

本文基于一次真实的 IoTDB 1.3.3 单副本 3C3D 集群搬迁,整理出 9 个可复用脚本、关键参数含义,以及 load 过程中最容易踩的 5 个坑。适合需要在不停业务写入的前提下,把 TsFile 从 A 集群搬到 B 集群的运维同学参考。
一、为什么用 TsFile 搬迁
IoTDB 的 TsFile 是列式时序存储文件,搬迁 TsFile 相当于搬运"数据块",相比 SQL 导出再写入:
- 无需重新解析和序列化,吞吐更高
- 保留原始编码、压缩、索引结构
- 通过
load命令即可把历史数据注入新集群- 适合 TB 级、百亿点时序数据的大批量迁移
二、整体流程
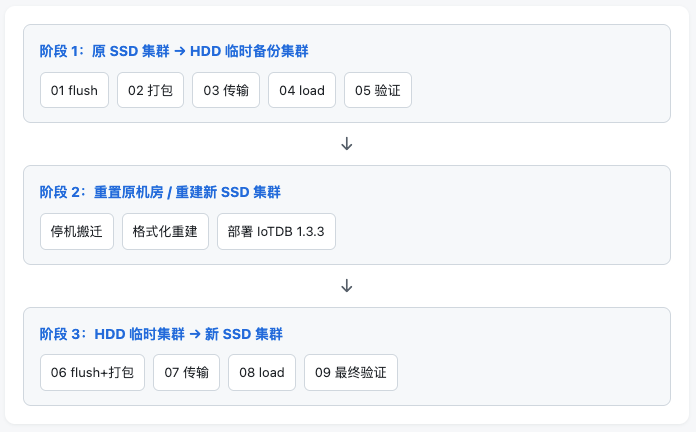
三、环境假设
- 源集群、HDD 临时集群、新 SSD 目标集群均为 IoTDB 1.3.3
- 均为 3 个 ConfigNode + 3 个 DataNode(3C3D)
- 采用 单副本:
data_replication_factor=1、schema_replication_factor=1- 脚本执行机已对 6 台节点配置 SSH 免密登录
- 目标集群已创建与原集群一致的 database
四、9 步脚本详解
以下脚本默认放在同一目录,先修改 00_env.conf 中的 IP、路径、密码,再按顺序执行。
Step 01 flush:把 MemTable 落盘成完整 TsFile
#!/bin/bash
set -e
source ./00_env.conf
flush_node() {
local node_ip=$1
local node_name=$2
echo ">>> 正在对 ${node_name}(${node_ip}) 执行 flush..."
ssh ${SSH_USER}@${node_ip} "
cd ${SSD_IOTDB_HOME}
./sbin/start-cli.sh -h ${node_ip} -p ${IOTDB_CLI_PORT} \
-u ${IOTDB_CLI_USER} -pw ${IOTDB_CLI_PASS} -e 'flush;'
"
}
flush_node ${SSD_NODE1_IP} "SSD-Node1"
flush_node ${SSD_NODE2_IP} "SSD-Node2"
flush_node ${SSD_NODE3_IP} "SSD-Node3"要点:flush 是节点级操作,3 个 DataNode 都要执行。flush 后建议等待 2-3 分钟,确保后台文件写入完成。
Step 02 打包:保留目录结构和元数据
ssh ${SSH_USER}@${node_ip} "
cd ${SSD_DATA_DIR}
# 序列化和非序列化数据
tar czf ${LOCAL_TMP_DIR}/${pkg_name}_data.tar.gz sequence/ unsequence/
# .resource 和 .mods 必须一起打包
find ${SSD_DATA_DIR} -type f \( -name '*.resource' -o -name '*.mods' \) | \
tar czf ${LOCAL_TMP_DIR}/${pkg_name}_meta.tar.gz -T -
"注意:不能只拷贝 .tsfile。.resource 是索引文件,.mods 记录删除标记,漏带会导致 load 重建索引或丢失删除操作。
Step 03 传输:保持 node1→node1 的对应关系
单副本集群的数据分片分散在 3 个节点,搬迁时要保持分片对应,不能混装。脚本用 scp 把每个 SSD 节点的包传到 HDD 集群对应节点。
Step 04 load:把 TsFile 注入 HDD 临时集群
#方案1 登录到控制台,使用命令load ./sbin/start-cli.sh -h ${node_ip} -p ${IOTDB_CLI_PORT} \
-u ${IOTDB_CLI_USER} -pw ${IOTDB_CLI_PASS} -e "
