

12 月 3 日、4日,2022 Apache IoTDB 物联网生态大会在线上圆满落幕。大会上发布 Apache IoTDB 的分布式 1.0 版本,并分享 Apache IoTDB 实现的数据管理技术与物联网场景实践案例,深入探讨了 Apache IoTDB 与物联网企业如何共建活跃生态,企业如何与开源社区紧密配合,实现共赢。
我们邀请到长安汽车智能化研究院车云高可用技术主管黄立参加此次大会,并做主题演讲——《Apache IoTDB 在长安智能汽车数据平台的实践》。以下为内容全文。
各位小伙伴大家好,我叫黄立,来自重庆长安汽车。我今天分享的主题是《Apache IoTDB 在长安智能汽车数据平台的实践》。
本次分享一共包含四个部分,第一部分是长安智能汽车数据业务的介绍,第二部分是长安智能汽车大数据处理的架构,第三部分是 IoTDB 在长安大规模时序车况场景的实践,最后一个部分是长安智能汽车数据平台的架构展望。
01 长安智能汽车云数据业务概览
首先介绍一下长安智能汽车数据的一个业务。数字化技术对于汽车进行了深度的重构,汽车从一个配备电子功能的机械产品,逐渐演变为一个配备机械功能的电子产品。云数据及 AI 技术的一个融合逐渐地将汽车变为了一个大型的智能移动终端、数据采集载体、能源储能单元和一个移动的多功能空间。总的来说,现在的智能汽车已经逐渐转变为一个具备多功能空间的轮式移动机器人。
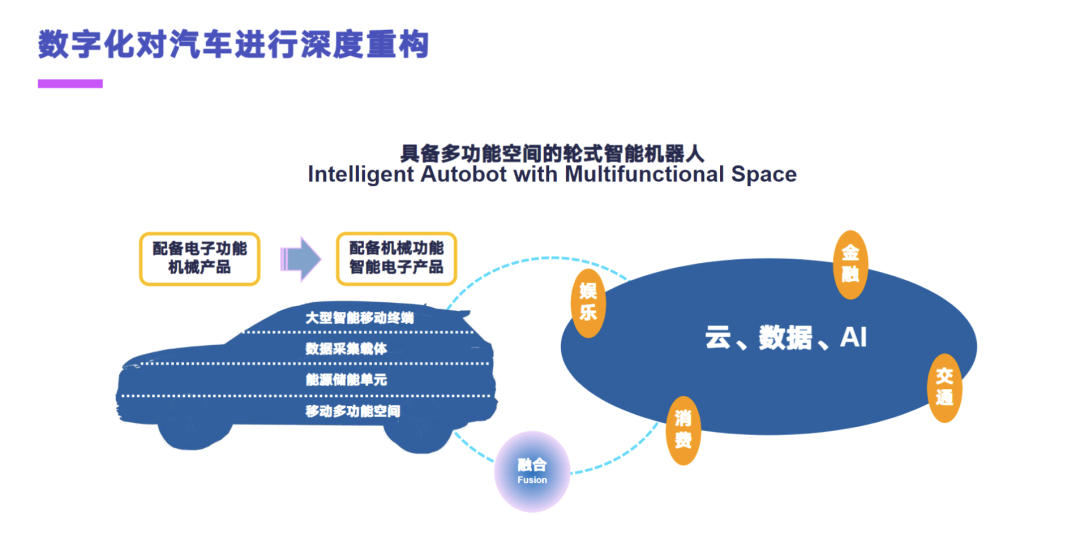
消费者他就需要更加的智能,能持续进化的一个汽车。大的来看有两个场景,第一个是智能座舱的场景,第二个是自动驾驶的场景。智能座舱的场景要求现代智能汽车去适应一个复杂的人机交互,这块包含语音、手势和表情的交互。自动驾驶这块要求智能汽车它能够去适应复杂的一个路况交通,去应对这种强行加塞、近距跟车和非标车位的场景。

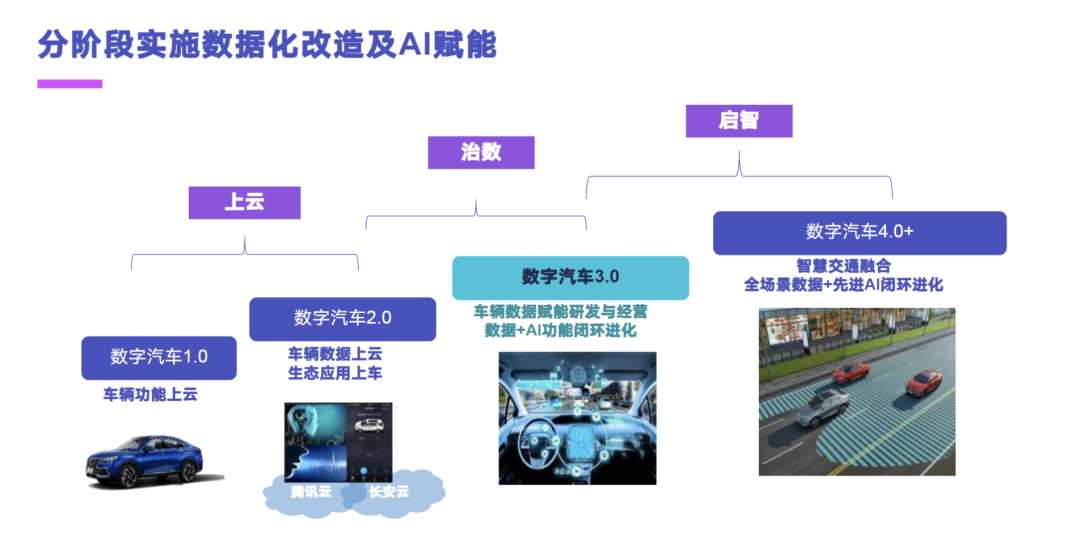
长安汽车在汽车数字化改造的实施路径上,选择了一个分阶段的数字化改造。大的来看有三个部分:上云、治数和启智。上云阶段主要包含数字汽车 1.0 和 2.0,实现车辆的功能上云、数据上云和应用上云。在治数阶段,主要是构建一套适合智能汽车的一个大数据处理平台,去实现车辆数据赋能、研发与经营,数据和 AI 功能的一个闭环进化。在最后的启智阶段,实际上做的是数字汽车的 4.0,这块跟国家在推行的智能汽车的云控平台思路是一致的,通过边缘云、区域云和中心云的一个架构,去实现整体 V2X 的一个智慧交通的一个融合,全场景数据和先进 AI 的闭环进化。
