

12 月 3 日、4日,2022 Apache IoTDB 物联网生态大会在线上圆满落幕。大会上发布 Apache IoTDB 的分布式 1.0 版本,并分享 Apache IoTDB 实现的数据管理技术与物联网场景实践案例,深入探讨了 Apache IoTDB 与物联网企业如何共建活跃生态,企业如何与开源社区紧密配合,实现共赢。
我们邀请到 Apache IoTDB Committer,华为云 MRS 时序数据库研发负责人王超参加此次大会,并做主题演讲——《Apache IoTDB 在华为云的实践》。以下为内容全文。
大家下午好,我今天演讲题目是《Apache IoTDB 在华为云的实践》,主讲人王超。首先我做个自我介绍,我叫王超,是华为云 MRS 时序数据库研发负责人,同时也是 Apache IoTDB Committer。
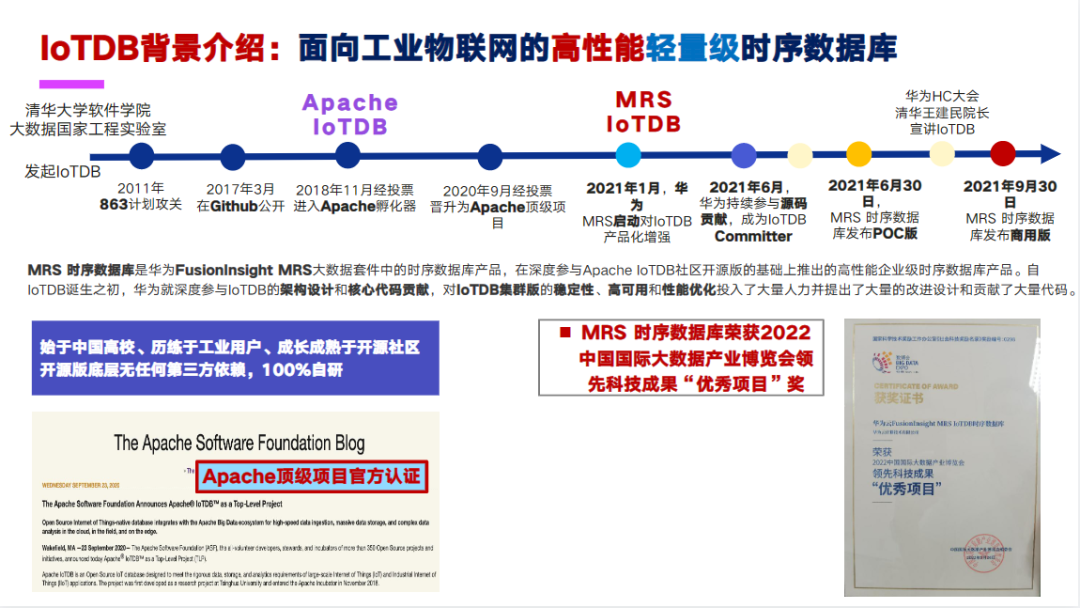
IoTDB 背景介绍:IoTDB 是一个面向工业物联网的高性能轻量级时序数据库,它是由清华大学软件学院大数据国家工程实验室发起的。2018 年 11 月经投选进入 Apache 孵化,2020 年 9 月经投票晋升为 Apache 顶级项目。2021 年 1 月份,华为 MRS 启动对 IoTDB 的一个产品化增强。2021 年 6 月,华为持续参与源码贡献,成为 IoTDB Committer。2021 年 9 月 30 号,MRS 时序数据库发布商用版。
