

在工业实时告警、海量测点管理等高并发场景中,数据库性能往往决定着业务能否稳定运行。一次写入延迟的抖动,可能带来告警滞后;一次吞吐能力的不足,可能限制系统扩展规模。
性能问题往往不是“显性故障”,而是长期积累的隐性瓶颈。如何识别真正的性能短板?如何判断问题究竟在数据库本身,还是在上游链路?系统调优因此成为数据库工程中的关键能力。
本文将从调优难点出发,介绍时序数据库 IoTDB 构建的可观测性体系与监控模块,并结合典型案例,梳理系统调优的方法与实践思路。
01 系统调优为什么难
对于数据库这类基础软件而言,系统调优始终是技术团队面临的核心难题。系统调优在实现层面的复杂性主要体现在三个方面,同时在架构演进层面也伴随着长期性的挑战。因此,调优工作的开展必须前置规划,而不能依赖临时应对。
(1) 调优三大核心难点
快速找到瓶颈点难
系统运行存在木桶效应,服务器的硬件、软件各模块共同构成系统运行的链路,瓶颈点可能出现在任意一个或多个模块中。在复杂的运行链路里,想要快速定位核心瓶颈点,是调优工作的首要难题。
针对性调优难
实际业务中,硬件环境、业务负载千变万化,二者组合形成的业务场景侧重点也各有不同。数据库的通用参数无法适配所有场景,需要结合不同的环境与场景,制定适配的参数配置,这对调优的针对性提出了高要求。
可扩展调优难
具备专业调优能力的人员较少,易形成调优的单点瓶颈,且调优经验难以快速复制,缺乏可落地、可复制的调优方法论,导致多数技术人员难以轻松跨越高门槛。

在架构层面,调优工作还需要确定典型场景及对应的核心特征,规划现有架构的下一步演进方向,并在海量业务场景下,规划资源投入策略,确保调优的投入产出比最大化,同时兼顾工程实现与学术研究层面的问题,明确调优任务的优先级排序。

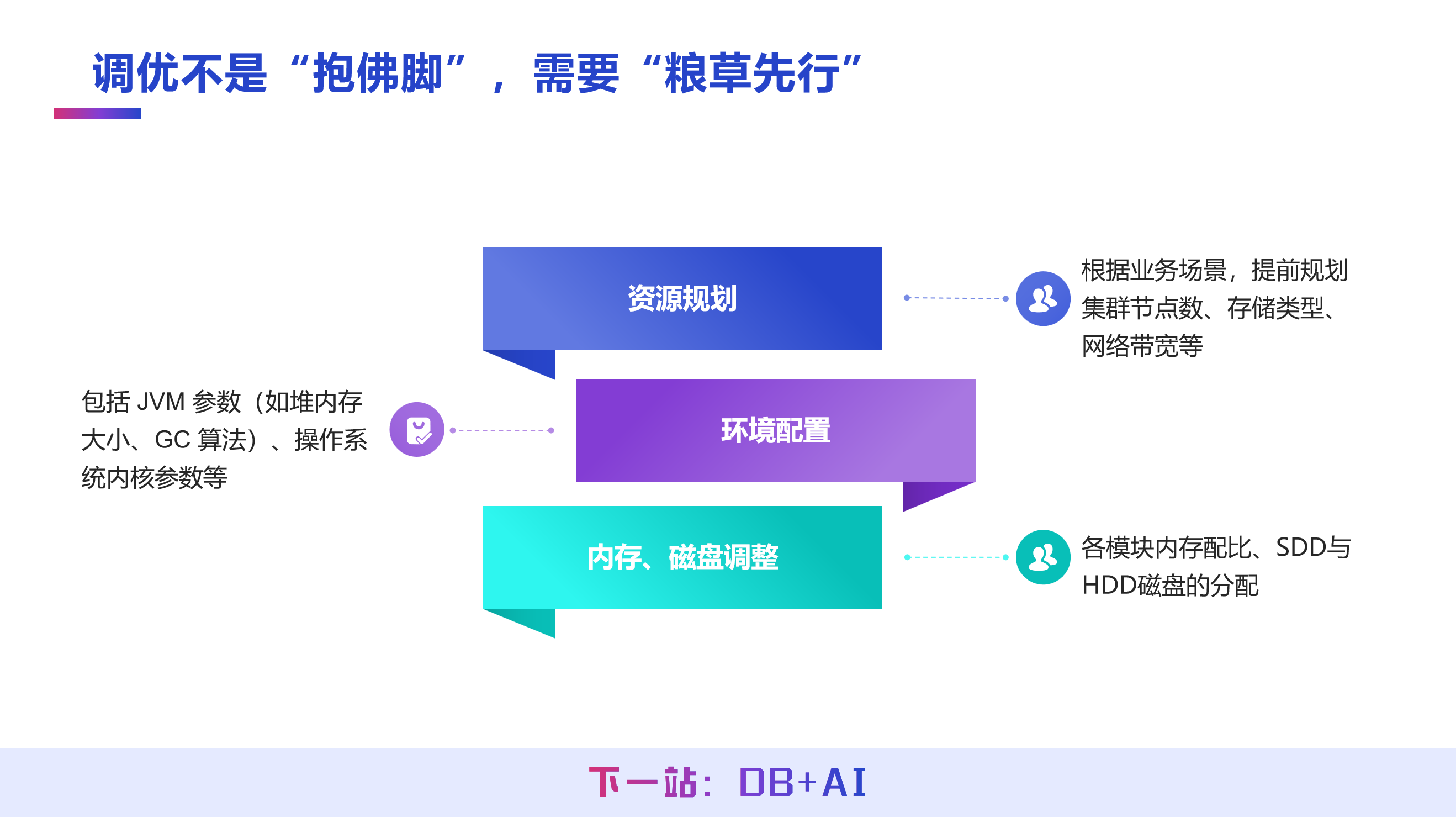
(2) 调优核心原则:粮草先行