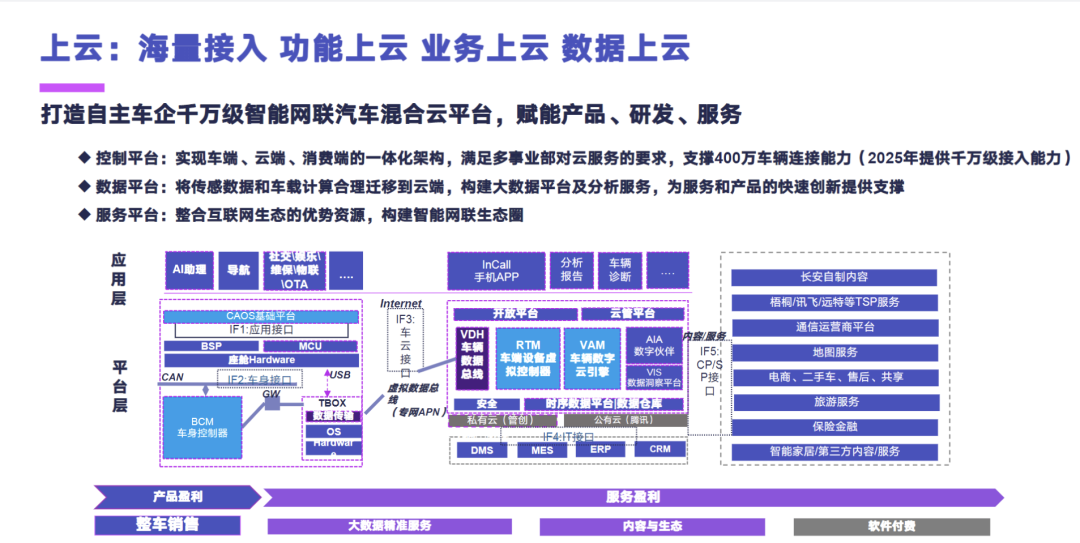
上云阶段,海量接入、功能上云、业务上云和数据上云,长安是打造了自主车企的一个千万级的智能网联汽车混合云平台去赋能研发、产品和服务。大的来看平台有三个,就是我们的控制平台、数据平台和服务平台。控制平台主要去实现车端、云端、消费端的一个一体化架构,去满足多事业部对智能汽车不同的云服务要求,目前是已经支撑了 400 万网联车的连接能力,然后预计在 2025 年去提供一个千万级的接入能力。数据平台是将传感数据和车载计算合理地迁移到云端,去构建大数据平台及分析服务,为服务和产品创新去提供数据的支持。服务平台在我们内部是做了一个开放平台,去整合互联网生态的优势资源,构建智能网联生态圈。
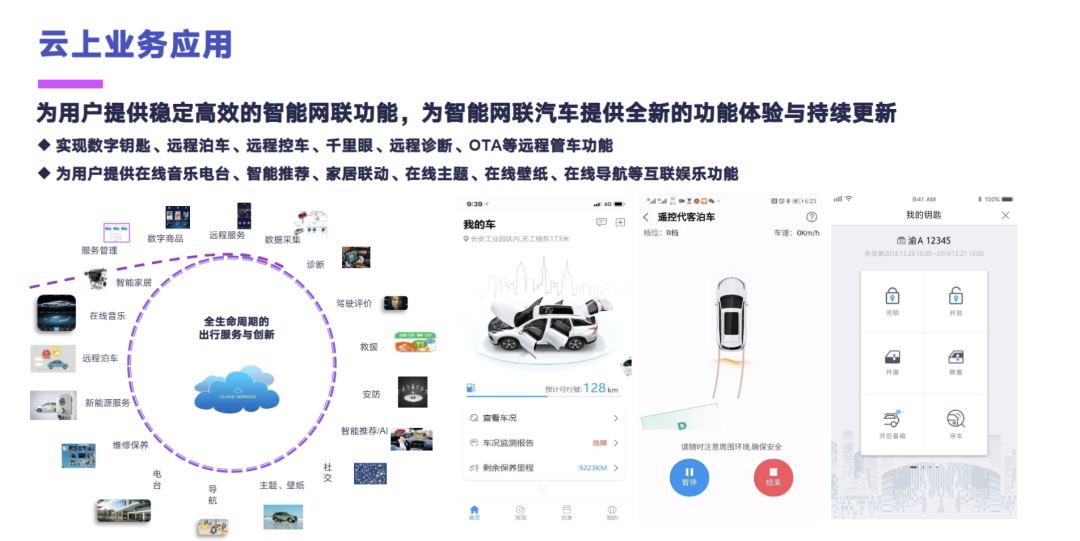
云上的业务应用其实跟之前的那种 TSP 平台是类似的,主要是为用户去提供一个稳定高效的智能网联功能,为智能网联汽车提供全新的一个功能体现与持续更新。功能分两块,第一块其实就是 TSP 平台主要做的那种数字钥匙、远程泊车、远程控车和诊断,包括那种在线 OTA 升级的一个远程管车的功能。第二块就是为用户去提供一些在线的电台、音乐、智能推荐、家居联动、在线的主题、壁纸等互联娱乐的功能。
在治数阶段,主要是要做到车辆控制器的数据上云的改造及标准化,因为我们单个那种车联网设备,它是少则有差不多五百项,多的有差不多两千项的信号数据,需要去做采集管理的。这块我们就可以统一的去做一个数据的采集管理平台,然后再构建云上的一个海量数据的存储与处理能力,去确保高质量的数据。第二部分就是去统一车辆的数据资产管理,从“采、治、管、用”四个阶段进行车联网数据的全生命周期的一个跟踪管理,去确保数据的隐私安全。
车联网的数据主要是分为四块,也就是我们的车况大数据,主要包含那种高速看和内线上的那种电车信号、速度和四门两盖的信号,交互大数据主要就是包含智能座舱的信号,然后驾驶和环境大数据主要是感知数据和高精地图相关的一些数据。

最后一个阶段启智,就是通过端云结合的方式,去构建自动驾驶的数据闭环,构建从数据采集、数据处理、模型训练、控制标定、模型与软件升级的这样的一个闭环机制。