MRS 数据库是华为 FusionInsight MRS 大数据套件中的时序数据库产品,在深度参与 Apache IoTDB 社区开源版的基础上推出的高性能企业级时序数据库产品。自 IoTDB 诞生之初,华为就深度参与 IoTDB 的架构设计和核心代码贡献,对 IoTDB 集群版的稳定性、高可用和性能优化投入了大量的人力,并提出了大量的改进设计和贡献了大量的源码。IoTDB 始于中国高校,历练于工业用户,成长成熟于开源社区,开源版底层无任何依赖,100% 自研。MRS 时序数据库荣获 2022 中国国际大数据产业博览会领先科技成果“优秀项目”奖。
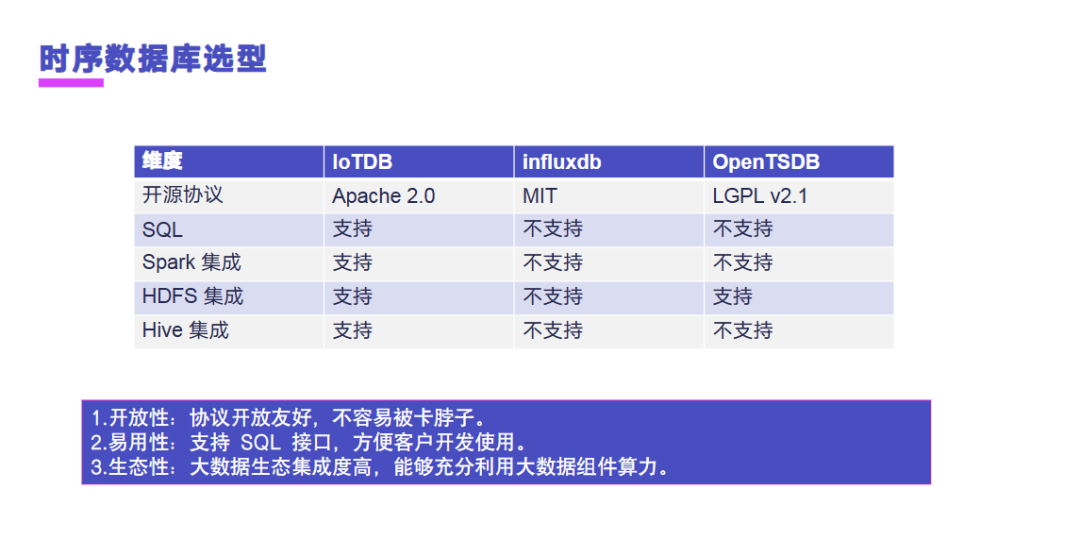
接下来我将介绍时序数据库的选型,我们将从几个维度来进行分析。首先是从开源协议,IoTDB 使用的是 Apache 2.0 协议,InfluxDB 使用的是 MIT 协议,OpenTSDB 使用的 LGPL 协议。从协议上去看,IoTDB 的协议更加友好。第二是从 SQL 能力上去看,第一个 IoTDB 是支持 SQL 能力的,下来是从 Spark 集成,IoTDB 支持 Spark 集成,也支持 HDFS 集成,也支持 Hive 集成。
第一个我们从开放性来看,友好的协议能够使我们更好地去开发,不容易被卡脖子。第二个是从易用性,支持 SQL 接口,方便客户开发使用。第三,生态性,IoTDB 跟大数据生态能够高度结合,能够充分利用大数据组件的算力,因此我们选择了 IoTDB 作为时序数据库产品。
接下来我将从以下几个方面来进行介绍。一个是社区贡献,下来是企业级特性增强,安全、传输、加密,下来是企业级特性增强,可靠性和运维。最后是企业级特性增强,多模融合技术和案例。
01 社区贡献
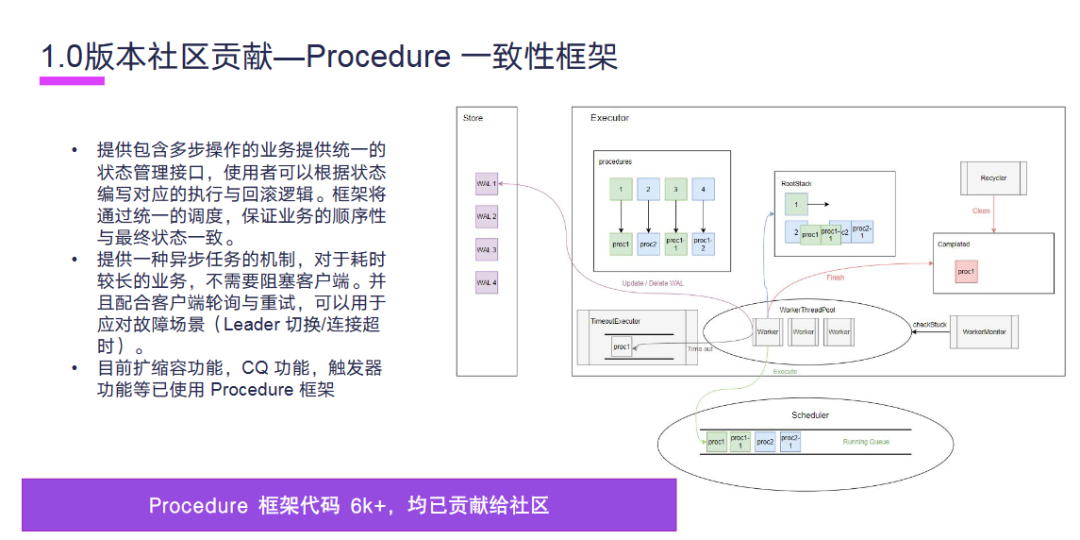