调优并非临时抱佛脚的应急操作,而是需要结合业务场景提前规划,从三个维度做好前期设计:
资源规划
结合业务场景规划集群节点数,确定单机、双活或分布式的部署方式,同时匹配业务所需的存储类型、网络带宽等资源。
环境配置
IoTDB 基于 JVM 开发,需在数据库启动前,合理配置 JVM 参数(如堆内存大小、GC 算法);同时优化操作系统内核参数,为 IoTDB 运行搭建适配的基础环境。
内存、磁盘调整
IoTDB 包含存储引擎、查询引擎等多个模块,需规划各模块的合理内存配比;数据最终落地至磁盘,需根据业务需求分配固态硬盘与机械硬盘,做好磁盘搭配设计。
02 IoTDB 可观测性设计概览
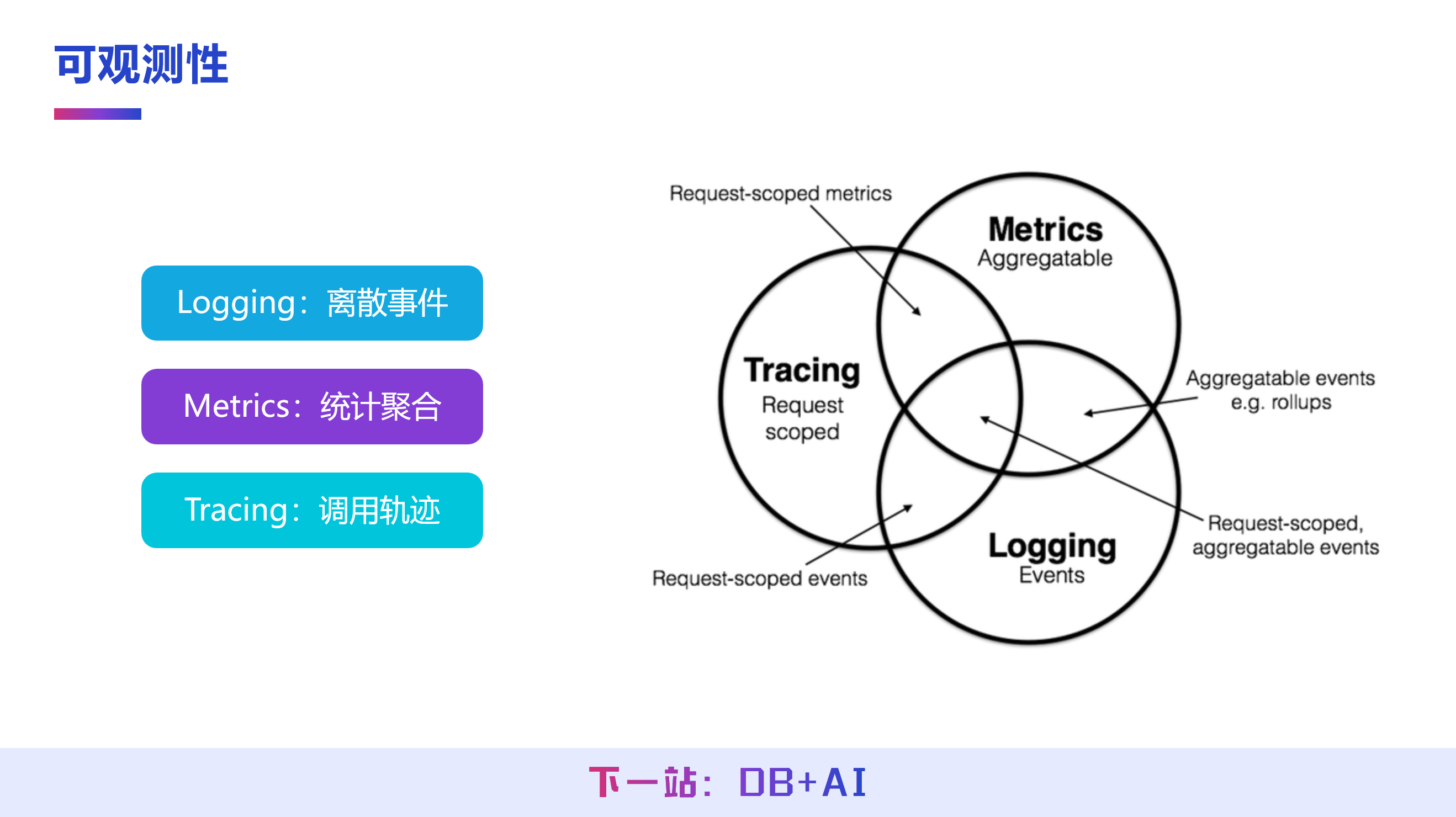
为解决调优难点,IoTDB 从分布式架构下的可观测性建设入手,将数据库从 “黑盒” 拆解为 “白盒”,通过 Logging、Metrics、Tracing 三个方向的建设,实现对系统内部运行状态的全方位感知,为调优工作提供数据支撑。
