

一家航空公司每天面对海量飞机零部件数据,想在彻底故障之前,就知道什么时候该修了。
一座城市电网想预测居民用电量,却说不清多类变量的影响具体有多大、关系怎么衡量。
一个工厂的设备管理者盯着一条数据曲线,看得出趋势异常,但更希望知道“什么时候需要介入”。
这些场景有一个共同的名字:时序数据分析与预测。而它们也有一个共同的困境:数据存好了,但用不起来。
前不久,天谋科技做了一场围绕时序大模型服务平台 TimechoAI 的公开分享,聊的正是这件事:时序大模型,到底能不能帮工业场景把“存储时序数据”变成“预测时序数据的能力”。
01 一个老问题:数据存下来了,然后呢?
在很多工业项目里,时序数据库已经被广泛使用。能源电力的发电、储能设备,航天航空的飞行器零部件、车联网的行驶与出厂车辆……每一秒都在产生数据,也在被时序数据库存储。
但客户最常问的一个问题是:“我把时序数据存下来了,接下来要怎么用?”
举个例子。一架民航客机上有成千上万个零部件。航空公司需要定期检修,但如果能提前发现某个零件的异常趋势,就可以变“定期修”为“预测性维护”,避免飞行中出故障,也避免因为突发停飞造成巨大损失。
这个需求听起来很合理。但在过去,要真正把它落地,远比想象中复杂。

