

本文源于:长安汽车智能化研究院
1. 业务场景介绍
公司简介
长安汽车,全称“重庆长安汽车股份有限公司”,是中国领先的汽车制造商之一,以广泛的产品线和创新技术而闻名。长安汽车不仅提供多种乘用车和商用车,还在智能网联汽车技术方面处于行业前沿,特别是在车联网平台的开发上。
车联网平台是长安汽车智能化战略的核心组成部分,该平台利用云计算、大数据、物联网和人工智能等技术,实现车辆与外部环境、其他车辆以及交通基础设施的互联互通。其核心平台 VOT 实现了千万级车辆实时在线、毫秒级通讯互联、完整的生态接入能力,并在此基础上提供实时数据采集、海量数据分析计算、实时预警车辆故障、保证车辆安全驾驶等功能,显著提升了用户的用车体验。
业务全景介绍
长安汽车智能化研究院承担了长安汽车智能化转型的重要角色,其车联网平台是公司智能化战略的重要组成部分,该平台借助大数据、云计算和人工智能等先进的数字技术,为消费者提供更安全、更舒适、更便捷的智能驾驶体验。主要包含的业务如下:
车联网核心平台 VOT:公司基于超大规模云原生架构下设计的车云核心服务,业务涵盖车辆远控、车况、事件通讯、服务编排、规则引擎等核心能力,通过物联网时序数据库 IoTDB 实现了千万级的车辆稳定接入、千万点每秒的数据并发处理以及超高的终端接入兼容性,是长安汽车所有车辆的云上大脑。
数据分析平台:公司基于 Apache Doris 升级了车联网数据分析平台,支持单日百亿级别数据的实时处理,并能实现十亿级别数据查询的秒级响应。该平台为长安汽车在提升用户用车体验、实时预警车辆故障、保证车辆安全驾驶等方面带来显著成果。
云器 Lakehouse 大数据平台:公司建设了基于云器 Lakehouse 的车联网大数据平台,面对超大规模数据量和业务的飞速发展,解决了成本高、用数难、运维烦等挑战。
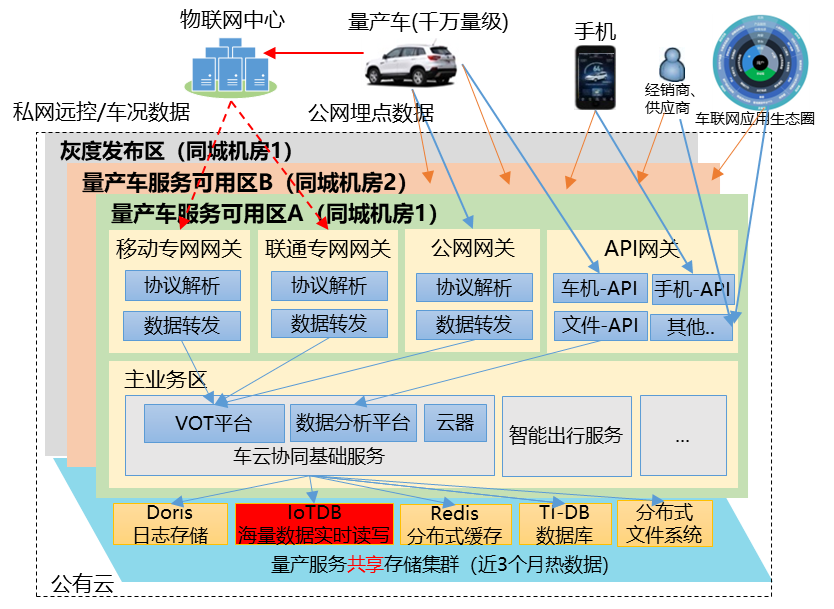
长安汽车车联网业务整体架构图
平台时序数据管理能力建设
伴随着长安汽车旗下主要品牌(包括阿维塔、深蓝、启源等)的迅猛扩张以及智能网联汽车的数量呈指数级增长,车联网平台迎来了前所未有的压力。这种增长不仅给车联网平台带来了数据并发处理的挑战,也导致了平台海量数据处理成本的上升、效率的下降以及实时和历史数据存储费用的增加。
具体来看,车况信息作为众多车辆数据中的核心数据,海量的连接数量导致数据上报量也呈指数级增长。在当前的日活跃用户数下,每日实时上行的车况数据量已达到惊人的 200 T。
IoTDB 作为长安汽车车联网平台的核心数据存储引擎,扮演着至关重要的角色,不仅支持高并发的读写操作,还负责历史数据的长期存储。
2. 业务需求痛点
海量并发写入性能低
当前,在长安汽车闲时活跃用户量约 200 万的情况下,车联网平台实时上传的车况数据并发量已经稳定在数十万级别。由于不同车型导致的车况模板信息需求差异,动态存储成为了一个迫切需要解决的问题。