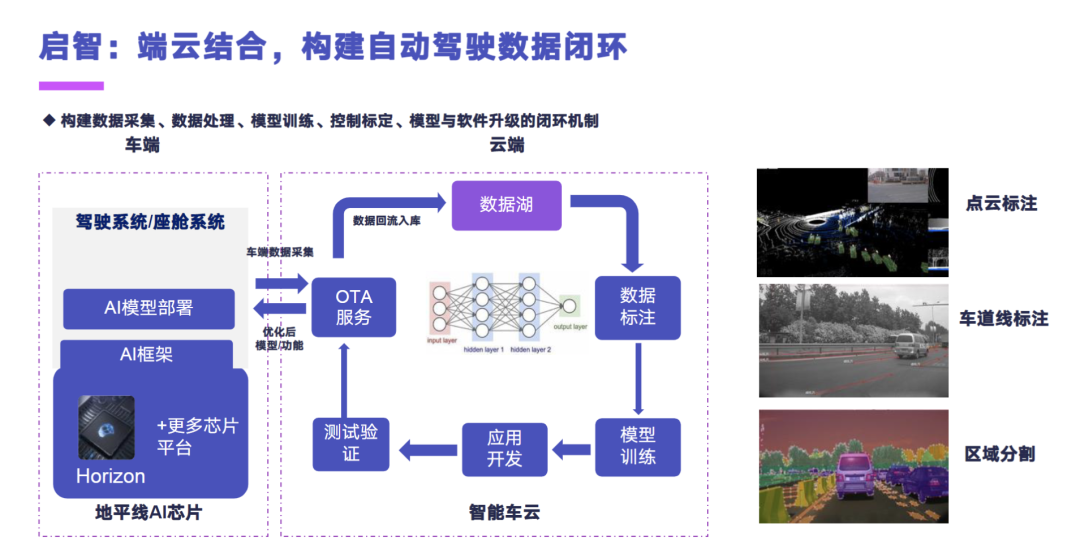
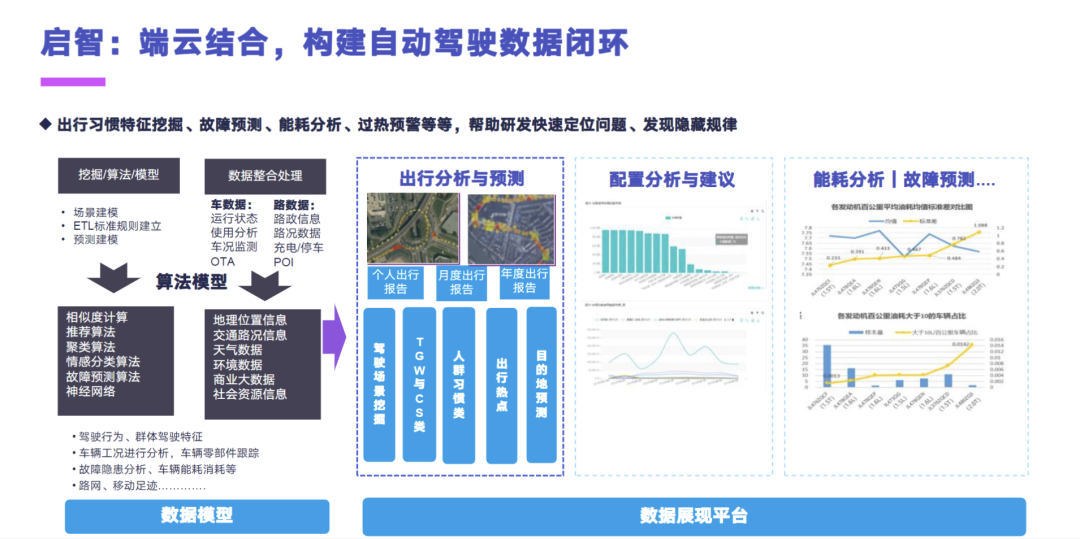
然后在长安内部是也做了一些相应的出行习惯特征挖掘、故障预测、能耗分析的场景,我们有月度和年度的用户的出行的报告,和分析的目的地预测这样一个报告,然后也会为用户提供一些配置分析与建议,还有一个就是支持我们内部做动力分析的这样一个能耗分析,和车辆的故障的预测和诊断的参数。
02 长安智能汽车云大数据处理架构
第二部分介绍的是长安智能汽车云的一个大数据处理架构。
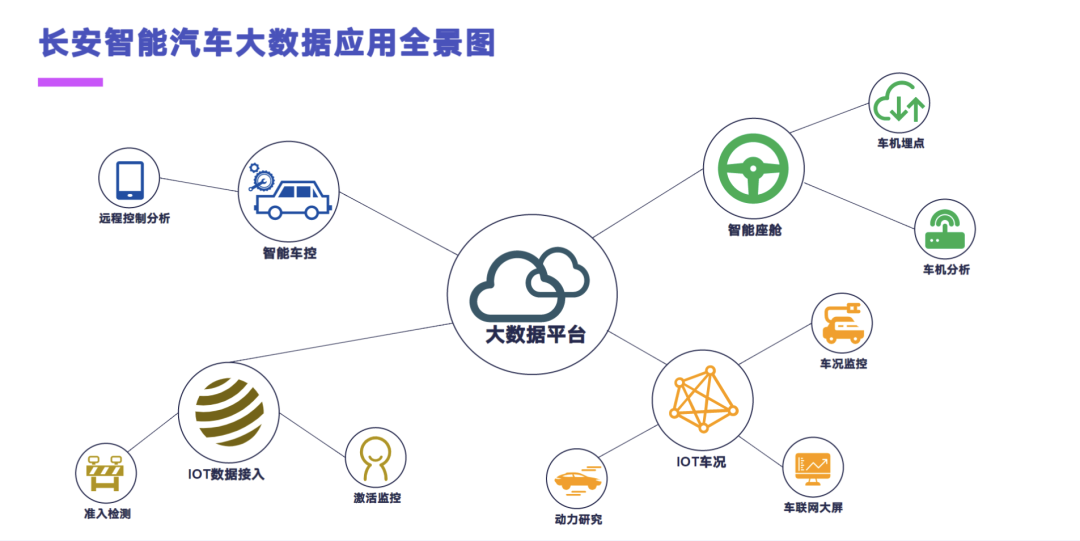
其实车联网在长安这边的应用全景图主要包含四个部分,刚才已经提到了,就是我们的车控、座舱、IoT 的数据接入和 IoT 的车况管理。车况这块其实主要集中于远程控制的分析;然后座舱主要是车机埋点和车机的用户行为。IoT 数据接入这块包含准入检测和一些实名的,或者是我们车机的一些激活监控。最后是 IoT 的车况,IoT 的车况其实这一点是面向内部的研发场景,主要做的第一个就是车况的监控,这一块是直接可以 To C 的,去做到比如说用户的胎压异常或者是车门异常。然后在动力研究这块是做内部的一些油耗分析,或者是我们新能源车的一些电池的三电分析。最后就是刚才看到的那一块车联网的大屏。
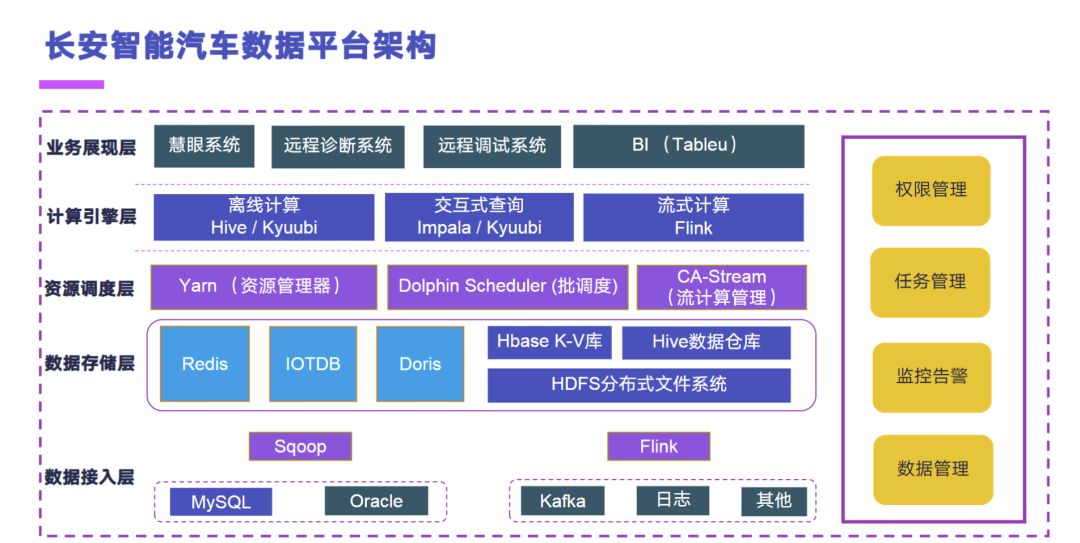
下面介绍一下长安智能汽车数据平台的架构,我们内部也是基于 Hadoop 生态去构建的整个车联网的一个大数据处理平台,一共分为五层。在数据接入层上,离线的运行主要采用的是 Sqoop,实时的引擎主要采用的是 Flink,然后目前正在验证 Apache SeaTunnel,希望可以完成 Sqoop 引擎的一个效率的提升和任务稳定性的一个提升。Flink 这块的话,我们之前是用的 Flume,目前已经用 Flink 完成了整体的实时数据集成的一个任务替代。
然后第二个是数据存储层,除了常见的 HDFS、Hive、和 Hbase 之外,我们引入了 Doris、IoTDB 和 Redis 去应对车联网的这种海量的时序数据的一个管理。Doris 主要用做实时数据结果的一个承接;IoTDB 的话,目前我们做了内部验证,是正在做车况数据的一个 last 点查询和历史车况存储这样的一个查询的场景;然后 Redis 是目前我们投产的做实时车况的一个组件。
