0。此时据他们论文发表已经有 8 年。如果从发现大数据的问题开始,相信至少已经有 10 年的时间。
宝剑锋从磨砺出,软件行业,尤其是数据库、数据管理这样的基础软件,十年磨一剑,才能真正的形成从 0 到 1 的产品。
下面,我们来简单回顾一下 Apache IoTDB 从 0 到 1,走过的十一年。
熟悉 IoTDB 的朋友们知道,IoTDB 的诞生离不开工业物联网场景,从 2011 年接触工程机械装备的物联数据管理开始,来自清华的团队开始探索时序数据管理技术;2016年,IoTDB 的第一行代码落笔,进入自研期。2018 年 IoTDB 正式入选 Apache 国际基金会,成为 Hadoop、Spark 的同门师弟,正式进入开源孵化期;2020 年,IoTDB 毕业为 Apache Top Level Project,有了来自全球的用户和开发者,用户群体迅速蔓延,进入发展期。在这个过程中,团队相继推出了紧致时序文件结构、乱序数据处理技术、边云数据同步技术、实时库新值缓存机制、时序数据计算库等等。
作为时序数据管理领域的早期探索者,我们在创新的路上一直在前进。

在此过程中,IoTDB 以非常开放的心态建立了多样化的开源社区。
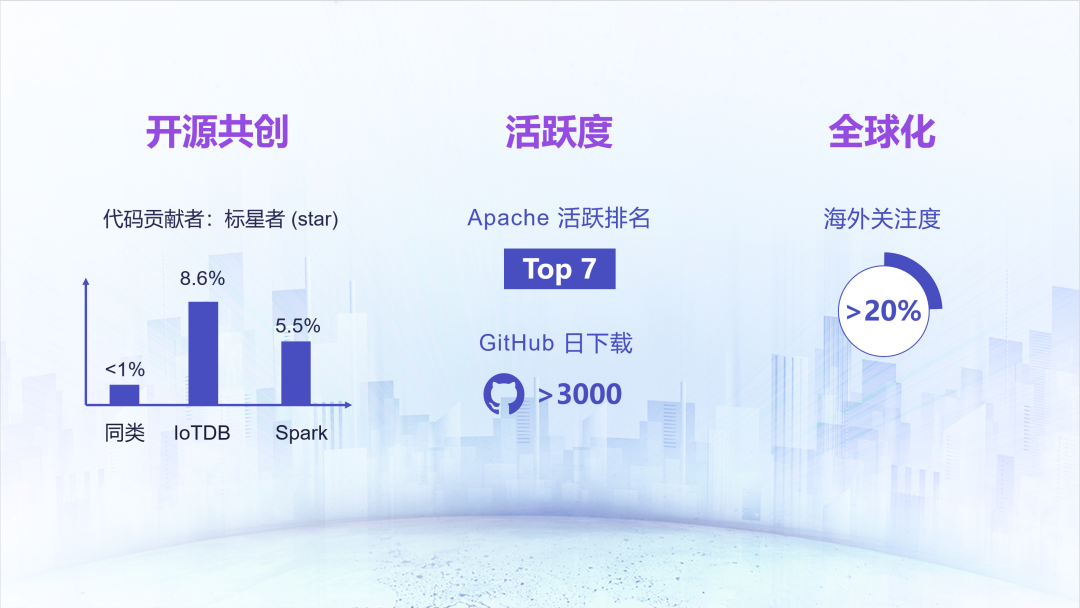
在社区规模和参与度方面,IoTDB 遥遥领先于诸多项目。我们来看一个有意思的数值,开源项目的标星者,可以类比为自媒体的点赞者,开源项目的代码贡献者,也就是协同创作者。贡献者比例越高,表明社区越开放,从而吸收的大众智慧就越多,项目软件也越好。IoTDB 目前达到了 8.6%。