(1) IoTDB 可观测性三大核心方向
Logging(离散事件)
记录数据库内核中的所有离散事件,例如慢查询、模块运行异常等事件,为定位系统问题提供时间线索。
Metrics(统计聚合指标)
统计数据库运行过程中的聚合类指标,包括写入/查询的平均延迟、CPU 使用率、磁盘与内存的资源走势等,反映系统的整体运行状态。
Tracing(调用轨迹)
追踪数据库中的各类操作在分布式系统各节点的执行轨迹,例如查询操作、写入操作的节点执行流程,分析操作在各节点的运行情况。
(2) IoTDB 可观测性模块实现
Logging 模块
采用 Logback 框架,按模块与日志级别,结合 IoTDB 的 ConfigNode、DataNode 架构对日志进行拆分,同时对 DataNode 日志做进一步细分,如合并日志、慢查询日志等,便于从日志中提取有效信息。

Metrics 模块
算法库采用 Micrometer 与 DropWizard,存储端可选择 Prometheus 或 IoTDB,可视化层面通过 Grafana 展示所有监控指标,实现对系统运行指标的实时统计与可视化查看。

Tracing 模块
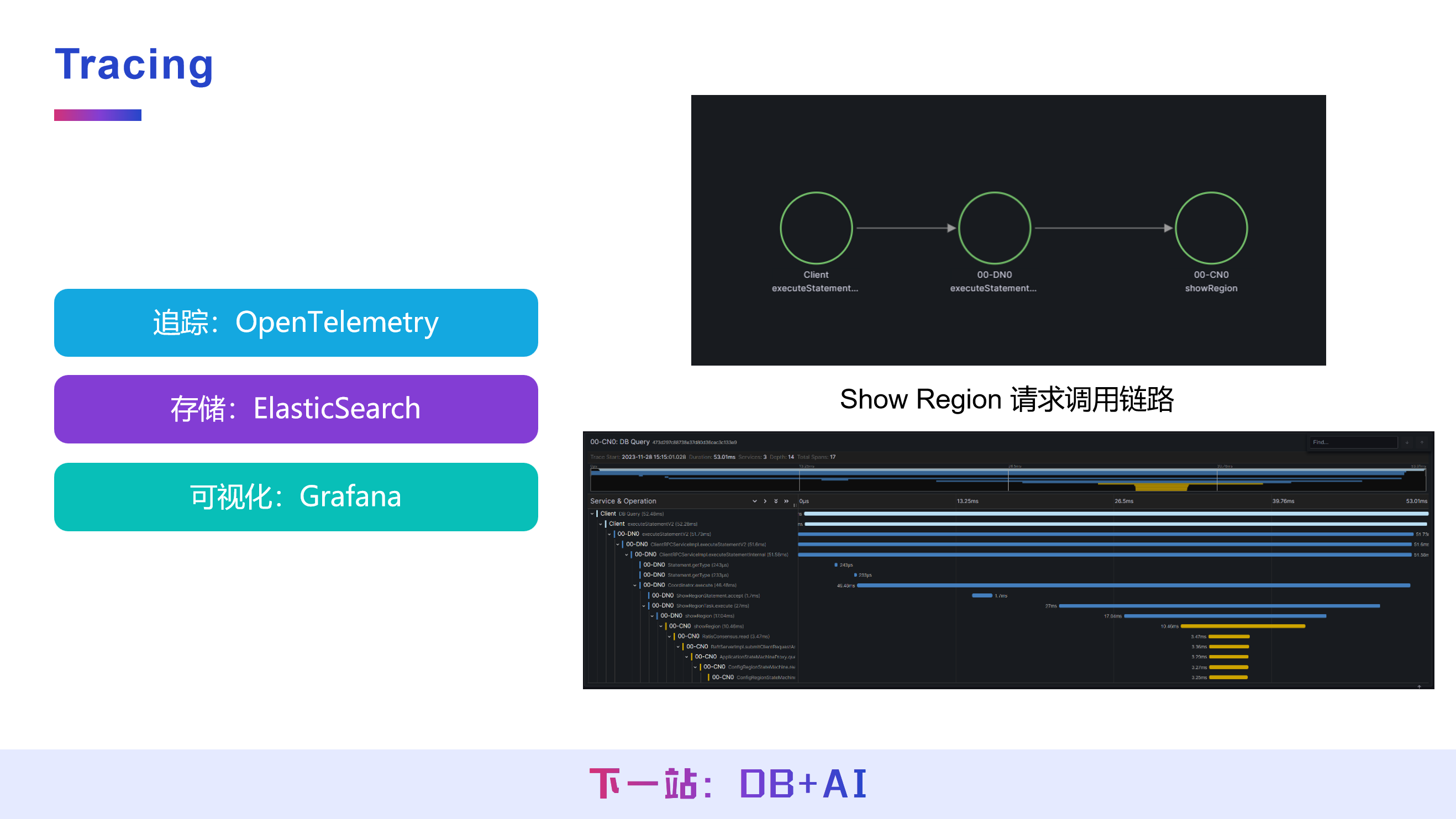
目前处于调研与实验阶段,技术栈采用 OpenTelemetry 实现操作追踪,存储端使用 ElasticSearch,可视化同样基于 Grafana,可实现对数据库操作请求调用链路的追踪与分析。
03 IoTDB 监控模块设计及性能
IoTDB 监控模块的建设以《性能之巅》中的性能分析思路为核心,从自顶向下的负载视角和自底向上的资源视角双维度设计,同时监控模块本身也实现了性能的持续演进,指标更丰富、对系统的性能影响更低。
(1) 双视角的监控设计思路