02 传统解法:三类专家、六步流程
没有大模型的时候,做一个时序预测项目,通常需要三类人:
领域专家:懂设备、懂零件、懂业务,负责回答“什么问题值得解决”。
算法工程师:懂模型、懂训练、懂调参,负责回答“这个问题能不能用算法解”。
数据工程师:懂采集、懂清洗、懂存储,负责把训练模型的数据准备好。
这三类人要坐在一起,反复磨合,这种碰撞可能持续数周甚至数月。

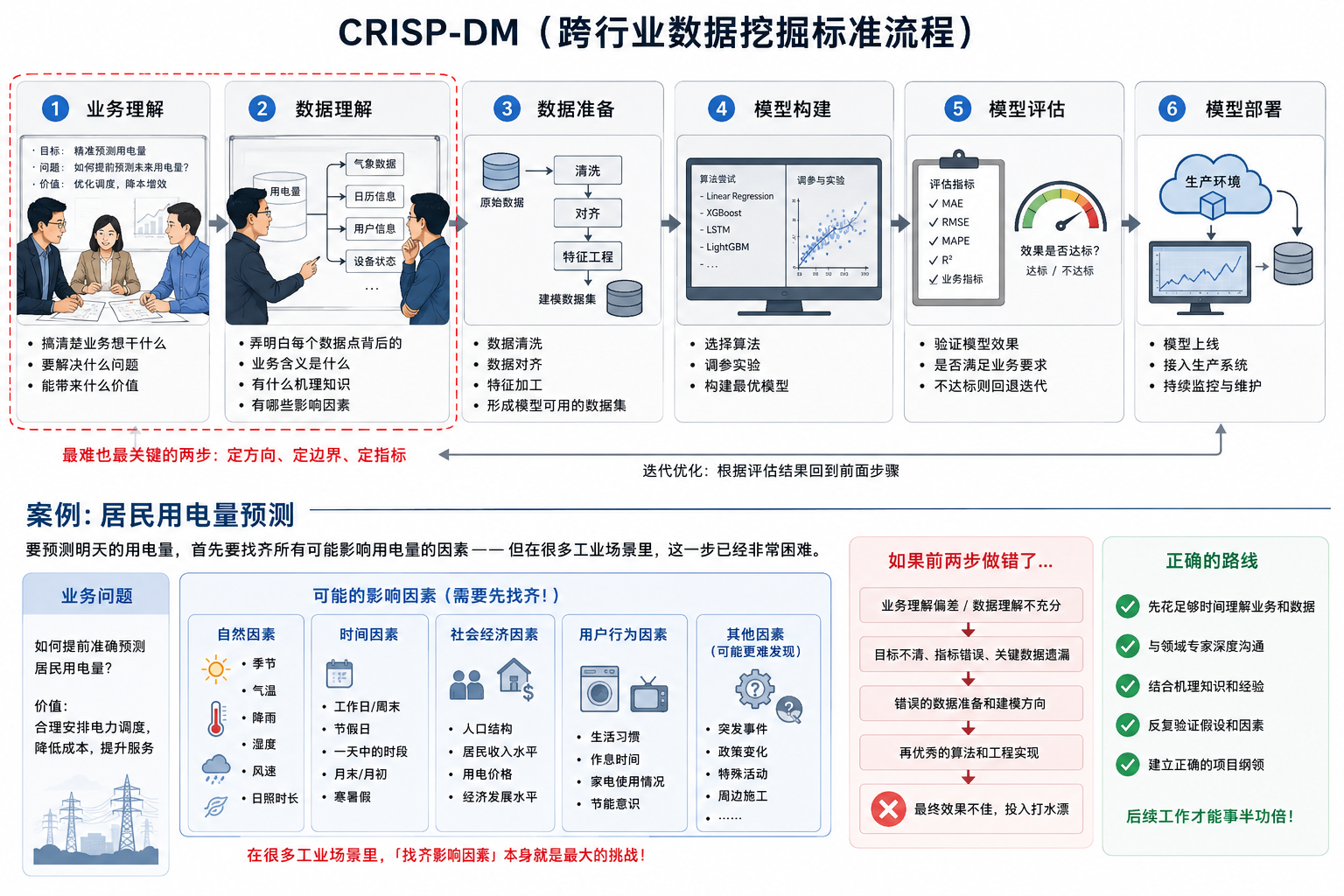
行业内有一个标准流程叫 CRISP-DM(跨行业数据挖掘标准流程),它把数据挖掘项目拆成了六个步骤:
业务理解:搞清楚业务到底想干什么,要解决什么问题,能带来什么价值。
数据理解:弄明白每个数据点背后的业务含义是什么,有什么机理知识。
数据准备:把原始数据清洗、对齐、加工成模型能用的格式。
模型构建:尝试不同算法,调参数,做实验,找到最合适的模型。
模型评估:验证模型效果是否达标,不达标就退回前面步骤重新来。
模型部署:把模型正式上线到生产环境中去运行。
其中,最难的往往是前两步:业务理解与数据理解。这两步就像整个项目的纲领,如果纲领错了,后面所有数据工程师和算法工程师的投入都可能打水漂。