我们看一下在社区 1.0 版本中我们的设计贡献。首先我们贡献了 Procedure 一致性框架。Procedure 一致性框架它提供了包含多步操作的业务提供统一的状态管理接口,使用者可以根据状态编写对应的执行与回滚逻辑。框架将通过统一的调度,保证业务的顺序性和最终状态一致。第二,它提供了一种异步任务的机制,对于耗时较长的任务,不需要阻塞客户端,并且配合客户端轮询与重试,可以用于应对故障场景,比如 Leader 切换和连接超时。第三,目前扩缩容功能、CQ 功能、触发器功能等均已使用了 Procedure 框架。Procedure 框架代码 6000 多行,均已贡献给社区。
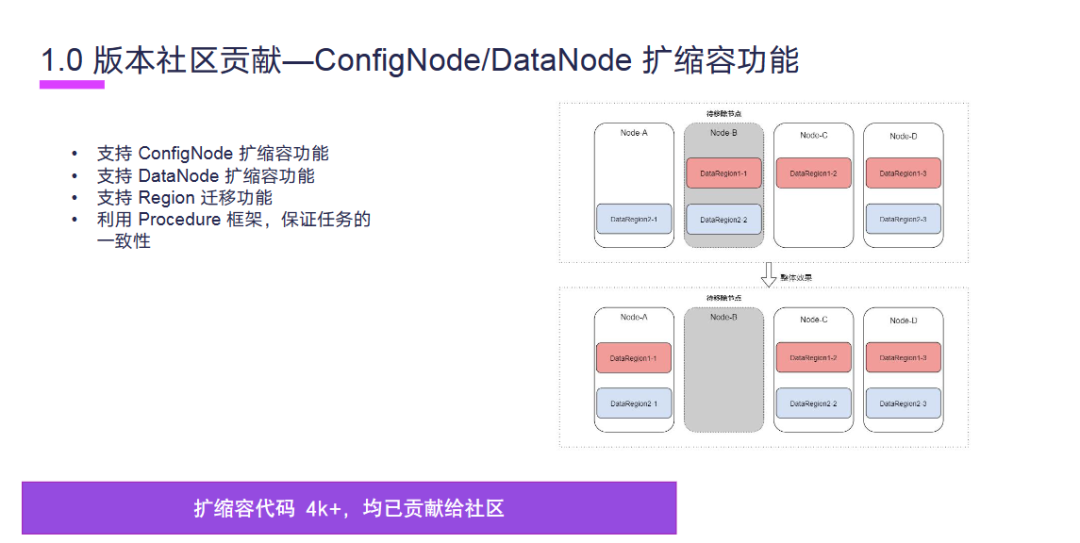
接下来是 1.0 版本的设计贡献,ConfigNode 和 DataNode 扩缩容功能。首先我们支持了 ConfigNode 的扩缩容功能,第二支持了 DataNode 的扩缩容功能,第三支持了 Region 迁移功能,第四,利用 Procedure 框架能保证任务的一致性。扩缩容代码 4000 多行均已贡献给社区。
接下来是 ConfigNode 架构设计和框架代码重构。在 ConfigNode 的架构初期,我们识别到了 ConfigNode 的一个架构问题,共识层在 Manager 层之上,每个 Manager 计算的结果会有差异,因此进行了架构重构,只能由 ConfigNode Leader 来进行 Manager 系列操作。我们将共识层放在 Manager 层之下,ConfigNode Leader Manager 通过计算后将不可变的数据通过共识层同步到各个 Follower。ConfigNode 重构代码 4000 多行均已贡献给社区。