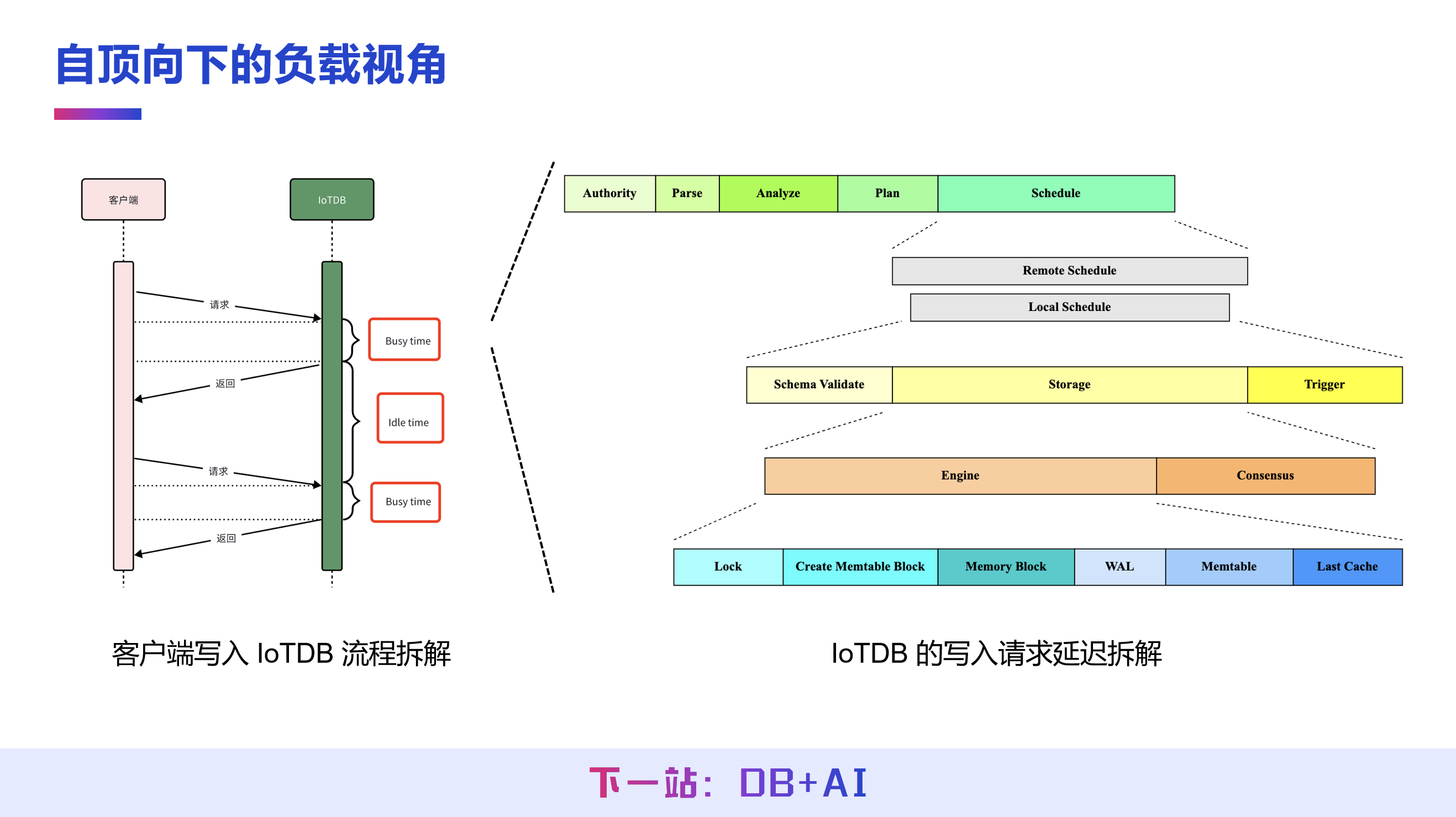
自顶向下的负载视角将复杂的业务模型简化为客户端与服务端的交互模型,通过监控判断服务端的繁忙/空闲状态:若服务端长期空闲,说明客户端负载不足,需从客户端侧调优;若服务端长期繁忙,则需拆解服务端的请求执行逻辑,定位瓶颈模块。
以 IoTDB 写入请求为例,可将执行流程拆解为鉴权、解析、执行计划生成、分布式计划调度、存储引擎处理等多个步骤,通过监控分析每个步骤的耗时、资源占用情况,精准定位负载瓶颈的核心模块。
自底向上的资源视角系统服务运行于操作系统之上,将直接影响系统性能的核心资源拆解为磁盘、网络、CPU、JVM 四类,分别分析各资源的负载情况,判断是否成为系统瓶颈:
磁盘监控:提供比 iostat 命令更丰富的磁盘 IO 数据;
网络监控:提供比 sar 命令更丰富的网络吞吐、连接数等数据;
CPU 监控:区分操作系统与进程的 CPU 占用,同时统计进程内部不同模块、线程池的 CPU 使用情况,分析线程池关键参数;