比如预测居民用电量,你需要先找齐那些可能影响用电量的因素——季节、气温、降雨等等。但在很多工业场景里,光是“找齐影响因素”这一步,就已经非常困难了。
03 时序大模型的思路:给专家一个“本科毕业生”
面对这个难题,最理想的状态是把领域专家的知识固化下来,甚至把多个专家脑子里的经验形成一个严丝合缝的体系:给一个输入,就能得到一个确定的输出。
但现实是,这个问题是世界性的难题。在没办法用“一个万能模型”简单解决的时候,作为算法工程师和软件从业者,我们能做的,是打造工具和软件,帮助大家更轻松地完成时序智能分析。
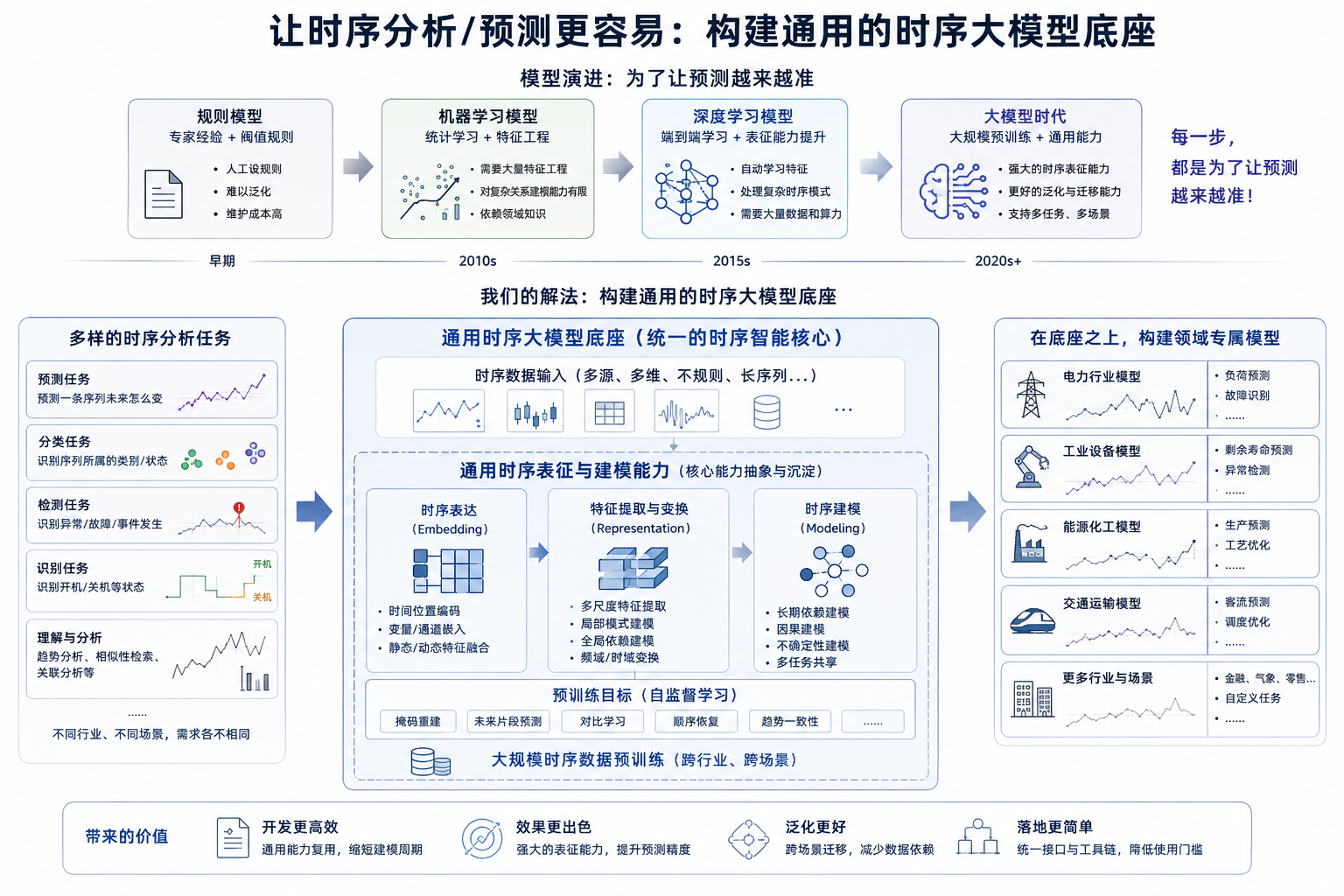
而模型的演进,本身就是这条路上最核心的方向。从最早的规则模型,到机器学习模型,再到深度学习模型,再到今天的大模型——每一步,都是为了让预测越来越准。
因此,我们对“如何让时序分析/预测更容易”这个问题的解法,是构建一个通用的时序大模型底座。
不管是什么样的时序分析任务,比如“预测一条序列未来怎么变”,还是“识别这条曲线数据代表的开机/关机状态”,都需要对时序数据进行表达、特征提取和变换。