在资源调度层上,除了 Yarn 之外,在离线任务编排上我们是引入了 Dolphin Scheduler,然后长安内部是从一点一点开始做适用,一直跟到了目前的生产环境上跑的是 1.3.9,然后正在做 3.X 版本的一个验证。在流应用管理上,我们在 Flink 之上构建了一套 CA-Stream,就是比较简单的一个流计算管理引擎,它主要实现的这样的功能就是对 Flink 任务做一些状态的监控、任务的提交以及配置文件参数的修改,还有 Flink SQL 任务的一个管理。
在计算引擎层上,除了那种 Hive 和 Impala 之外,我们引入了 Kyuubi 这个组件,这个也是今年做的,然后已经是完成了我们 50%-60% 的离线任务,从 Hive 往 kyuubi 上做迁移,去做整体的一个计算稳定性和效率的提升。实时计算引擎上我们主要就是采用 Flink。
然后业务展现层上,就是之前的业务应用介绍到的,我们做内部的研发的 BI 系统、慧眼系统,然后做车辆远程诊断和远程预警的系统,还有做远程调试的系统。最后就是我们用到的一个 BI 组件了,目前是基于 Tableau 做的。
然后整个右侧的这种大数据平台本身的管理,我们是 Cloudera 的一个客户,然后是用到了 Cloudera 的 Hadoop 发行版。
车联网的数据集成这块,长安是一个比较典型的一个混合云的架构,公有云采用的是腾讯云,私有云是在自建的 IDC 里面。我们的车载设备通过自己的 Tbox 或者是 Thu,它会把数据先发到腾讯云的那种 java 后端的应用里面,java应用里面会去完成我们报文的解析。然后通过不同的一个分发引擎,根据不同的业务分发到 Kafka 里,群发到我们公有云上的 Kafka。然后再通过 Flink 引擎,会把公有云的 Kafka 数据同步到私有云的 Kafka。
然后到了私有云的Kafka之后,这个时候就会分为两条链路了。第一条是通过 Flume 直接往私有云的数据平台落,这一块的话我们基本上已经完成了改造了,已经用 Flink 统一引擎来完成这种离线的数据写入和实时的计算了。针对 MySQL 的场景,针对我们部分核心数据库的 CDC 的场景,我们还是利用了 Canal 去把这些变化的数据摄取到 Kafka 里,然后也是通过两条链路,一条实时走 Flink,一条离线走 Flume 下去的。

