

当工业物联网传感器、能源电网、气象监测系统每时每刻产生海量时序数据,如何打破“存数易、用数难”的困局,让沉睡的数据转化为驱动业务的核心动力?
在 AI 能力持续升级的浪潮中,工业场景对时序数据的需求也在不断提升。企业希望做的,不只是数据存储、查询和展示,而是进一步实现异常识别、趋势预测、辅助决策等更高层次的智能分析,真正让数据服务业务。
时序数据库 IoTDB 用“数据库原生智能”的架构理念,为工业智能带来了独特解法:以高性能时序数据底座为基础,将 AI 能力深度融入时序数据管理体系中,让数据存储与智能分析在同一体系中完成,推动时序数据从“可采、可存、可查”走向“可分析、可预测、可决策”。
接下来我们将展开讲述 IoTDB 的时序智能化分析能力,以及在新能源电价预测这一场景的具体应用。
01 从“采数”到“用数”:IoTDB 释放时序数据全链路价值
时序数据是按时间顺序索引的监测数据,以时间为横轴、设备传感器采集值为纵轴,呈现出类似心电图的波动特征,直观反映物理实体的实时运行状态。
小到工业传感器、穿戴设备,大到服务器集群、能源电网、气象监测系统,各类系统每时每刻都在产生海量时序数据,这些数据是工业数字化、智能化升级的核心基础。
时序数据的价值,从来不止于 “记录”,更在于“利用”。它可以支撑系统从监控与诊断出发,实时追踪系统状态、快速定位问题;再到洞察与归因,分析历史趋势、厘清问题根源;进而实现预测与规划,基于历史模式预判未来走势、支撑科学决策;最终落地优化与控制,根据预测结果自动调整系统参数,实现动态自适应。