把这些通用的基础能力抽象出来,凝聚成一个核心模型,就是时序大模型。用户可以在这个底座之上,再去构建各个领域专属的模型。
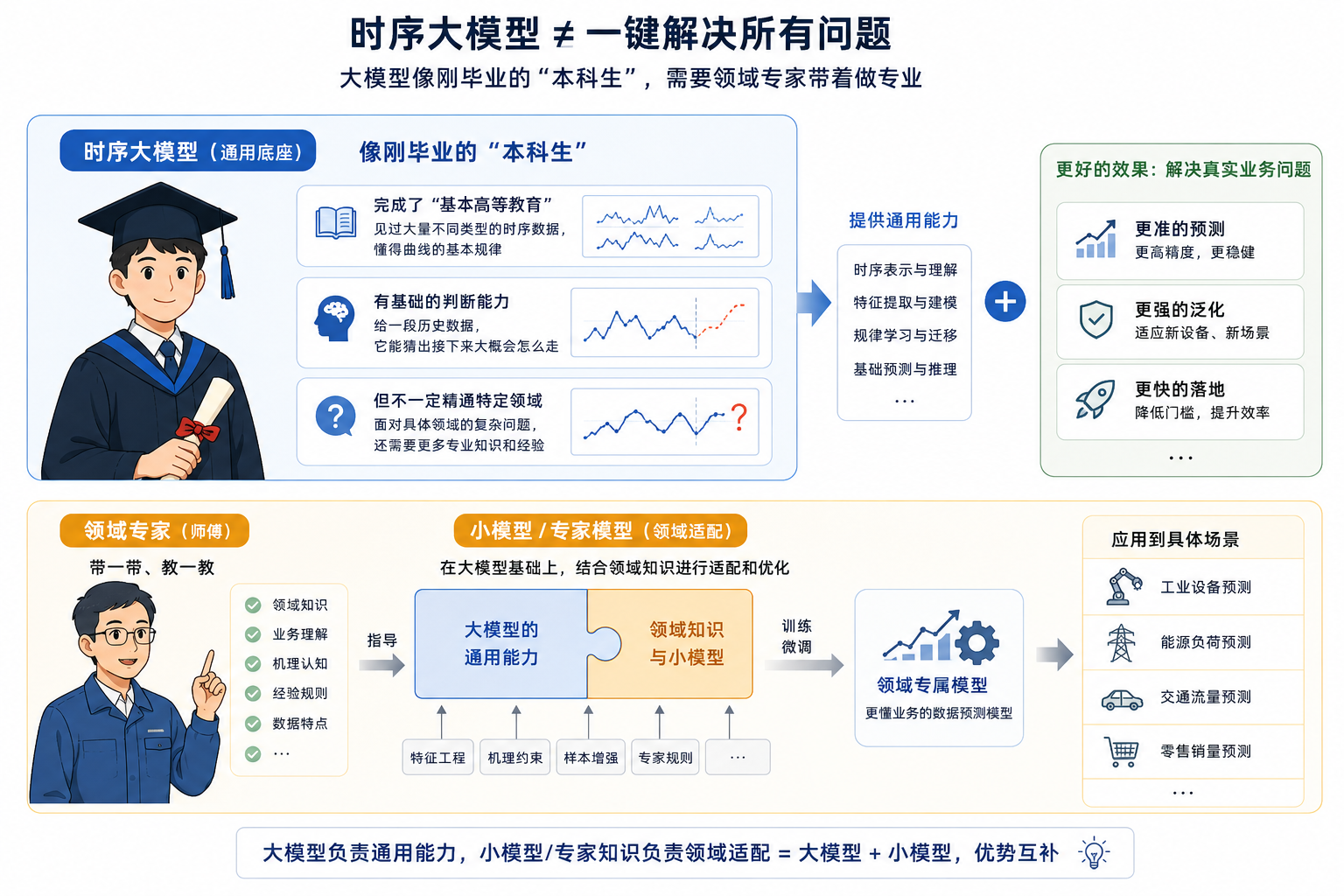
我们并不认为时序大模型能一键解决所有问题,在我们看来,一个成熟的时序大模型,就像一个刚毕业的“本科生”:
它完成了“基本高等教育”——见过大量不同类型的时序数据,懂得曲线的基本规律。
它有基础的判断能力——给一段历史数据,它能猜出接下来大概会怎么走。
但它不一定精通特定领域——真要解决具体领域的数据预测问题,还需要领域专家来“带一带”。
这就是“大模型 + 小模型”的思路。大模型负责通用能力,小模型或专家知识负责领域适配。
04 时序大模型的两个核心价值:降门槛、省数据
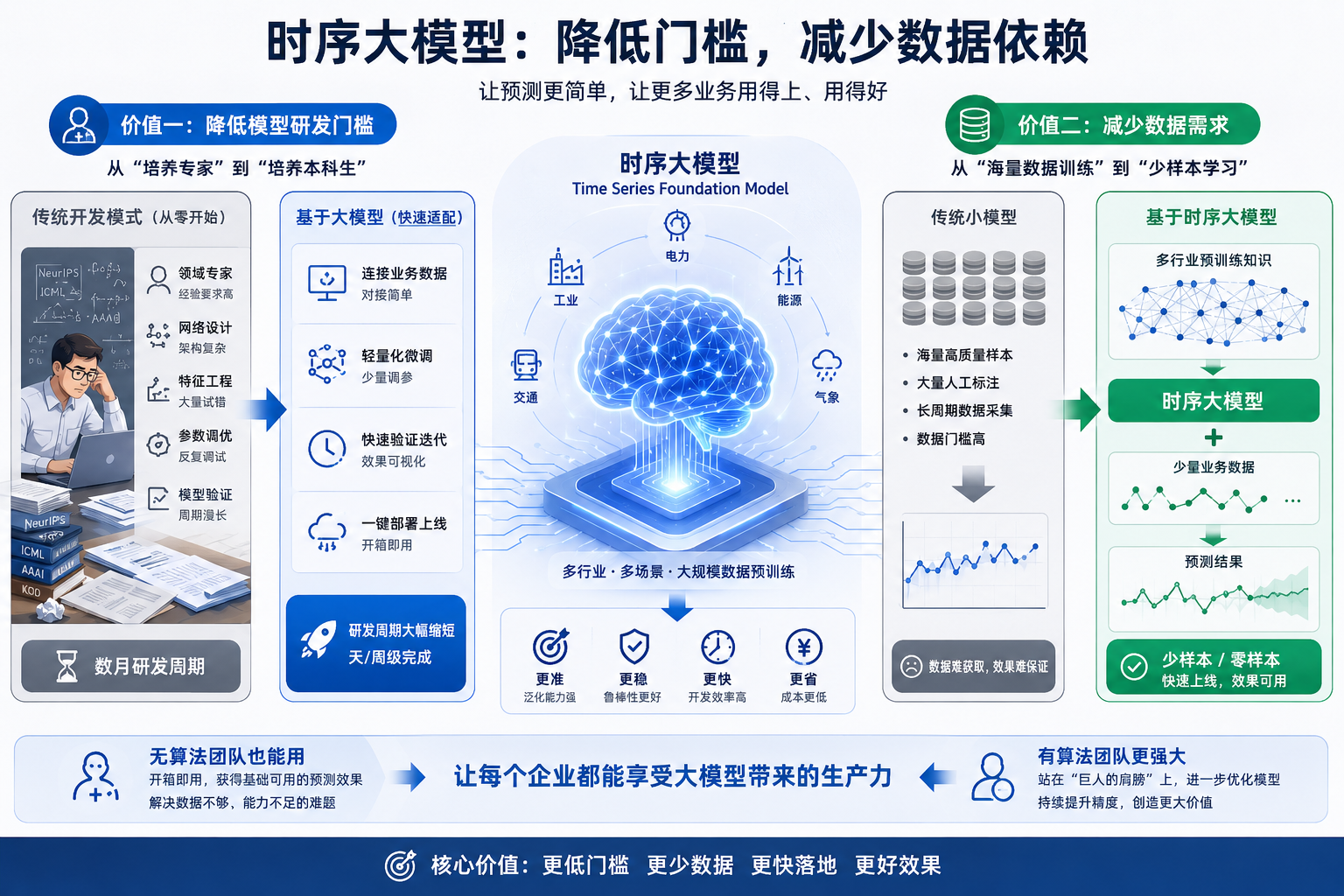
相比从零开始训练一个专属模型,时序大模型带来了两个实实在在的好处:
降低模型研发难度:原来从零设计一个领域模型,从网络架构到参数调优,可能需要数月之久。有了大模型底座之后,在这个基础上做适配,需要的时间会更短。
减少数据需求:纯小模型训练,可能需要大量高质量样本才能达到可用效果。而有了大模型基于多类数据集的预训练知识,对样本数量的需求会显著降低。