整个长安的数据处理架构是一个典型的 Lambda 架构,也就是流批混跑的,然后我们的这个智能车云它主要是基于这个 Lambda 架构,去构建的整个的实时计算和离线计算的 PipeLine,然后去实现整个车联网、大数据的有序处理和应用。
在树仓分层这块,其实也是业界比较主流的方案吧,就是 ODS、DWD、DWS 和 DM。DWD 做一些轻度聚合的明细数据,DWS 做中度聚合,DM 直接生成结构表。DM 这块其实我们目前正在往 Doris 里面做迁移。
实时计算的链路上,主要就是通过 Kafka 作为实时的数据仓库,然后通过 Flink 也是两条链路。有一条的话是通过原始数据经过 Flink 直接落到 Doris 里面去,然后通过后端的 Doris 上的那些物化视图或者 RollUp 表,去完成这种实时数仓的计算。第二个就是做大屏的场景,做大屏的场景我们其实会直接通过 Flink 算结果,把它算到 Redis 里面,然后直接用后端的应用来查 Redis。

03 IoTDB 在长安大规模时序车况场景的实践
第三部分就是介绍一下 IoTDB 在长安的一个大规模时序车况场景的实践。
车联网其实是一个非常典型的这种物联网的场景,那么物联网的场景它的数据一定是时序数据。整个时序数据的生命周期,其实分为采集、缓存、处理、存储、查询/分析和可视化应用这六个大的一个阶段。
在采集这一块,其实主要就是我们的设备和传感器,对应到车联网上就是我们的 Tbox 和 Thu。缓存的时候通过边缘的网关,当然我们不是每一类的数据都需要做到那种实时的上传,有的数据它会在本地先做一个比如说五秒或者十秒的缓存,然后再批量的去往云端做发送,这个就是缓存。到了云上之后,就会通过应用摄取到这个报文,做一定的解析,发到消息队列里面,然后再通过一个消息分发这样的一个组件,把不同业务所需要的时序消息分发到不同的存储端上。最后就是可以利用我们的这个计算平台,也就是其实一般已经到了 java 应用的部分了,就是我们的后端引擎会直接对到存储引擎上,去做可视化的一些应用。
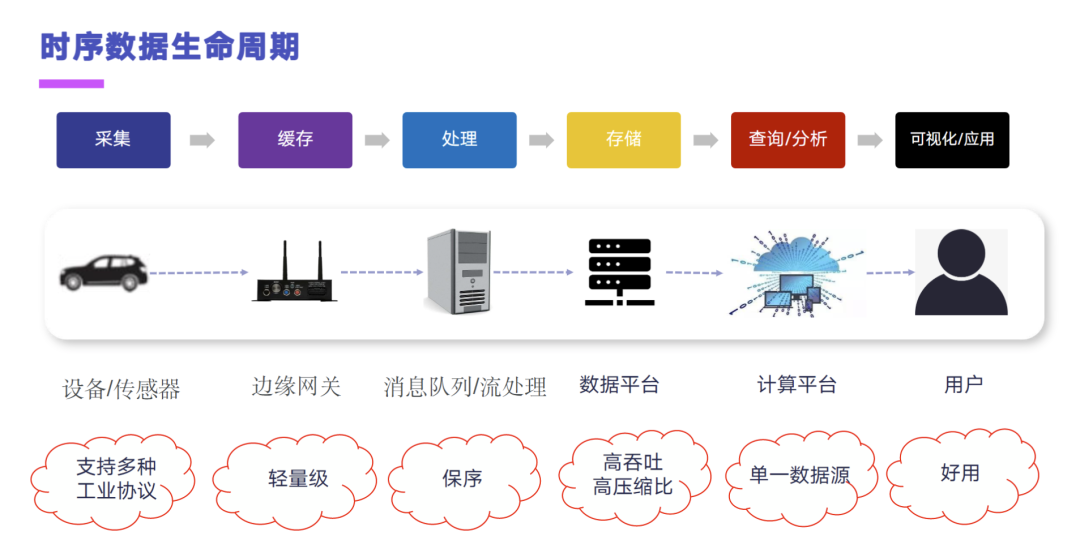