load '${HDD_BACKUP_DIR}/tsfile_data/sequence/'
with ('onSuccess'='none', 'verify'='true');" #方案2 使用IoTDB自带的tools脚本工具(推荐) #序列化数据 nohup ./load-tsfile.sh -h 127.0.0.1 -p 6667 -u root -pw root -s /data/backup_from_ssd/tsfile_data/sequence/ -tn 6 -os none -of none > /data/load_erros/load_se.log #非序列化数据 nohup ./load-tsfile.sh -h 127.0.0.1 -p 6667 -u root -pw root -s /data/backup_from_ssd/tsfile_data/unsequence/ -tn 6 -os none -of none > /data/load_erros/load_unse.log参数解释:onSuccess='none' 表示加载成功后不删除源文件,便于重复验证;verify='true' 开启文件校验,提前发现损坏。具体案例中我使用了方案2,有日志输出便于分析。
Step 05 验证:四件套检查
# 1. database 列表
show databases;
# 2. 时序数量
show timeseries root.**;
# 3. 总数据点数
select count(*) from root.**;
# 4. TsFile 文件数量 + 磁盘占用
find ${HDD_DATA_DIR} -name '*.tsfile' | wc -l
du -sh ${HDD_DATA_DIR}参数解释:迁移前一定要预留充足的磁盘空间。
Step 06-09 回迁:HDD → 新 SSD
逻辑与阶段 1 对称:对 HDD 集群执行 flush + 打包,传回新 SSD 集群对应节点,再 load 并做最终验证。这里不再重复贴代码,可直接复用阶段 1 的脚本模式。
五、脚本清单
脚本说明:实际操作的脚本内容可参看我另外一篇文章:《10TB、20天、公有云接力:一次 IoTDB 数据迁移的真实复盘》
六、关键参数配置
七、踩坑清单
八、环境配置模板
# ---- SSD 原集群(3个DataNode)----
SSD_NODE1_IP=192.168.1.11
SSD_NODE2_IP=192.168.1.12
SSD_NODE3_IP=192.168.1.13
SSD_IOTDB_HOME=/opt/iotdb-1.3.3
SSD_DATA_DIR=/opt/iotdb-1.3.3/data/datanode/data
# ---- HDD 临时集群 ----
HDD_NODE1_IP=192.168.2.21
HDD_NODE2_IP=192.168.2.22
HDD_NODE3_IP=192.168.2.23
HDD_BACKUP_DIR=/data/backup_from_ssd
# ---- 新 SSD 目标集群 ----
NEW_SSD_NODE1_IP=192.168.1.31
NEW_SSD_NODE2_IP=192.168.1.32
NEW_SSD_NODE3_IP=192.168.1.33
NEW_SSD_BACKUP_DIR=/data/backup_from_hdd
# ---- IoTDB 连接信息 ----
IOTDB_CLI_USER=root
IOTDB_CLI_PASS=root
IOTDB_CLI_PORT=6667
SSH_USER=root九、什么场景适合这套方案
- 源和目标集群版本一致,且可以短期停机做 flush
- 数据量达到 TB 级,SQL 导出/写入不可接受
- 有中间临时集群(或单机大磁盘)作为跳板
- 需要保留历史数据的时间序列结构、编码和压缩方式
不适合的场景:源和目标版本不一致;需要实时同步、零停机的在线迁移;对多副本强一致有要求的环境。