这条从“采数”到“用数”的全链路,是时序数据真正赋能业务的核心路径,也是 IoTDB 始终聚焦的价值方向。
作为针对工业场景打造的时序数据库,IoTDB 以自研时序文件格式 TsFile 为核心,搭建了高性能时序数据底座,承载实时数据传输、检测与定位等底层数据存储与管理需求,解决海量时序数据的高效写入、存储、查询难题。
在此基础上,IoTDB 搭配时序智能底座 AINode,内置 Timer 等前沿时序大模型能力,深度支撑时序预测、异常分析、数据补全等上层智能分析需求,真正实现 “存数-管数-用数” 一站式闭环,让时序数据从 “沉睡的资产” 转化为可落地的业务价值。

02 IoTDB AI 核心能力:适配三类典型智能分析场景
IoTDB 依托 AINode 与 Timer 等时序大模型,面向工业领域常见的智能分析场景需求,提供一站式 AI 能力支撑,使用户无需复杂开发即可快速落地。
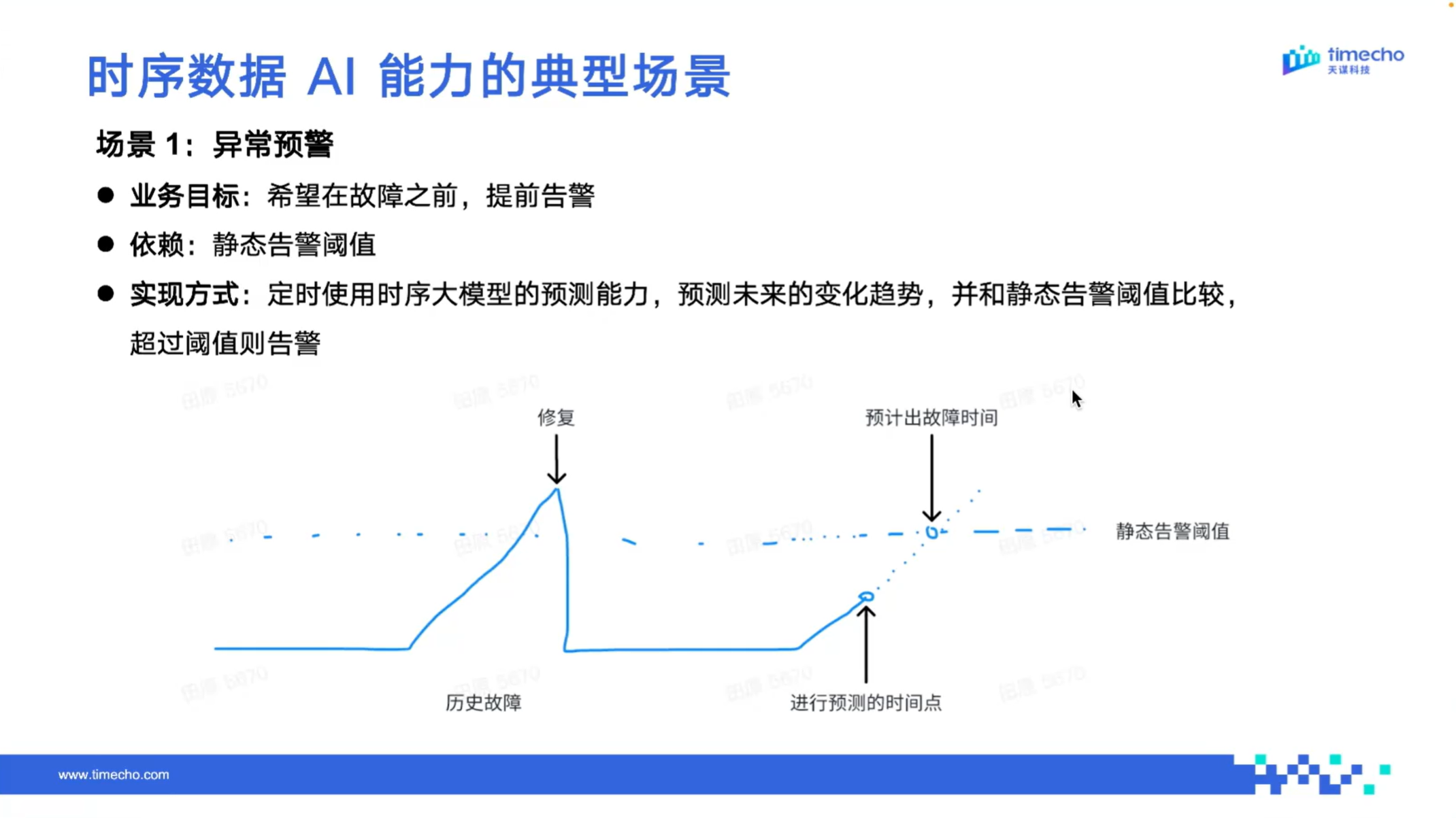
(1) 异常预警:故障前置预判,主动防范风险
工业场景中,大多系统已能实现异常数据出现后的实时告警,用于排查已发生的设备问题。而基于 IoTDB 的 AI 智能化能力,用户能进一步实现故障发生前的提前预判,在设备尚未出现明显异常时,就能识别潜在风险并发出预警,为提前处置、主动运维留出充足时间。
通过设定静态告警阈值,IoTDB 可定时调用时序大模型,对未来数据变化趋势进行预测,并可利用分类模型对数据进行二分类判断,快速区分正常与异常数据。结合故障预判时间,系统能够提前发出告警,帮助运维从“被动响应”走向“主动防范”。