JVM 监控:观测堆内/堆外内存大小、不同状态的线程个数,监控 GC 执行情况,反映 JVM 运行状态。

(2) 监控模块的性能情况
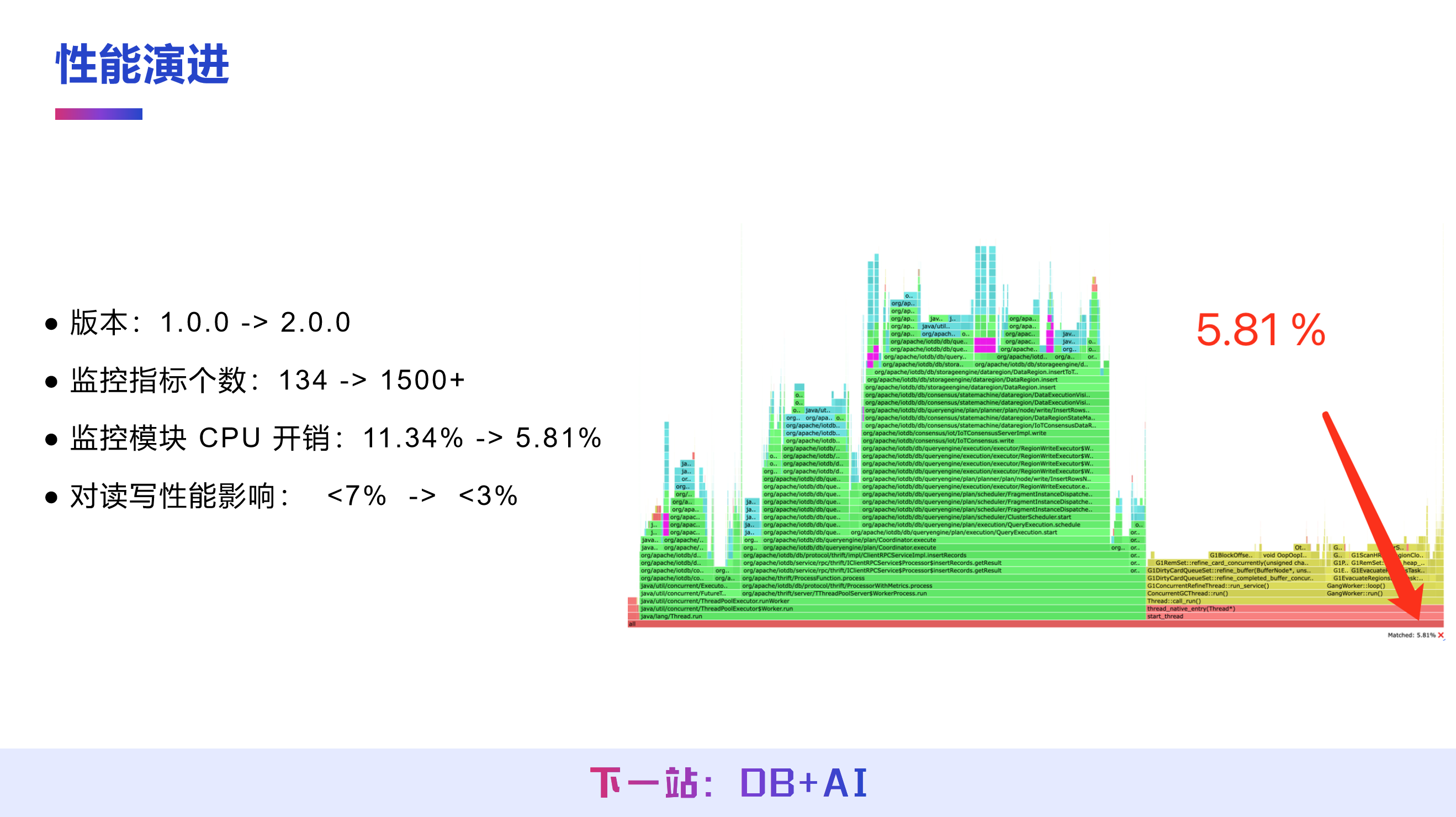
IoTDB 监控系统从 1.0 版本开始建设,目前已迭代至 2.0 版本,实现了指标丰富化与性能轻量化的双重提升:
监控指标数量从最初的 134 个增加至 1500+ 个,覆盖系统运行全维度;
监控模块的 CPU 开销从 11.34% 降至 5.81%,对 IoTDB 读写性能的影响从低于 7% 降至低于 3%。
目前企业客户部署 IoTDB 时,建议开启监控指标,便于快速定位系统性能瓶颈。
04 IoTDB 监控面板一览
基于上述双视角的设计思路,IoTDB 打造了四个维度的监控面板,各面板聚焦不同核心指标,为调优工作提供全方位的精准监控数据。