用户的深度参与诞生了我们的第二个数据,2021 年 Apache 年报发布显示,IoTDB 活跃度排名在全球351个项目中排名第 7。目前,IoTDB 的 GitHub 日下载量超过了3000次。
此外,在众多参与者和关注者当中,来自海外的IP超过了 20%。
当前,IoTDB 的应用场景已经覆盖了天、空、地、海。我们在某卫星上部署了 IoTDB,用于在宇宙极端恶劣的环境下进行数据管理,并借助天地信号进行数据回传。从前年开始,IoTDB 开始服务于我国大飞机等的试验飞行和制造。在地面应用中,IoTDB 的应用场景覆盖了电力、石油石化、智能制造、车联网等等行业。海上应用中,IoTDB 也在支撑船舶的数据管理。
伴随着 IoTDB 的成长,IoTDB 的用户也在不断地增多,Logo 墙也在不断地增加。

02 新的十年:时序数据管理需求与技术的改变
在这一过程中,我们也关注到,用户对时序数据管理的需求也在不断地深化。
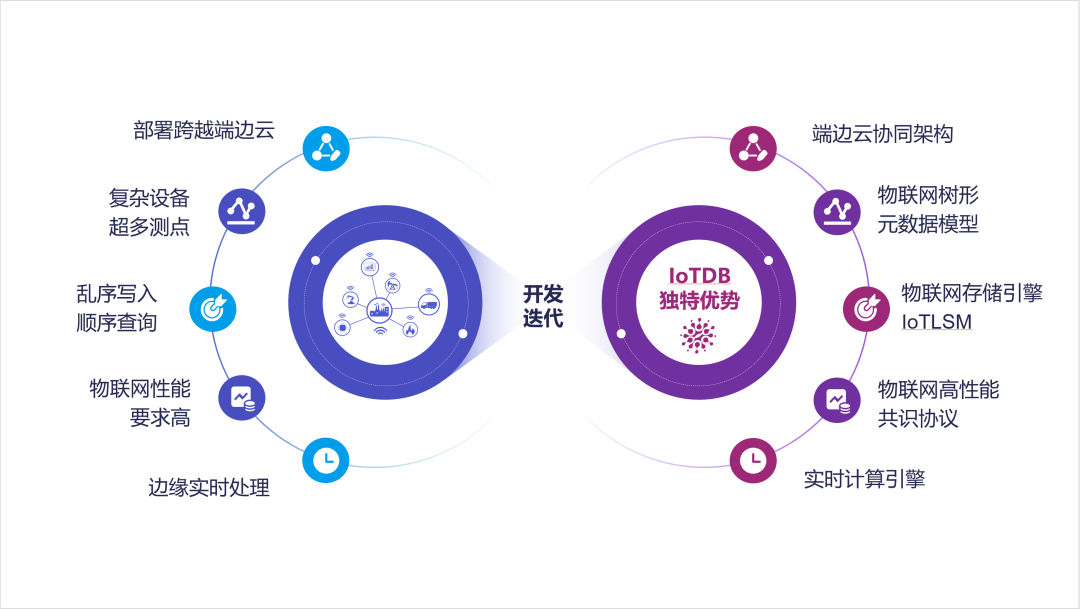
物联网场景下,数据的管理需求从云侧、边侧,向端边云协同演化;设备本身的精细度和复杂度的增加,也使得数据管理的测点变得更多、模式变得更多样。用户对于乱序等异常场景的数据管理需求也从简单的丢弃转向精细化的管理。即便如此,用户对于系统的性能,以及数据管理以外的功能,如分析等,都提出了更高的需求。
为了支撑这些新应用需求,并不断实现时序数据库管理技术的突破,在过去一年来,社区集结了 140 名代码贡献者跨公司、跨地域、跨时区的协同研发,新增了近百万行代码,研制了 101 个新特性,优化完成了 82 个改进点。一年来,有数千名开源用户对这些功能进行了验证。