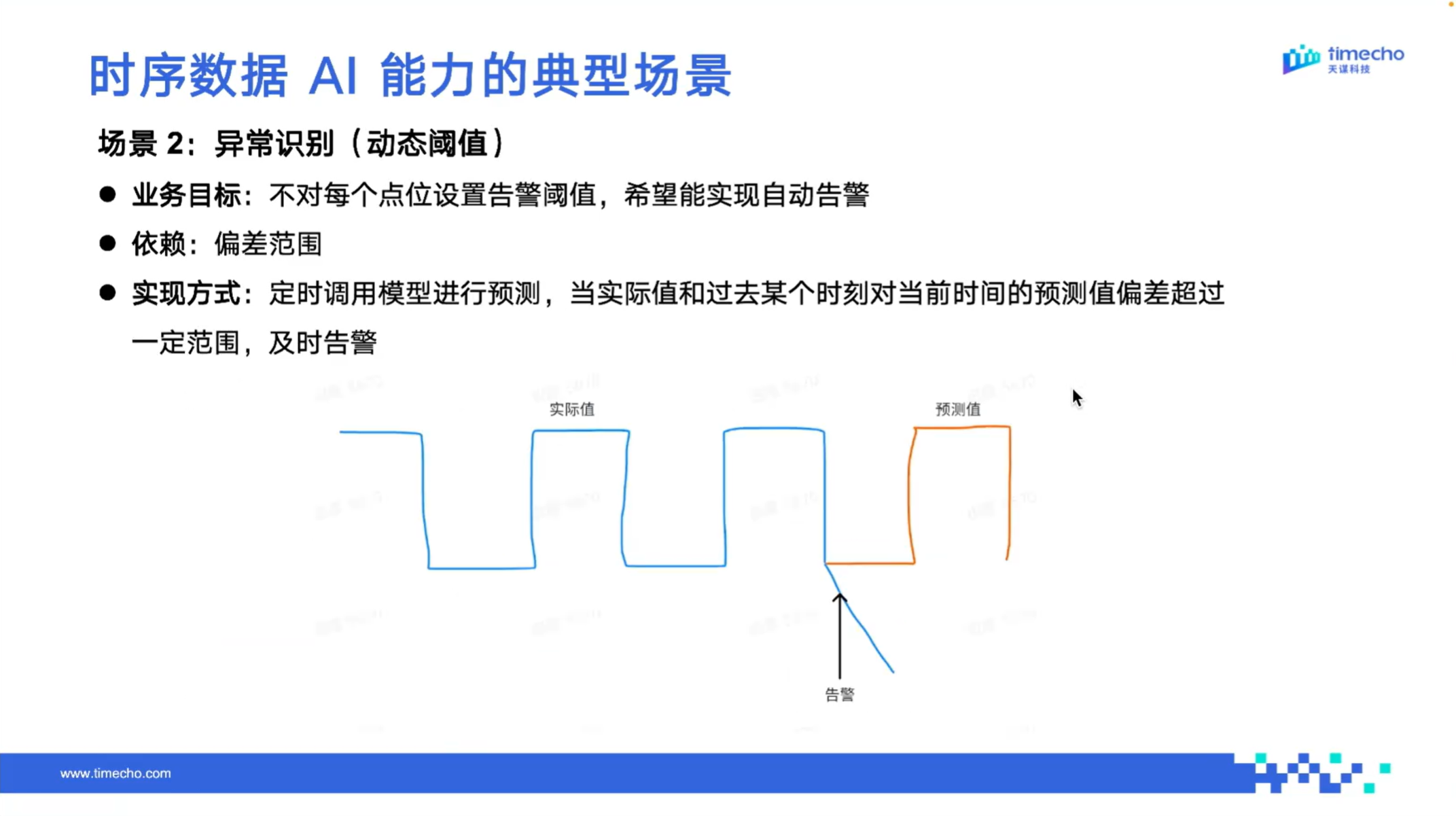
(2) 异常识别:无阈值配置,自适应智能监测
除静态阈值的异常预警外,IoTDB 还支持动态阈值的异常识别,无需为每个监测点位单独配置告警阈值。
时序数据可视作设备连续的状态信号,用户可以利用 IoTDB 内置的时序大模型学习历史正常运行规律,基于当前数据预测下一时刻的合理数值。当实际采集值与预测正常值出现明显偏离时,系统自动判定为异常并触发告警,实现无阈值、自适应的智能监测。
两种异常预判与告警方式相互补充,可精准识别设备潜在风险,有效降低设备非计划停机风险。
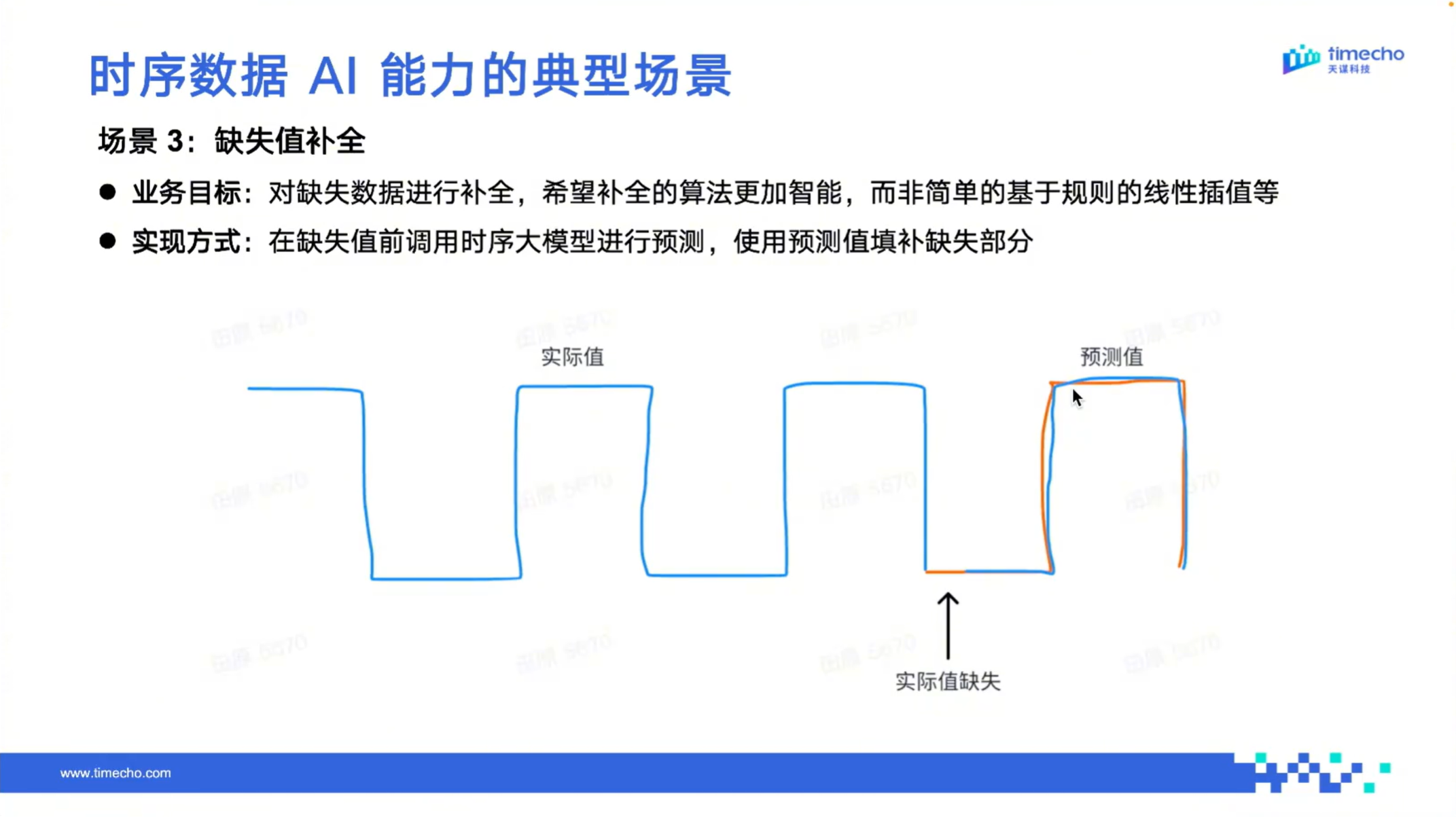
(3) 缺失值补全:智能保障数据链路完整
在实际生产环境中,传感器故障、网络波动等情况常会造成设备数据缺失,常规填充方式包括直接使用前序数值填充、采用固定常量填充,或基于前后数据进行线性插值等方法,但可能难以贴合真实数据趋势,容易对后续分析带来干扰。
依托 IoTDB 的 AI 时序分析能力,缺失值填补可实现更智能、更精准的处理:将缺失段前后的有效时序数据作为输入,通过时序大模型直接预测还原中间缺失片段;也可对前后数据进行编码后输入模型,自动生成贴合实际运行趋势的填补值。
这种智能缺失值填补方式,能够最大程度保障数据集的连续性与真实性,为后续数据分析、趋势预测等场景提供高质量的数据基础。
03 实战案例:IoTDB 破解新能源电价预测难题