甚至在一些场景下,你不需要训练,直接就能用——这就是大模型的“零样本推理”或“开箱即用”能力。那些原来因为数据不够、没有构建小模型的能力而做不起来的需求,现在可能有了解法。
即便没有自己的算法团队,也能用时序大模型获得基础可用的预测效果,对很多简单场景来说已经足够了。而那些拥有算法团队的客户,则可以站在时序大模型这个“巨人的肩膀”上,进一步优化结果精度。
当然,在每一个工业领域,时序大模型具体能发挥多大作用,还需要结合实际场景来验证。所以我们先把时序大模型的能力开放出来,供大家体验。
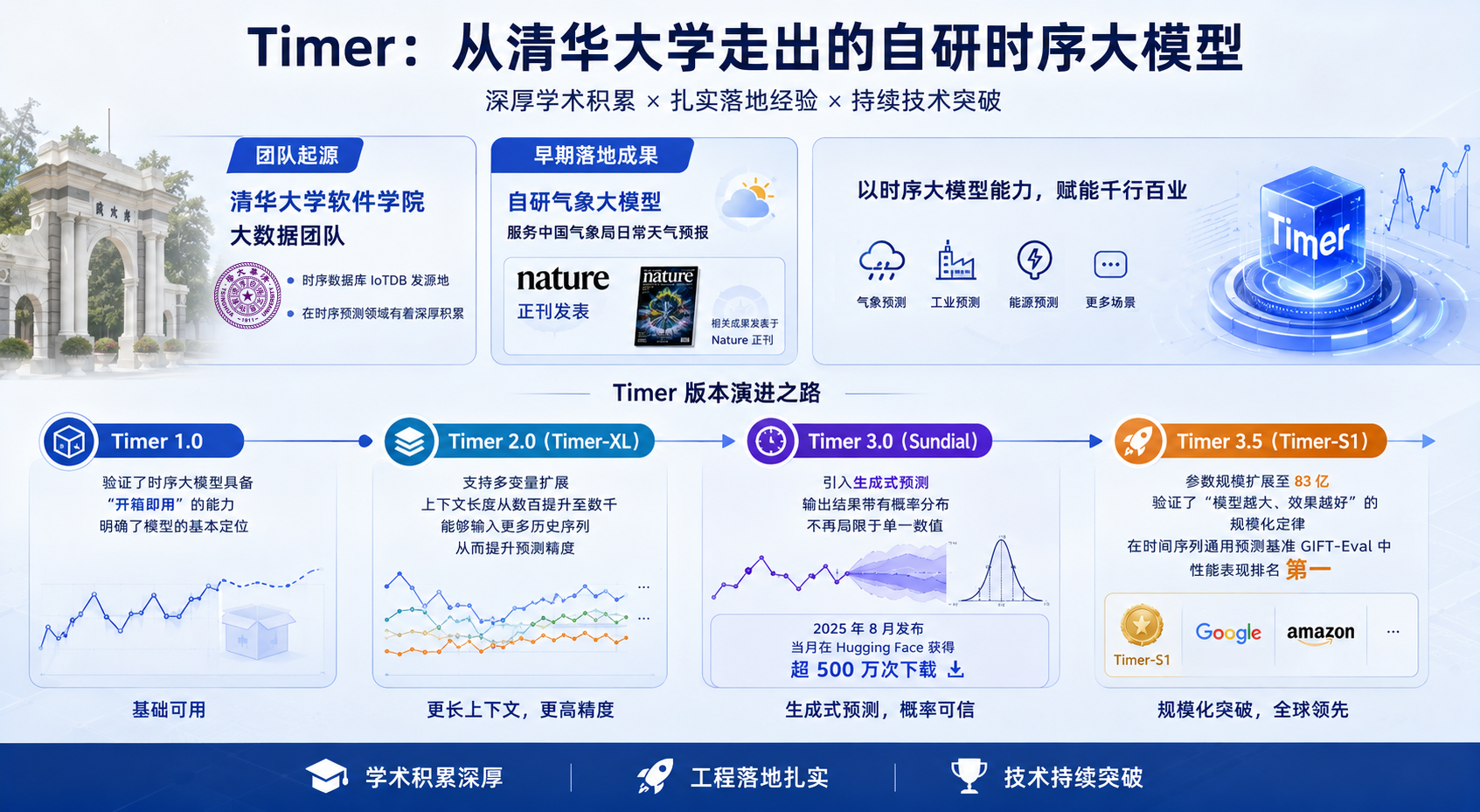
05 Timer:从清华大学走出的自研时序大模型
在聊 TimechoAI 的平台化能力之前,有必要先介绍一下我们自研的时序大模型:Timer。
Timer 背后的团队,来自清华大学软件学院所带领的大数据团队,这也是时序数据库 IoTDB 的发源地,在时序预测领域有着深厚的积累。
早在 Timer 正式发布之前,团队就已经积累了扎实的落地经验:自研气象大模型用于服务中国气象局的日常天气预报,相关成果发表于 Nature 正刊。