在这样一个紧锣密鼓又兼容并包的开发推进下, Apache IoTDB 社区今天正式向大家推出 IoTDB 1.0 版本。
1.0 版本仍然以工业物联网为主要场景,针对端边云协同等工业物联网的特性场景,我们重新打磨了单机版本,并推出了全新的分布式架构。
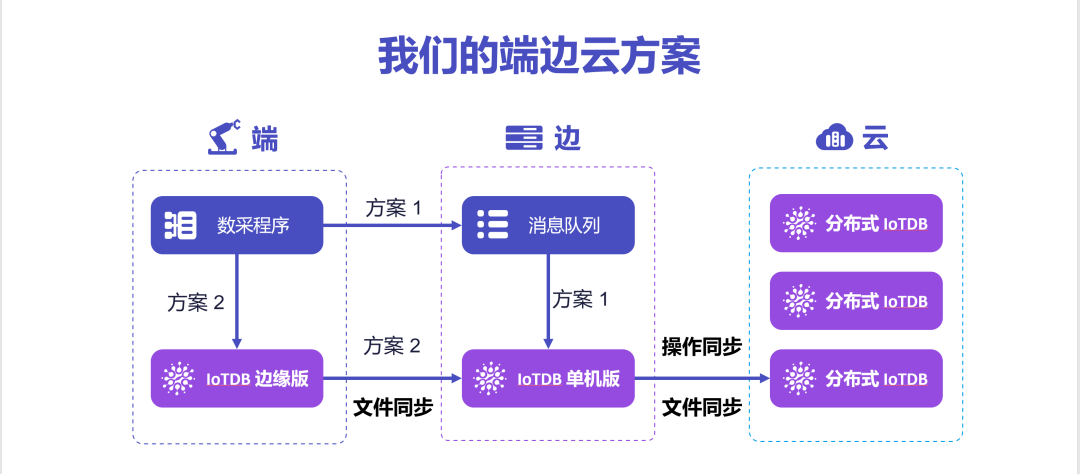
在物联网场景下,数据从端侧产生,在边侧网关进行收集,并汇聚到云侧。端、边、云三个场景,设备、网关、用户三个角色共同参与了整个数据流。
传统端边云解决方案下,设备在端侧部署采集程序,当网络通畅时,将数据发送到边侧,再进入云侧。当网络不通时,数据会被写入本地文件,再在网络通畅后将数据点逐个发送出去。
这就带来了几方面的问题:第一,在不同的应用程序中,在端侧临时存储的文件结构不统一,数据压缩比不高,导致端侧缓存数据的能力弱。此外,由于端侧不存储数据,完全没有数据应用的潜在能力。第二,在边侧和云侧,数据被重复写入数据库,这种重复计算带来了计算资源的浪费。
为此,我们通过设计 IoTDB 边缘版、单机版、分布式版多种形态部署,并创新了基于操作同步和基于文件同步的“端-边-云”多粒度、多延迟容忍的协同模式,最终达到:端侧、边侧具备更强的本地数据管理能力,来支撑本地的智能化应用;端侧、边侧已经组织好的数据不需要在云端重复消费资源,从而大幅减小用户管理数据的成本和代价。
03 重新打磨单机版 IoTDB
为了实现上述方案,IoTDB 进行了两方面的工作,一方面是单机版的改进,一方面是分布式的推出。
首先向各位介绍我们重新打磨的单机版 IoTDB。