如果说异常预警、异常识别、缺失值补全展示的是 IoTDB 时序智能能力的通用价值,那么在新能源电价预测场景中,IoTDB 更进一步体现了其面向复杂业务问题的适配能力。
新能源电价受时间、气象、能源供给等多重因素耦合影响,波动规律复杂,并且可能出现极端电价,需提前判断极高电价的出现时间。
某新能源企业借助 IoTDB,构建极值分类与多变量协同的电价预测方案,通过场景化分类优化模型,提升电价预测实用性与精准度,为业务落地提供可靠支撑。
(1) 多变量耦合下,电价预测为什么难
某能源公司的新能源电价受多重因素影响,波动规律复杂、关联性强。模型在预测未来电价时,需综合接入约 100 个协变量,主要可分为三类:
时间协变量:如工作日与节假日、白天与夜间、高峰与低谷时段等,直接影响用电负荷变化;
气象协变量:如风速、日照时长、光照强度、温度、降水量及云层覆盖度等,直接决定风光新能源的实际出力;
能源协变量:如光伏与风电发电量、储能系统充放电效率、能源转化效率等供给侧指标,也会显著作用于市场电价。

(2) 真正的业务目标,不只是预测电价曲线
基于上述多维变量,叠加历史电价数据,便可构建多变量输入的电价预测模型。
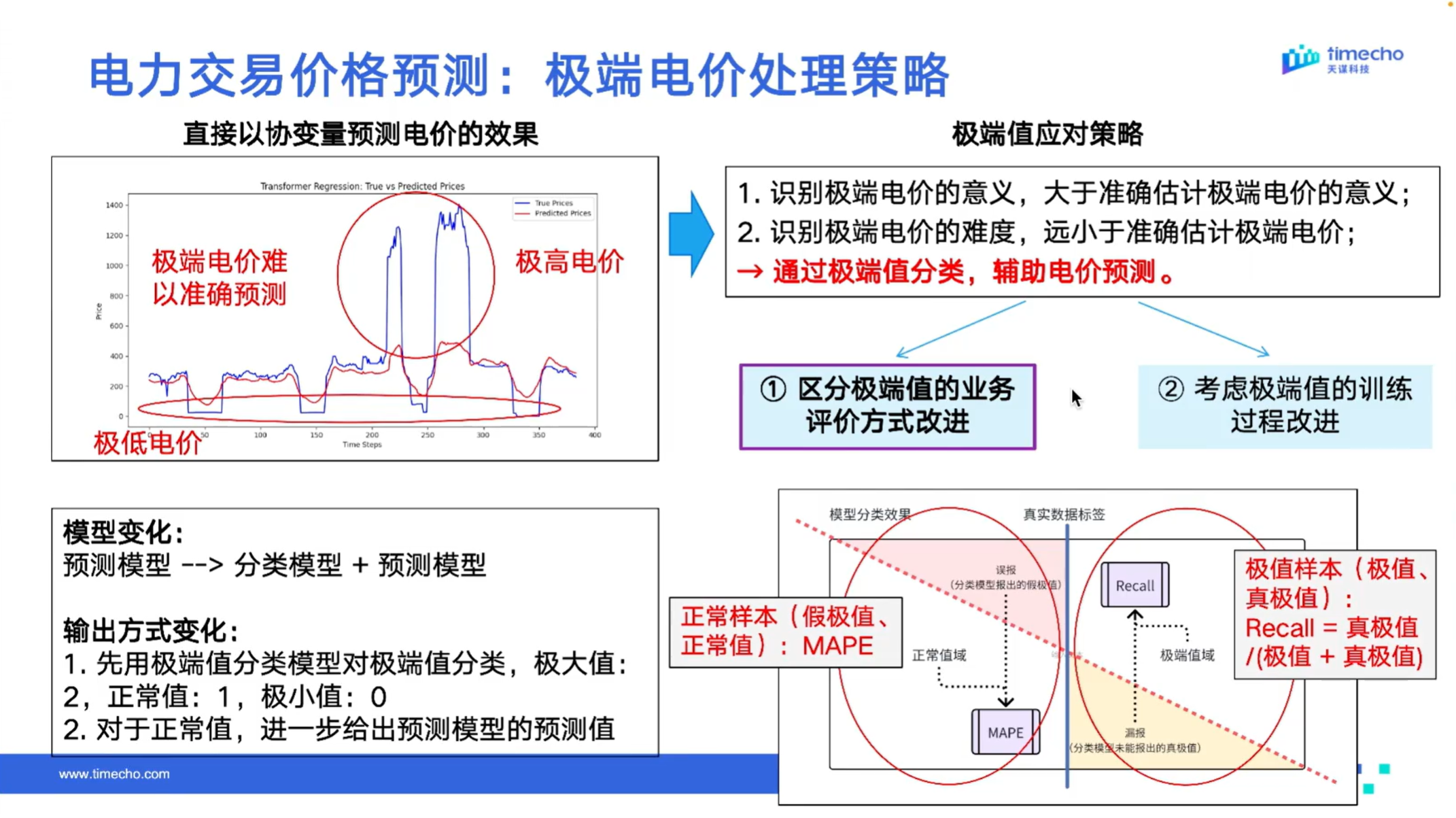
在常规场景下,模型能够较为精准地拟合电价走势。但真正影响业务决策的,往往不是常态波动,而是极高电价等极端场景。此类数据通常具有明显的非稳态特征,不仅增加了预测难度,也会干扰模型对常规电价区间的拟合效果。