车联网的这个海量时序车况管理的挑战,其实主要还是一个体量的问题,因为长安目前它是一个以量产车为主的这样一个场景,目前的话我们整个平台接入了近三百万的网联车。然后大的挑战主要就有三个,第一个是百万级车辆的一个海量车况的高效传输和处理。
第二是我们的信号,它是分为这种高速信号,它是毫秒级采集的,常规信号是 30 秒一采的,平均下来的话,它的那个数据量每秒的话基本上是百万条。
然后单车的一个多时间序列的一个高效查询和单车全时间序列的最新点的查询,其实这个就是车联网里面很经典的实时车况和离线车况,也就是我们历史车况的一个查询场景。当然有的平台架构上也叫做设备影子这样一个功能。大的来看的话就是三个挑战,体量大、高速性和数据的一个多样性。

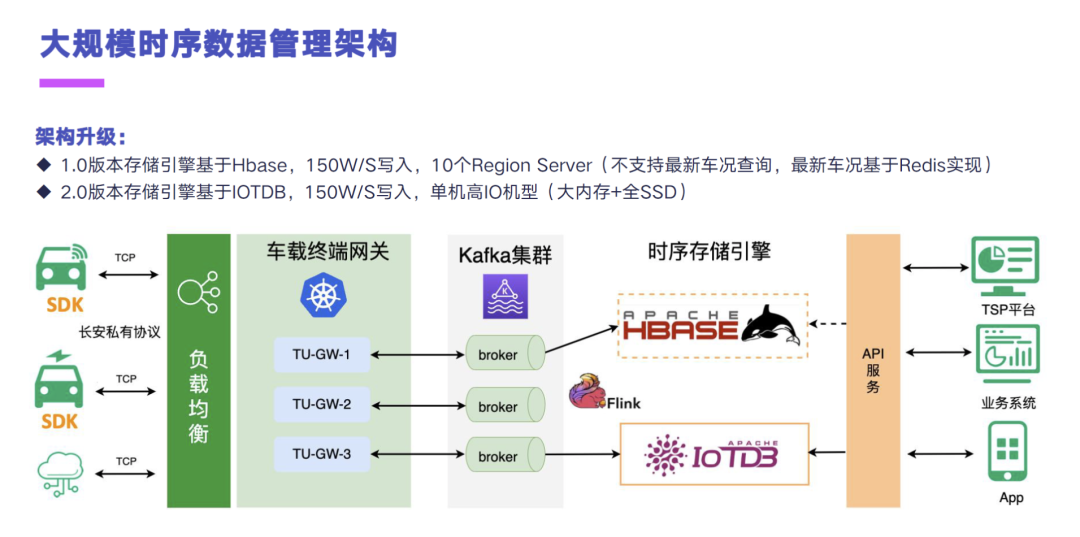
目前长安内部的一个大规模时序数据管理的架构,分为 1.0 和 2.0 的版本。其实刚才已经提到了,我们车上的这个 Tbox、Thu,去基于长安私有的 TCP 协议,然后我们自己基于 Netty,去写了一套网关接报文的,通过 CLB 进到 K8s 的 TU-GW 应用里面之后,就会去对报文做解析。解析完之后再通过后面的那些业务的应用和分发引擎,将这些车况的数据和报文的数据分发到不同的 Kafka 集群里面。
然后我们针对车况这个场景,主要的时序存储引擎是 HBase,也就是我们的历史车况会往 HBase 里面写。然后 2.0 的架构,我们就是采用了 Flink 接 Kafka 的数据写入 IoTDB。整个架构升级上,我们目前做测试的体量是差不多一秒 150 万条数据,然后一条数据的话差不多是有 15 到 20 个测点的样子,平均的话可能也就 16、17 个测点。
然后在差不多千万级的写入体量下的话,我们之前的 HBase 集群是有 10 个Region Server,并且 HBase 它的存储架构的话,因为我们没有使用 OpenTSDB 那样的引擎,它是不支持这种最新车况的查询的,我们之前的那一版最新车况是基于 Redis 实现的。
目前我们做的 2.0 的版本,就可以通过统一的引擎 IoTDB,来完成一秒 150 万车况数据的一个写入。然后现在我们测的这个场景是采用了一个单机高 IO 的机型,也就是我们的大内存+全 SSD 这样的一个集群。内存差不多是 384G,然后应该是有接近 50 个 T 的 SSD,然后是单机,采用的是 0.12.3 的一个版本。写入到存储引擎之后,后面就是我们的 TSP 业务系统和 APP 针对我这辆车的一个最新数据和历史车况,这两个场景来做一个查询了。