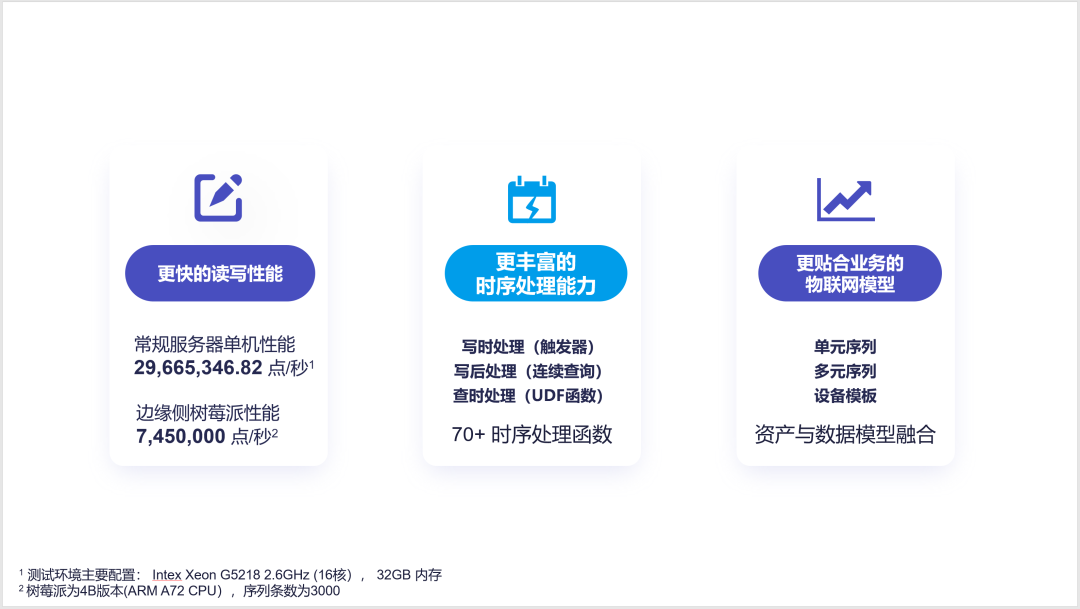
在 IoTDB 1.0 的研制过程中,我们通过对内存结构、缓存、磁盘读写的进一步优化,达成了更快的读写性能。
在常规服务器上,单机 IoTDB 可以达到超过 2966 万点每秒的写入性能;在像树莓派这样的边缘侧设备,单机 IoTDB 可以达到超过 740 万点每秒的写入性能。在这样一个性能加持下,单机的 IoTDB 往往就能解决用户的大多数场景。
其次,在过去一年多来通过不断抽象和提炼时序数据的处理计算场景,并结合数据库领域中的经典计算能力,我们总结并实现了时序数据实时写入时计算、时序数据处理入库后离线计算、查询时序数据时即席计算三种时序数据计算模式,并已经提供了超过 70 种时序数据处理函数,覆盖了时序数据预测、平滑、异常检测、时域-频域变换等常见处理方式。
最后,我们在 IoTDB 原有数据库模型的基础上再度创新,提出了更贴合工业场景的物联网模型。针对于灵活数据采集,我们提出了单元序列模式;针对于批量同时刻数据采集,我们提出了多元序列模式;针对于批量同型号设备数据管理,我们引入了设备模板的概念。这些模型同时融合了资产模型和数据模型,能够非常大程度的帮助 OT 域的人员更好地使用 IT 域的数据库产品。
04 引入全新分布式架构
下面,再向各位介绍一下 IoTDB 1.0 重大的改变,即全新的分布式架构。
在过去的几年实践中,我们注意到,在IoTDB带来高吞吐、高压缩的前提下,大多数的工业用户仅采用单机版 IoTDB 就能完全满足其性能需求。后来,我们还推出了 IoTDB 双活版,来解决单机版 IoTDB 的高可用问题。