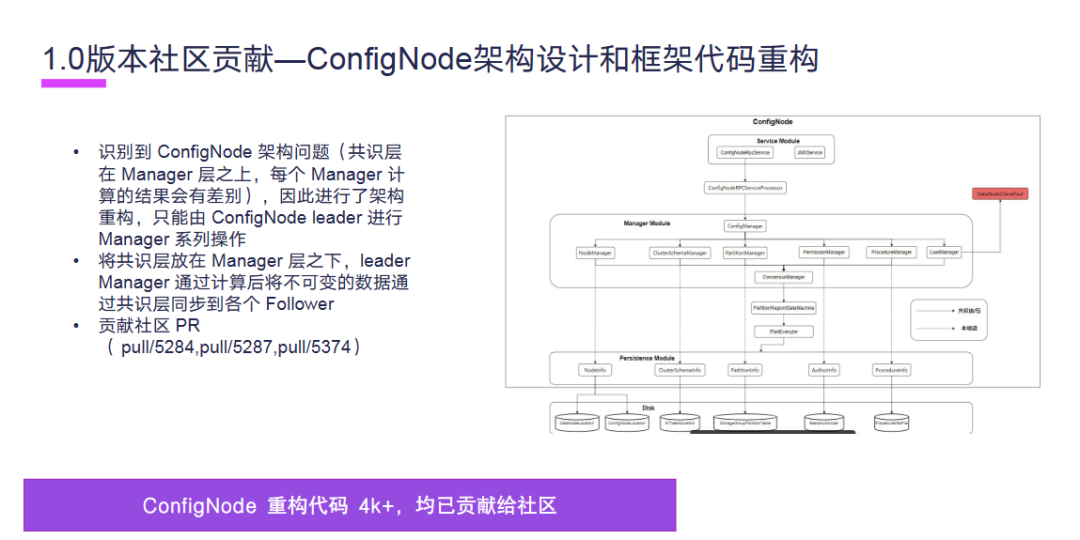
1.0 版本社区贡献部分特性,我们支持了输入的命令,支持了在 MPP 框架下面的元数据操作,支持了 DataNode 的元数据缓存,支持了 Show Child Paths 命令,支持了 ConfigNode RPCServer,支持了删除存储组。以上是1.0部分特性贡献,均已贡献给社区,除此之外还有一些 bug 修复也贡献给社区。

接下来是社区贡献的 0.12 版本。我们在 0.12 版本之中主要是做了性能优化,首先我们优化了线程池,我们优化了查询时间范围和元数据拉取,以及批量的去拉取序列读取操作。接下来是我们优化了路由间隔以及线程池,0.12 的分布式查询优化性能提升了 30%,均已贡献给社区。

02 企业级特性增强-安全、传输、加密
接下来是我们的企业级特性增强-安全、传输、加密。我们遇到的问题是社区版本简单的用户名密码认证容易被破解,我们的解决方案是我们通过 Thrift+Kerberos 的认证机制,我们在 DataNode 和 ConfigNode 实例之间进行了 Kerberos 认证,我们在客户端和 DataNode 之间同时支持 Kerberos 认证和用户名/密码认证。第三,Kerberos 认证可以跟 Hadoop 生态圈进行无缝对接。