至今,Timer 已经迭代了四个版本:
Timer 1.0:验证了时序大模型具备“开箱即用”的能力,明确了模型的基本定位。
Timer 2.0(Timer-XL):支持多变量扩展,上下文长度从数百提升至数千,能够输入更多历史序列,从而提升预测精度。
Timer 3.0(Sundial):引入生成式预测,输出结果带有概率分布,不再局限于单一数值。该版本于 2025 年 8 月发布后,当月便在 Hugging Face 获得超过 500 万次下载。
Timer-3.5(Timer-S1):参数规模扩展至 83 亿,验证了“模型越大、效果越好”的规模化定律,在时间序列通用预测基准 GIFT-Eval 中性能表现排名第一。这一突破也让国产时序大模型具备了与国际大厂(如谷歌、亚马逊)研发模型同台竞技的实力。
06 打开网页就能用:TimechoAI 能帮你做什么
看到这里,你可能已经想试试 Timer 了。而 TimechoAI,就是让你轻松体验 Timer 核心能力的入口。
TimechoAI 是搭载了 Timer 时序大模型的服务平台,在 IoTDB 的基础上,面向时序数据智能分析场景打造。它的定位很直接:当你面对海量时序数据不知如何分析,又觉得接入大模型能力过于复杂时,它可以帮你一把。