在 2020 年初,为了满足部分用户确实需要分布式版本的需求,我们提出了 IoTDB 的第一代分布式架构。
第一代 IoTDB 分布式架构以 P2P 对等架构为基础,让用户通过非常简单的几个步骤,就能实现集群的部署;但是,在集群内部,我们划分了元数据管理角色和数据管理角色,采用一致性哈希技术进行数据分区,并引入了 Raft 协议,来实现强一致性多副本机制。
后来,我们注意到,当时的系统架构在集群扩容和系统鲁棒性等方面存在较大问题。
经过两年来对用户需求的收集,我们重新提炼了分布式版本的功能性与非功能性需求。我们认为,当用户需要 IoTDB 集群版本时,他面临的负载应该是极其繁重的:他需要管理上亿的设备和测点,支持每秒亿级的吞吐率,并具备高可用和高可扩展性,具备完备的可观测性,让用户知道集群是否健康,是否需要介入调整。

为此,我们推出了支持多种一致性、数据和元数据全面可扩展的全新分布式架构。
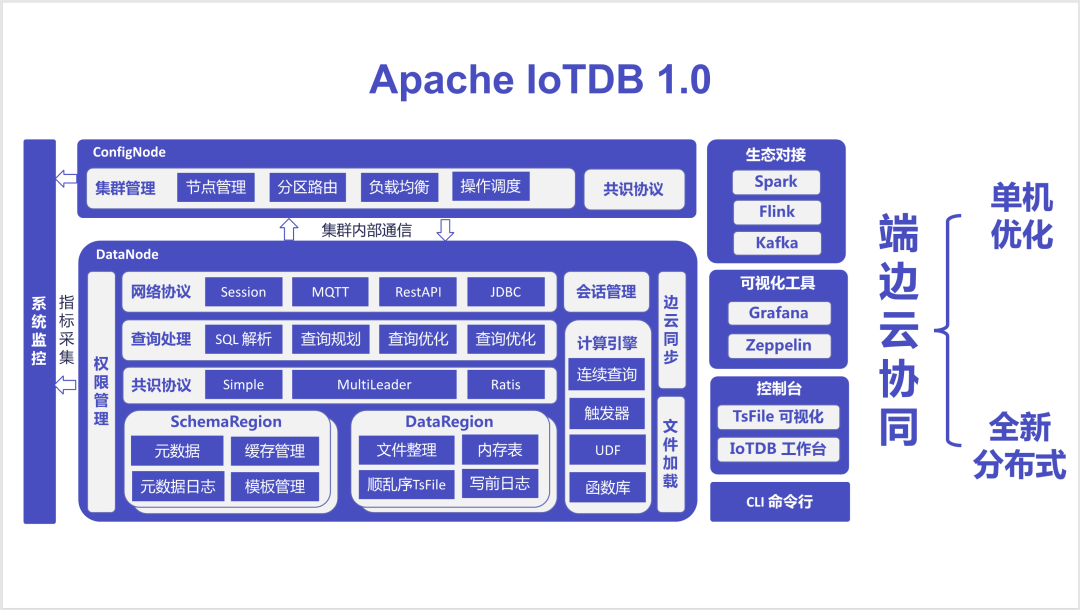
在这一新架构中,我们将集群中原本的多种角色暴露给数据库部署和运维人员,也就是 DBA,并重新定义了 IoTDB 中的管理节点和数据节点的概念。
在新分布式架构中,管理节点仅管理集群信息,用于负责分区信息的记录、负载均衡和操作调度与节点管理等功能。这种非常轻量的设计避免了管理节点成为集群的瓶颈。
而数据节点则负责了从元数据到数据的全面管理,各个数据节点会形成不同的副本组,他们通过可调的强一致性协议、或者专门针对物联网场景创新的物联网一致性协议进行数据的备份,以支持集群的高可用。而所有的操作,从数据写入、查询、到计算,都进行了负载的分布化。