数据传输和密码加密:问题是密码使用 MD5 加密保存容易被破解,数据在传输过程中没有加密,容易被获取,泄露。我们的解决办法是,首先我们重构了加减密模块,能够可插拔式的进行加减密算法,此重构均已贡献给社区。第二,我们实现了 SHA384 的密码加密,保证密码在本地存储的安全性。我们实现了 Thrift 和 SSL 加密,保证数据在传输过程中进行加密。

03 企业级特性增强-可靠性和运维
接下来是看一下企业级特性增强的可靠性和运维。数据备份恢复:问题是一个机房的集群灾难毁坏之后,数据不可恢复。我们的解决方案是首先是备份,我们实现了 TsFile 的数据快照和数据回收站。第二实现了周期备份和调度任务。第三,我们实现了按照存储组和设备级别进行备份,将数据备份到远端的 HDFS 上面,数据文件可能够从远端的 HDFS 上面来进行加载和恢复。

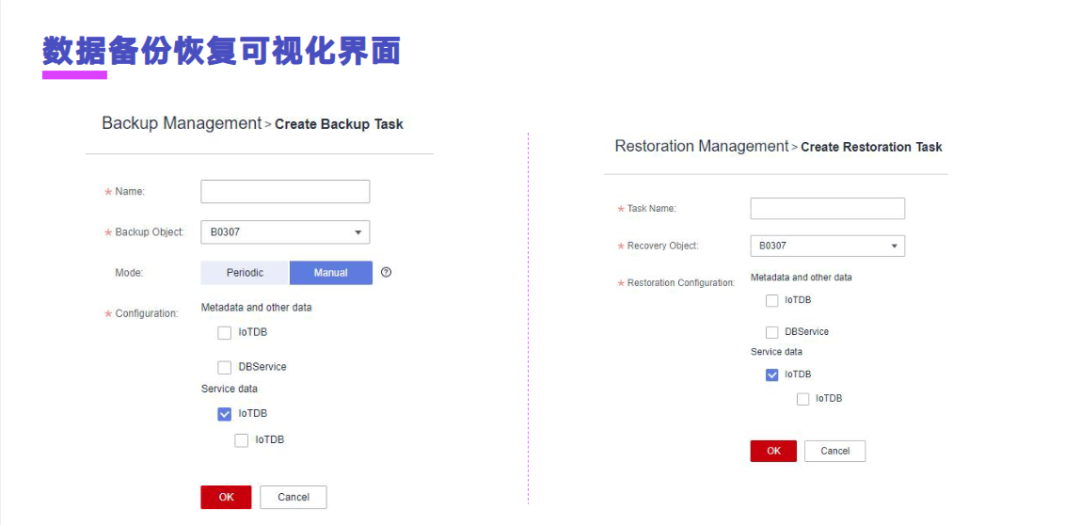
接下来是数据备份恢复的可视化界面,我们提供了可视化一键式的备份恢复任务,客户可以通过界面来进行配置。
接下来是支持磁盘热插拔。问题是 IoTDB 是个多盘挂载的数据库,单盘坏掉之后,这个盘上面的数据将进行丢失。我们的解决办法是,我们实现了单盘坏掉之后,我们只需要插入空盘,空盘上的数据能够进行补齐。我们实现的办法是,第一,我们实现了一种新的磁盘选择策略,我们将同一个存储组的数据放在一个磁盘上。第二,快照文件被打包发送,并按照个数进行切分,防止文件过多超过内存之后,批量读取 TsFile 到内存,然后进行传输。第三,一批 TsFile 文件转换成 byte 数据之后,将 byte 进行拆分成多个,防止一次传输超过 thrift max size。第四,增加了间歇传输和重试等稳定机制,以确保传输可靠性。