从技术本质上看,时序大模型就是一个算法:输入一段历史数据,输出未来的走势预测。最简单的用法是输入一条序列,看它接下来输出怎样的序列。
但在工业场景中,问题往往更复杂。比如你想预测设备温度,但它还受到转速、负载等因素的影响。这时候,你可以把“目标变量”(你想预测的)和“协变量”(影响它的因素)一起交给时序大模型,让它综合考虑。
这正是我们把 Timer 能力上云、打造 TimechoAI 的初衷:降低验证门槛和使用成本,让大家不用折腾环境,就能亲自验证时序大模型在自己场景中的表现。

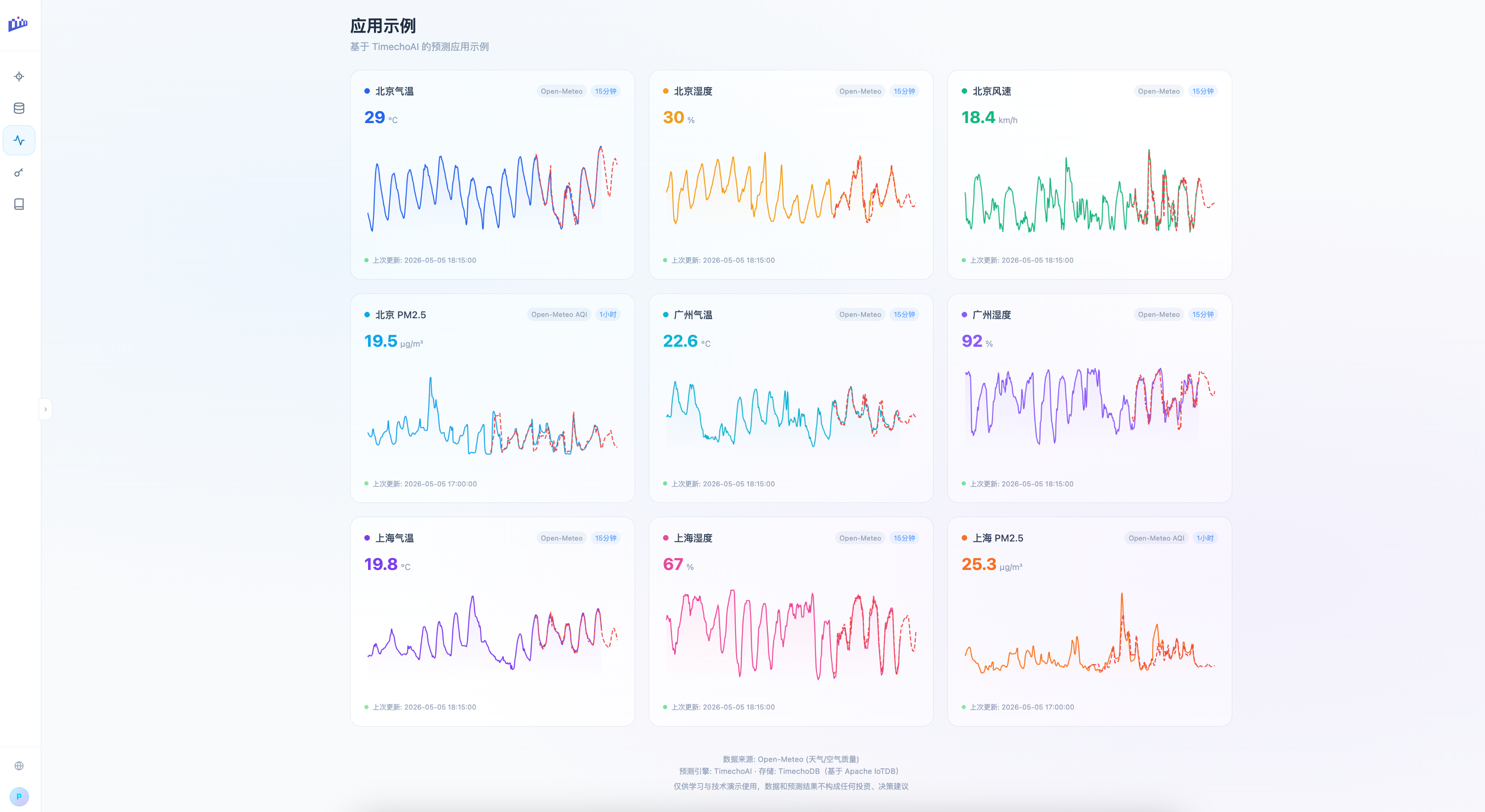
TimechoAI 使用起来很简单:不需要准备 GPU 服务器,不用安装模型,也不用写代码,打开 ai.timecho.com,上传已有的目标变量和协变量数据,系统就会返回未来的趋势预测。
我们还在网站上公开了一些真实的数据集和案例,比如基于气象数据实时预测未来几天的温度。你可以直观地看到时序大模型在做什么,以及它在你的场景中表现如何。
07 从“存”到“用”,我们还在不断扩展