同时,相比传统汽车,智能汽车领域单个智能汽车的数据交互量呈现出数十倍的增长。以长安汽车近千万的日活跃用户量计算,长安汽车车联网平台长期承受着每秒超过 50 万次的数据传输压力。如此海量数据压力下,传统数据库面临着服务器资源高负载和写入性能的双重挑战。
存储与查询灵活性差
在面对这些挑战时,长安汽车现有车况数据存储引擎 HBase 表现出明显的劣势:原数据存储引擎数据模型基于行键、列族和时间戳,所有的数据访问模式都必须围绕该模型设计。若数据访问模式与 HBase 的数据模型不匹配,可能会导致查询效率降低。
而且,HBase 不支持像传统关系型数据库般的联结操作和复杂的事务处理。因此在需要进行复杂查询的应用场景中,HBase 可能并不是最佳选择。
此外,HBase 的查询通常涉及全表扫描,这在大型表中会消耗大量资源和时间。尽管这一问题可以通过使用过滤器来减少扫描的数据量,但仍然是一个需要考虑的性能瓶颈。
历史数据存储成本高
HBase 作为一种基于列的存储解决方案,虽然适合存储稀疏数据,但在处理高频更新和小批量随机读写操作时效率并不理想。同时,尽管 HBase 支持 GZIP、Snappy 等多种压缩算法以有效减少存储空间占用,但这些操作可能会增加 CPU 使用率,并降低数据的读写性能,从而无法满足大数据量下数据实时处理的需求。
中心计算资源紧张
长安汽车原有的车况数据架构基于纯云端的 HBase 存储,强烈依赖于 Hadoop 生态计算架构,这种计算架构并非轻量级,其所有计算成本都紧密围绕着建立的生态系统。这种依赖性,对云核心的负载造成了极大压力。
此外,HBase 基于单个主节点的集群架构,在面临故障时虽然可以继续连接其他区域(region),但主节点的恢复时间较长,从而导致计算链路性能下降,这也意味着所有计算压力都集中在云端,单就 HBase 而言其复杂的架构难以在边缘节点上部署。
3. 选型 IoTDB 原因
支持动态模板的海量并发处理能力
IoTDB 基于时间序列的存储结构优化与 HBase 针对基于时间序列的固定模板不同,IoTDB 的元数据模板支持动态的增删改查,并在此基础上实现了物理量元数据共享,优化了存储及使用成本。
IoTDB 也支持高并发连接,单台服务器可以处理数万次并发连接/秒,具备高写入吞吐的特点;单核处理写入请求可以达到数万次/秒,单台服务器的写入性能可以达到数千万点/秒;在集群环境下,写入性能可以线性扩展,集群的写入性能可达数亿点/秒。
实时读写与高效压缩兼顾
IoTDB 使用更高效的时间序列数据压缩技术,如 Gorilla 编码,可以在保持较高压缩比的同时,实现快速的数据读写,既降低了历史车况的存储压力,又满足了车联网下车况数据的实时使用场景。
端云计算架构