我们支持了滚动重启,问题是 IoTDB 在重启的过程中会中断上层业务的读写流程。我们解决办法是,我们增强了读写过程以及读写故障切换,我们在读的时候请求将转发到其他两个副本所在的节点。在停止服务之前,您需要转移当前节点所在的共识组的 Leader,只有在转移完成之后我们才能停止该进程。
故障隔离和启动恢复:如果 ConfigNode 在一段时间之内无法从节点接收到心跳,那么 ConfigNode 将隔离此 DataNode 节点。DataNode 启动之后,然后再次向 ConfigNode 去注册。

我们支持了 JDBC 的多 IP,问题是客户端可以连接到任何的 DataNode 上面,如果一个 DataNode 发生故障之后,服务将中断。我们的解决办法是,我们可以在 JDBC 的 URL 里面去配置多个 IP,如果一个 IP 地址无法访问的时候,系统可以切换到下个 IP。第三,我们随机连接到一个 IP 上以实现负载均衡并减少单点故障。第四,如果一个节点出现故障之后,客户端可以重试下一个 IP 地址。第五,单点故障不会影响上层业务,从而提高服务的可靠性。

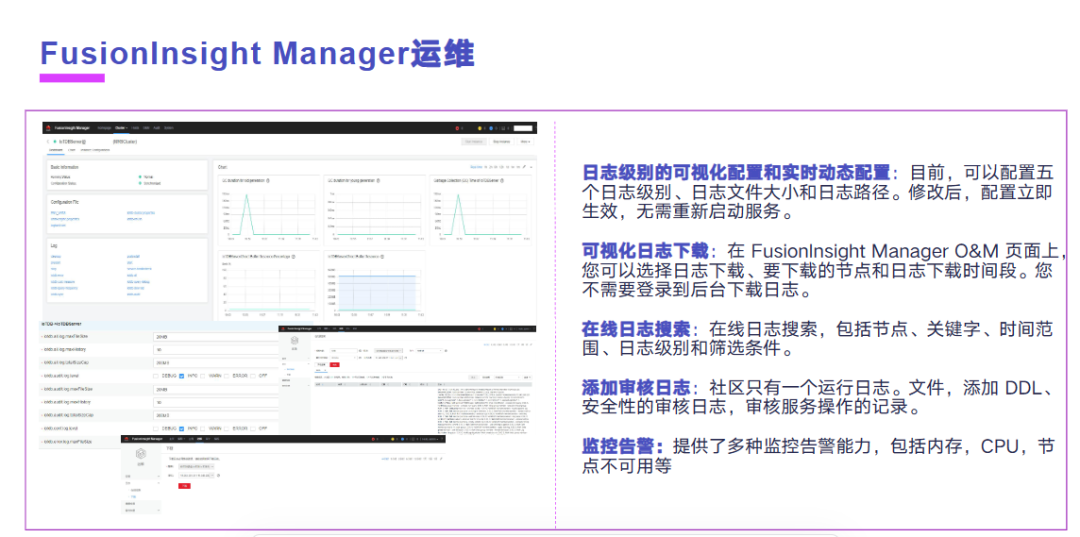
这是我们的 FusionInsightManager 的一个运维界面。我们提供了可视化的一个运维管理,日志级别可视化配置和实时动态配置,可视化的日志下载以及日志的在线检索。我们添加了一个审计日志,我们提供了监控告警的能力,包括 CPU、内存、节点不可用等告警。
04 企业级特性增强-多模融合技术和案例
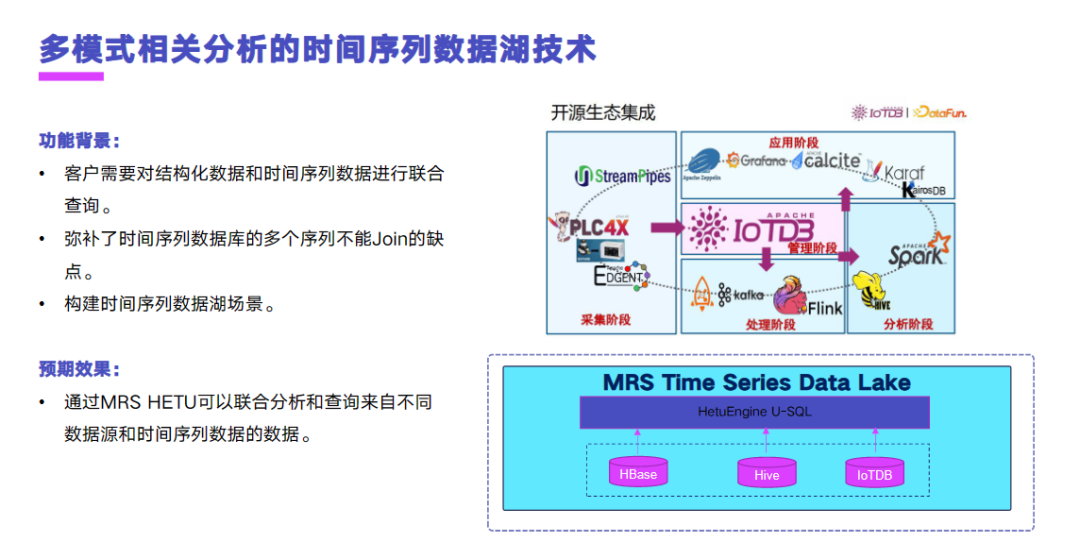