结合客户实际需求可以发现,用户最关心的并不是“每一个时刻的电价数值都尽可能精确”,而是能否提前判断某一时段是否会出现极高电价,以此支撑电力交易决策、市场风险防控与储能充放电调度。
这意味着,模型设计不能只追求统一意义上的预测精度,还需要围绕真实业务目标进行针对性优化。
(3) IoTDB 的创新方案:极端值识别与常规值预测分场景处理
针对上述业务需求,IoTDB 将电价预测问题拆分为两类场景,并采用差异化处理策略。
第一类场景为极端电价识别:可基于 IoTDB 搭建分类模型,核心用于判断某一时间段是否会出现极高电价,若模型预判该时段不会出现极端电价,则采用前期训练的常规预测模型进行电价预测。此类场景下,预测模型可实现精准拟合,预测曲线与实际电价走势高度匹配。
第二类场景为极端电价提示:若分类模型预判该时段会出现极高电价,结合用户核心诉求,系统无需强行给出一个高精度的极端数值预测结果,而只需明确提示该时段存在显著风险,即可满足用户在交易决策、风险控制与调度安排中的核心诉求。
在 IoTDB 分类模型的训练阶段,可将极高电价相关数据从模型训练集中剔除,也无需将此类极端数据作为输入,从而避免极端非稳态数据对常规稳态数据预测结果的干扰,进一步保障常规场景下的预测精度。
这种“极端值与常规值区分处理”的优化方式,也为时序预测模型的落地提供了重要启示:在设计和应用时序预测模型时,需要结合实际业务场景优化模型设计,重点贴合用户的核心需求,而非单纯追求数值预测的精度,这样才能让模型更好地服务于实际业务,发挥其应用价值。
(4) 落地效果:预测精度与业务可用性同步提升