IoTDB 的轻量级架构适用于边缘设备,具有高效的数据管理和存储能力。在边缘节点,IoTDB 支持低延迟的查询,使实时数据分析成为可能;终端层的数据通过边缘层的 IoTDB 进行实时采集、处理和存储,并进行一系列的分析任务后,后续数据可上传到云端 IoTDB,满足车联网领域中大规模数据存储、高速数据摄入和复杂数据分析的需求。
边缘 IoTDB 结合 IoTDB 云版本,可以支持在不同环境中管理时间序列数据,提升数据质量,降低云计算的成本。
4. IoTDB 时序数据管理流程简述
长安汽车车联网平台原有方案采取较为简单的车况上报,经由网关转发后实时车况存储在 Redis,历史车况存储在 HBase。
基于 IoTDB 的新方案采用端云协作计算,部分车况数据在终端进行数据整合,也可根据特定需求(如国家采集标准的数据格式转换、周期数据整合等)自行在终端进行简单计算、短期存储。按照配置上传云端,通过规则引擎进行分发后,基于 IoTDB 实时性高的特征,同时进行实时数据推送、实时数据 Redis 存储、历史数据 IoTDB 落库并提供查询接口做数据统一。
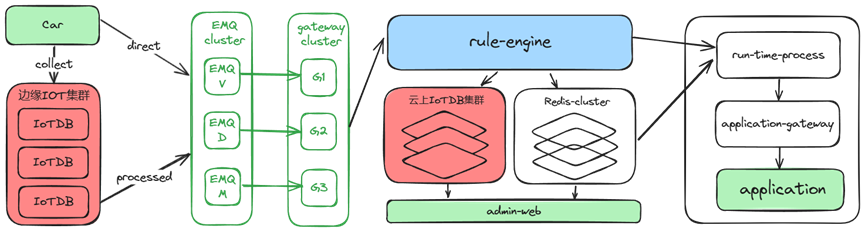
车联网平台 VOT 完整架构图
5. 应用效果
车况上报百万并发写入
面向长安汽车百万级在线车辆实时车况数据上报、实时存储查询场景,IoTDB 每秒写入能力达到 800w+,并且支持水平扩展承载更高的压力。
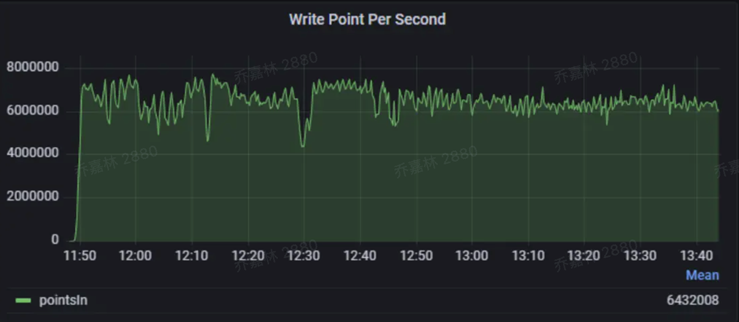
当前,长安汽车 VOT 平台实时接入车辆数量达到 200 万辆,每日产生的数据量高达 1500 亿条记录。在这种规模下,依托 IoTDB 打造的新系统能够保持写入延迟在毫秒级别,数据实现快速可靠写入。
平台单日产生的数据量累计约 200 T,在经过 IoTDB 高效实时存储处理后,数据量得以大幅压缩,最终存储量约为 30T,实现了约 10 倍的数据压缩比例。在当前的数据存量(覆盖近 90 天的时间范围)下,IoTDB 在大数据处理和存储方面的卓越性能得以体现。
历史车况高效查询
针对目前长安汽车的万亿级车况数据,IoTDB 将查询延迟控制在 50 ms 内,完全满足所需性能。
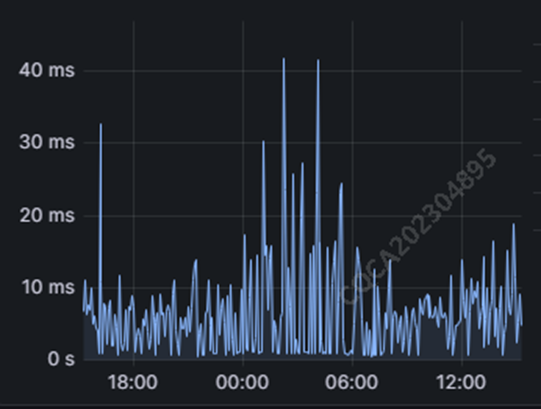
此外,VOT 平台的数据处理架构设计充分考虑到高并发和大数据量的挑战,并基于 IoTDB 及其完善的生态接入能力,通过采用先进的数据索引和查询优化技术,从而支持快速的数据检索和分析。
不仅如此,平台还集成了机器学习算法,用于智能预测和维护车辆状态,进一步提升数据处理的效率和准确性。这些技术的应用不仅提高数据处理的速度、降低运维成本,也为用户提供了更加稳定和可靠的服务体验。
平台效果展示
启源 App 首页
车联网 VOT 服务管理
更多内容推荐:
• 了解更多 IoTDB 应用案例