接下来是我们的企业级特性增强-多模融合技术和案例。多模融合技术的功能背景是,第一个客户需要对结构化数据和时序数据进行联合分析。第二,多模融合技术它弥补了时序数据库的多个序列之间不能 Join 的缺点。我们的预期效果是,通过我们的多模融合技术,MRS HETU 可以联合分析不同数据源和时序数据。右边这张图我们可以清晰地看到,通过我们的 MRS HETU,能够将 HBase、Hive、IoTDB 中的数据来进行关联分析。
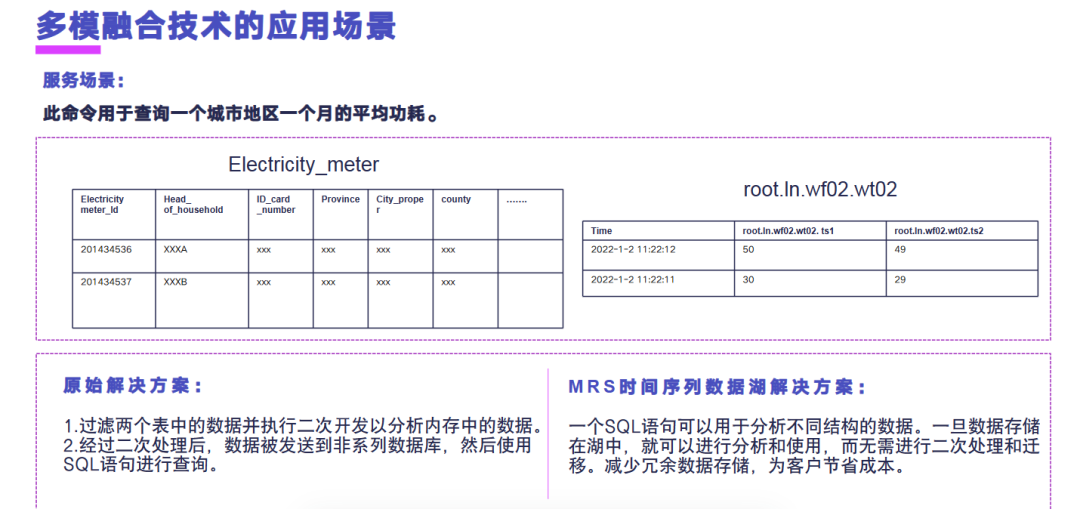
我们看一个多模融合的应用场景的例子。我们的服务场景是需要去查询一个城市地区在一个月的平均功耗,我们首先看一下电表的信息是保存在我们的关系库里面去的,比如说保存在 Hive 表里面,我们的电表采集的时序数据我们保存在 IoTDB 里面去。要实现此功能的时候,原始的方案是我们需要在关系库中,比如说 Hive 中,去查找出来某个城市中的电表 ID,然后将电表 ID 下发到我们的时序库里面去求取此电表 ID 在一段时间的平均值。然后在内存中去将所有的电表 ID 的平均值再次求取一个二次计算,再次求取平均值。
MRS 的时序数据库的解决方案是,我们通过我们的 MRS HETU 去下发一个 SQL,可以将 Hive 中的数据跟我们 IoTDB 中数据做关联分析,通过一个 SQL 就可以实现此功能。数据一旦入湖之中就可以进行分析和使用,无需进行二次处理和迁移,我们减少了数据的冗余存储,为客户节省成本。
以上是我的今天的分享,感谢大家的收听。
更多内容推荐:
• 了解更多 IoTDB 应用案例
• 回顾 IoTDB 2022 大会全内容