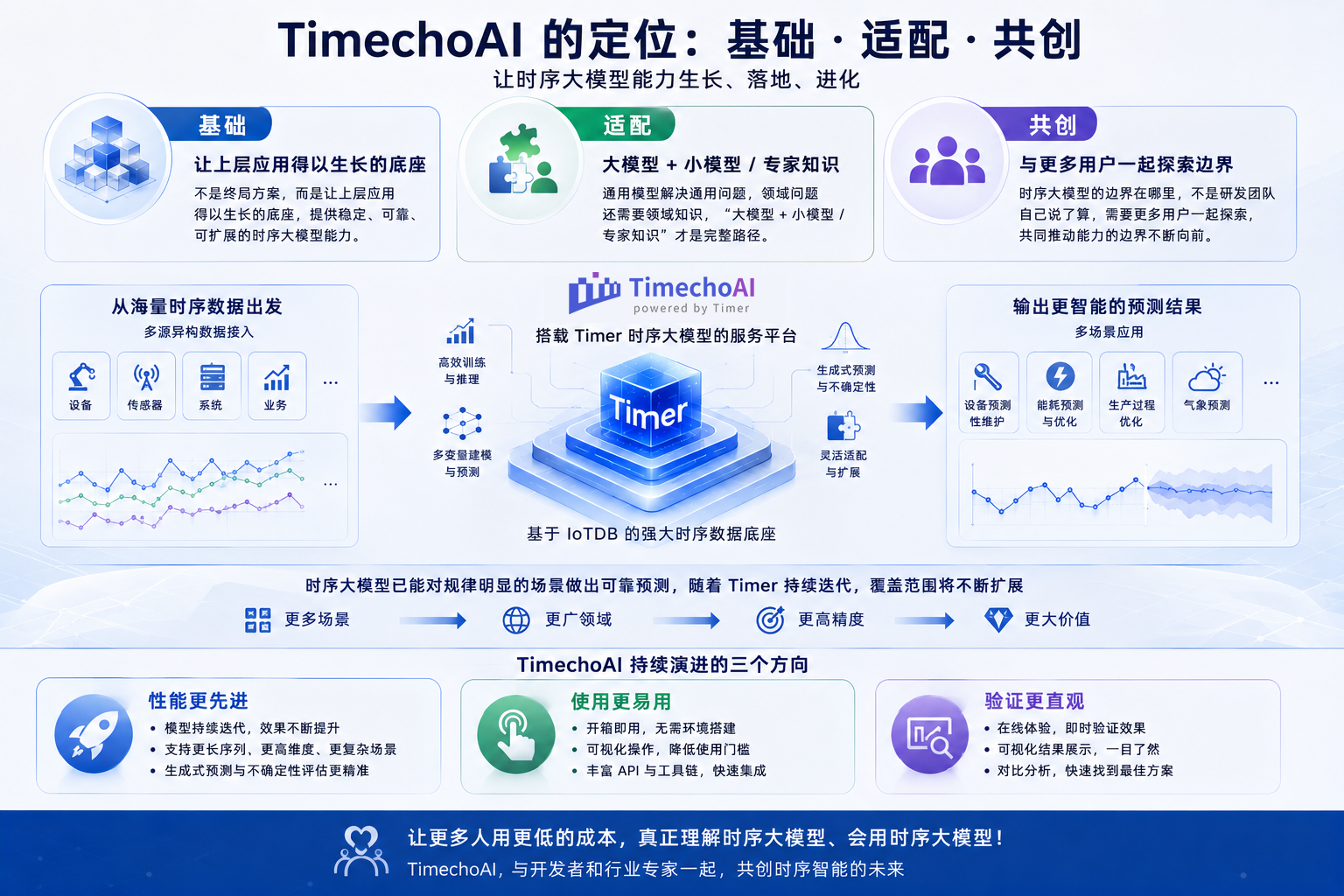
总的来说,TimechoAI 的定位可以用三个词来概括:
基础:它不是终局方案,而是让上层应用得以生长的底座;
适配:通用模型解决通用问题,领域问题还需要领域知识,“大模型+小模型/专家知识”才是完整路径;
共创:序大模型的边界在哪里,不是研发团队自己说了算,需要更多用户一起探索。
现在,时序大模型已经能够对那些规律相对明显的直观场景做出较为可靠的预测。随着 Timer 的持续迭代,这个范围会不断扩展——从更多场景到更广泛的领域,一步步往前走。
接下来,TimechoAI 会围绕三个方向持续演进:性能更先进、使用更易用、验证更直观。我们希望让更多人用更低的成本,真正理解时序大模型、会用时序大模型。
数据存下来只是第一步。能把“过去”变成对“未来”的判断,才是真正的价值。
如果你也在面对时序数据“存而不用”的困惑,不妨去 ai.timecho.com 体验一下 TimechoAI。也许,那个基础可用的起点,就能帮你解决一个真实的问题。
更多内容推荐:
• 试用时序大模型云平台 TimechoAI
• 咨询时序大模型 Timer