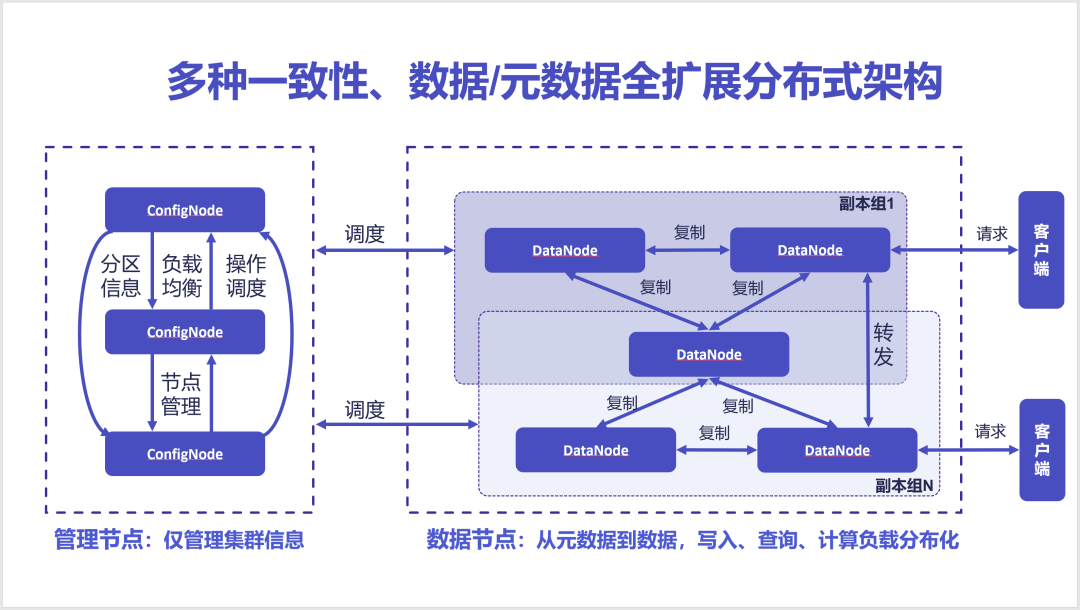
在这一架构中,我们对元数据进行了设备级别的分区,对数据进行了设备级别和时间维度的二维分区,从元数据和数据两个层面都保证了集群容量的扩展性。
在 1.0 版本中,我们还采用 MPP 架构,重新实现了 IoTDB 的查询引擎,实现大规模并行处理和实时计算。在此过程中,我们遵循了让“计算更靠近数据”的原则,尽可能少的进行数据的转发。同时,我们还提供了一系列的缓存技术,让“数据更靠近元数据”,进一步加快了系统的读写性能。
在 1.0 版本中,我们将数据和元数据都放在了数据节点。同时,将上一代基于哈希的数据分区技术升级为一致性哈希和查找表相融合的方式,并把分区表放在管理节点上,用于支持用户任意定制数据分配策略,来实现秒级系统扩容。
最后,我们注意到物联网场景下时序数据的写操作有其特殊性,为此,我们在保留并改进原有 Raft 强一致性协议的基础上,提出了为物联网场景优化的最终一致性协议,来给用户提供更加优异的性能体验。

在这一系列新技术的加成下,我们在多个维度上完成了性能指标的优化。
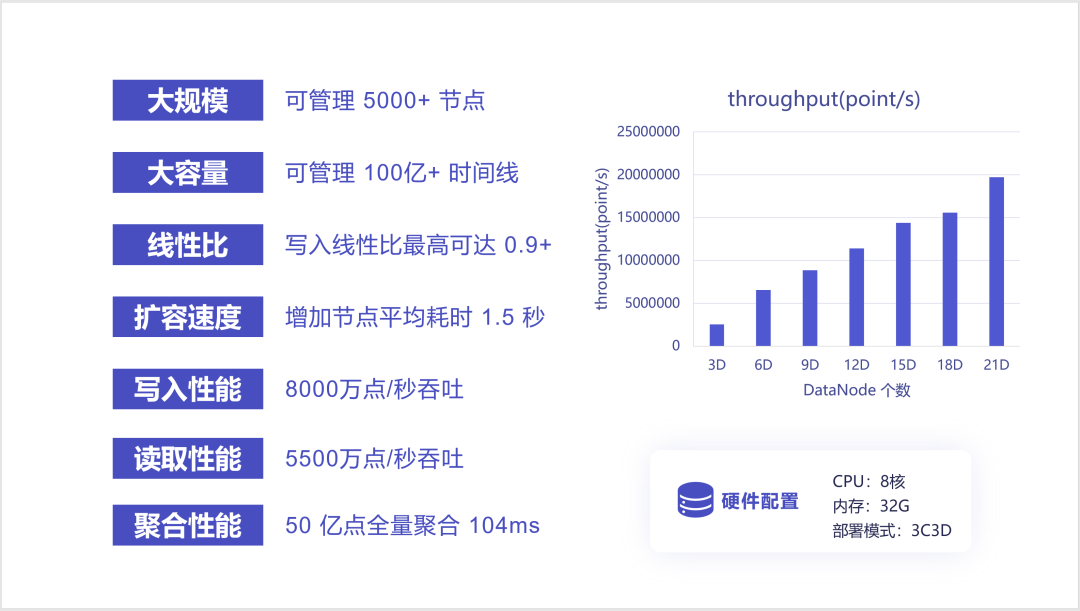
在集群扩展能力上,我们在某云环境下,验证了超过 5000 个节点的集群规模。
在时间序列管理规模上,我们完成了超过 100 亿条时间序列的测试。
在集群扩展的性能方面,每新增一个数据节点,平均耗时可以控制在 1.5 秒以内。