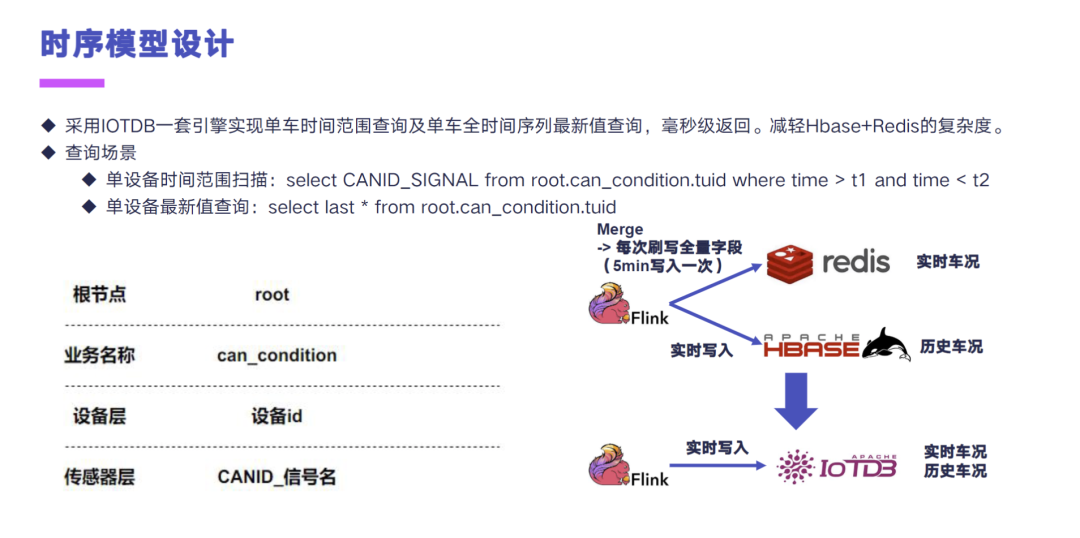
整个时序模型设计这块的话,我们采用了 IoTDB 一套引擎,去实现了单车时间范围的查询和单车全时间序列最新点的查询,然后测出来目前都是毫秒级返回,准备是用这一套方案去替换掉 HBase+Redis 方案的一个复杂度。
那针对查询来看的话,单设备的时间范围的查询就采用了这种 select,然后前面加上了 CANID、加信号名称,然后 from 这样的一个存储结构。这个存储结构当时为什么那么设计呢?就是根和业务名称就不说了,在设备层我们采用的是 Tbox 的 TUID,也就是设备 ID,作为它的一个第三级节点。最后其实就是在测点层,测点层除了信号名之外,我们在前面给它拼上了 CANID,这个也是想利用 IoTDB 的那种 select,然后下滑线带 * 这样的查询,可以查出来这一辆车在某一个 CANID 下面的所有的信号,去做这样的一个查询场景。
基于这样的一个模型设计,我们就可以采用这种单设备的时间范围扫描,就是带 TS 和不带 TS 的这种 last * 的场景,去完成我们之前要采用两套引擎实现的这个车联网场景下的一个实时车况和历史车况组合查询这样一个场景。
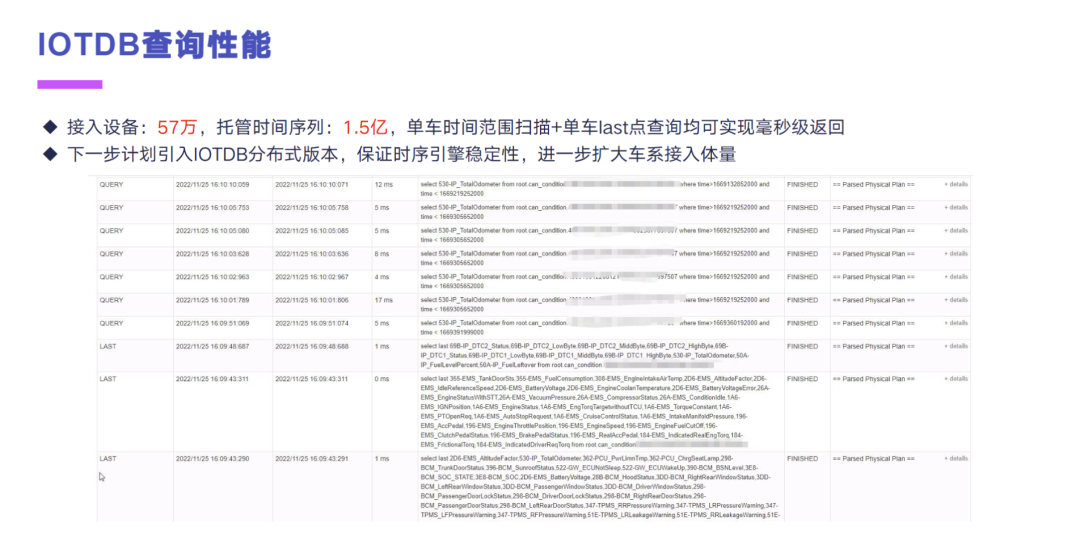
IoTDB 在长安的查询的一个性能上来看的话,我们目前就是单机接入了差不多 57 万的设备,托管了时间序列是 1.5 亿,然后单车的一个时间范围扫描和单车 last 点的查询,均可以实现毫秒级的返回。下一步的话,我们是计划去引入 IoTDB 的分布式版本,去保证时序引擎的一个稳定性,进一步去扩大车系的一个接入体量。
这一块为什么还没有把 IoTDB 投产到我们的生产环境里面,去做 To C 的一些业务呢?是因为我们在测 12 版本的分布式引擎的时候,发现之前那版的分布式版本的实现,它并不能解决大的元数据的问题。因为长安目前是量产车,现在接了 57 万、托管的时间序列差不多有 1.5 亿,单机的内存管理上,我们针对元数据这块,内存分配是做过了多次调整的,才能保证这个单机目前运行了差不多有一年的样子。当时测出来的那个时序版本,它的稳定性还有待进一步提升,然后在本次就是 IoTDB 发布的这个 1.0 版本,新的分布式引擎的场景下的话,我们是会去做进一步测试的。