在未引入极值优化处理方案前,模型零样本预测的 MAPE 值(平均绝对百分比误差,值越小表示预测越准确)在 0.24 以上。
引入极值区分处理方案后,模型零样本预测的 MAPE 值降至 0.147;若进一步融入多变量适配优化,模型零样本预测的 MAPE 值可进一步降至 0.121,预测精度得到大幅提升。
这一结果验证了 IoTDB 电价预测方案在新能源场景中的可行性与实用性,也为用户开展电价运营决策、风险防控与储能调度提供了更可靠的支撑。

04 写在最后
IoTDB 智能化能力的核心优势,在于时序数据底座与智能分析底座深度融合。数据无需频繁出库,即可在统一体系内完成模型推理与模型微调,从而降低系统复杂度与应用成本,提升时序智能能力的落地效率。
IoTDB 目前已实现异常预警、异常识别、缺失值补全等智能分析核心场景适配。电价预测的定制化场景落地,更能证明 IoTDB 集成的预测功能在能源领域的适配性与实用性。
更重要的是,这一案例也说明,工业时序智能的关键,不只是把模型接入数据库,更在于围绕真实业务目标去设计分析流程、组织数据方式与优化模型路径。只有当数据底座、模型能力与场景需求真正协同起来,时序 AI 才能从“可用”走向“好用”,进一步释放产业价值。
未来,随着时序数据与 AI 技术的深度融合,IoTDB 将持续增强 AI 智能分析能力,优化模型适配性,拓展更多行业应用场景,让时序智能赋能千行百业实现数字化、智能化升级。
更多内容推荐:
• 下载开源时序数据库 IoTDB
• 咨询企业时序数据库 TimechoDB