在多副本情况下新增加节点时,系统的性能提升比超过了 90%,即每增加一倍的数据节点,系统的性能就能提升0.9倍。例如在 3 个数据节点能支持 3000 多万点每秒的写入性能下,6 个数据节点就能支持近 6000 万点每秒的性能。
在性能压测中,我们以 9 个数据节点的集群,完成了超过 8000 万点每秒的写入性能,而数据的读取性能也超过了 5500 万点每秒。
针对时间序列的聚合查询,我们在百毫秒级别,即可完成对 50 亿数据点的聚合操作。
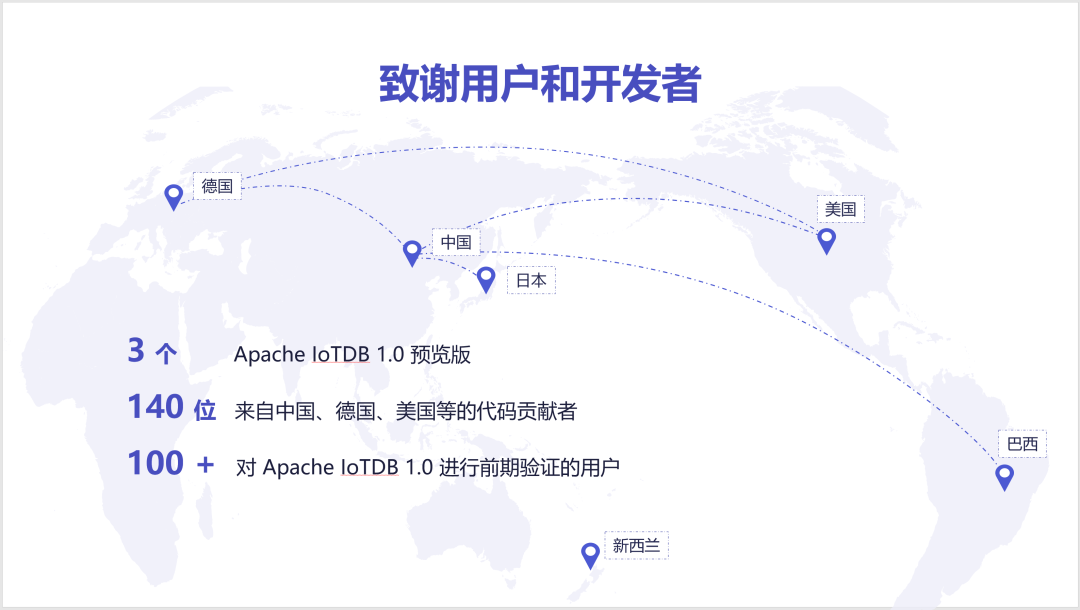
在过去的两个月,我们陆续发布了 Apache IoTDB 1.0 的 3 个预览版,并已经被京东等一批用户进行了验证和试用,部分用户已经将其部署在生产环境中。IoTDB 1.0 的顺利研制,离不开来自中国、德国等的 140 位代码贡献者,更离不开信任我们并勇于尝试的用户们。
此外,作为 Apache 基金会的开源项目,IoTDB 也与来自于 EMQ、DolphinScheduler、Skywalking 等开源项目开展了深度合作,与 Linux 基金会的 EdgeX、德国博世的 CtrlX 等完成了深度集成,感谢这些合作社区对 IoTDB 项目的关怀和帮助。
回首过去 10 年,IoTDB 社区作为时序数据的早期探索者,提出了一系列技术与功能形态,感谢大家的支持。
最后,欢迎大家试用、使用 Apache IoTDB 1.0, 欢迎大家提出宝贵的意见、贡献精彩的想法和代码。
Apache IoTDB 社区期待和广大用户、开发者一起,开启我们 10 年的新征程,一起继续做时序数据管理技术领域的领跑者。谢谢大家。
更多内容推荐:
• 回顾 IoTDB 2022 大会全内容