04 长安智能汽车数据平台架构展望
最后分享一下长安智能汽车数据平台的一个架构展望。
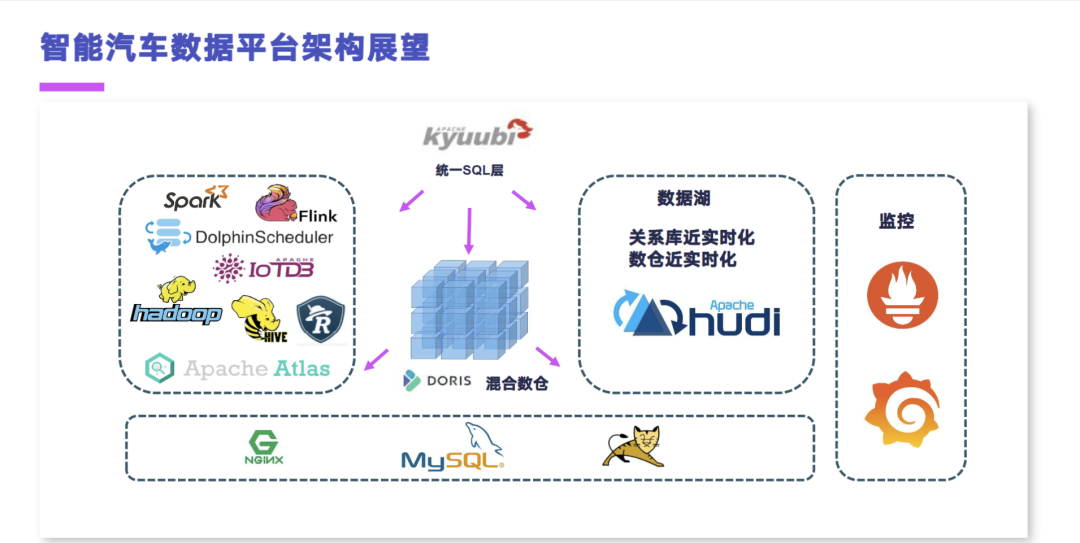
总的来说目前长安基于 Cloudera 的 Hadoop 发行版,和 Apache 提供的一些开源的组件,像 Doris、Kyuubi、IoTDB 去补齐了相关的智能汽车特定场景下的这种大规模时序管理、实时数仓和离线加速的一些场景。但是我们仍然有三个地方需要去做增强和改进的。
那么第一点就是,整个的关系库的近实时化和离线数仓的近实时化,这块是亟待解决的。因为目前来说,我们仍然是采用 Sqoop 或者是 SeaTunnel,然后在每天的凌晨去大量的拖关系库的表,去做离线数仓的数据摄取。然后这块我们是希望可以引入这种现在比较热的一些数据库框架,像 Hudi 或 Iceberg 这样的框架,去解决我们的一个数仓近实时化,和关系库的一个数据增量摄取的问题。
第二点就是 Kyuubi 这个引擎。我们目前仅仅是用来做离线数仓的一个任务加速,但是并没有把它作为一个统一的这个 SQL 网关层或者 SQL 路由层,给对接到我们所有的存储引擎上,像可以把 Hive 和 Doris,包括我们后续引入的数据库框架对接上,那么它就可以统一的作为一个 SQL 网关来使用。然后做了统一的 SQL 网关之后,我们的数据血缘就不再需要去使用到这个 Apache Atlas 这样的组件了,我们可以在 SQL 网关层去加一些插件做血缘解析。只要把入口管住了,其实我们很多东西,包括血缘和权限这两块,实现起来都会更加的轻量和容易。
然后第三点就是刚才提到的我们的 IoTDB,目前还是用的一个单机的版本,去面向企业内部研发工程师做故障排查的场景,去查这个离线和实时的车况。然后这块的话,我们是希望就是应用到最近 IoTDB 发布的这个 V1.0 版本的新的分布式引擎,去能够实现一个大规模网联车的接入。最好是能够直接去替换掉我们现在现有的 Redis 和 HBase 这两套基于车况的实时和离线的这种历史车况的实现,去减轻整个架构的复杂度。
最后也感谢 IoTDB 社区和清华大学带来的这么优秀的一个时序数据引擎。以上就是我分享的全部内容,谢谢大家。
更多内容推荐:
• 了解更多 IoTDB 应用案例
• 回顾 IoTDB 2022 大会全内容