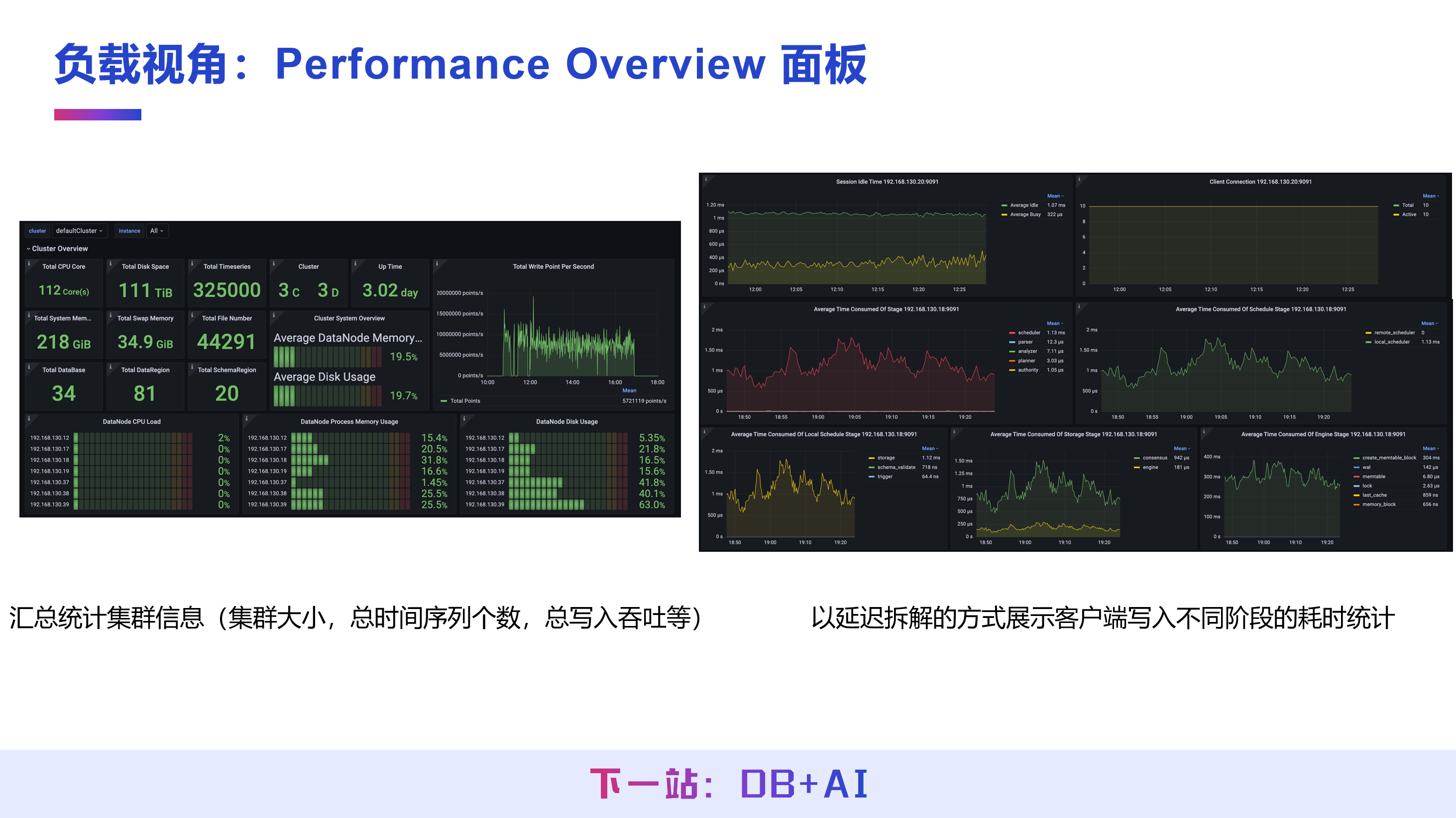
(1) Performance Overview 面板
用于统计集群的整体运行信息,包括集群总存储大小、管理时间序列个数、写入吞吐、查询吞吐等;同时以延迟拆解的方式,展示客户端写入、查询等操作在不同阶段、不同接口的耗时。通过该面板可快速判断集群的整体健康程度与运行状态,且无需在每个节点部署监控,单节点部署即可观测集群所有节点的详细信息。
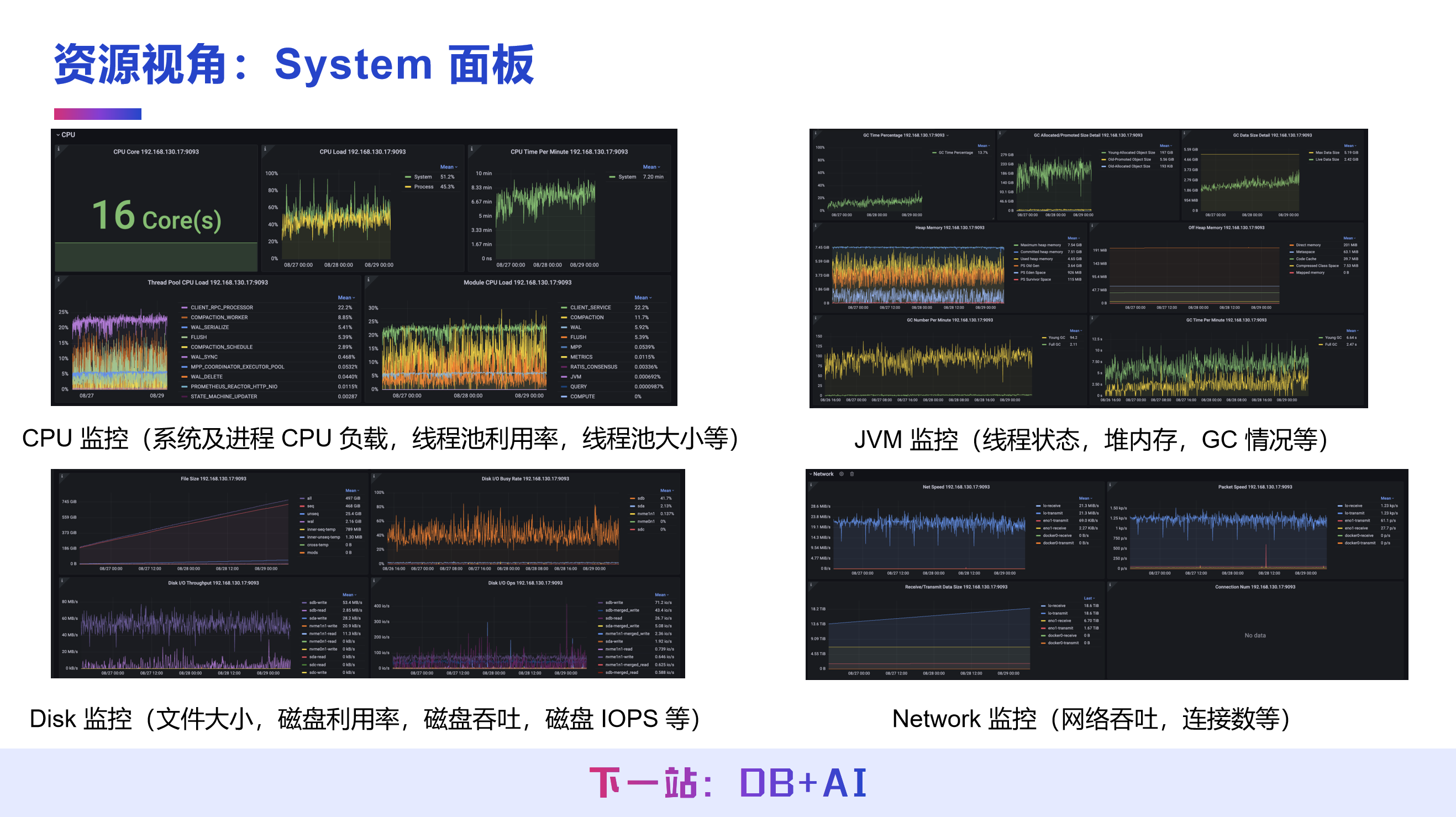
(2) System 面板
基于自底向上的资源分析视角建设,拆解为 CPU、JVM、Disk、Network 四大监控模块,全方位展示系统资源的使用状态:
CPU 监控:统计系统及进程的 CPU 负载、线程池利用率与大小、内核各模块的 CPU 占用情况;
JVM 监控:展示线程状态、堆内存使用、GC 执行次数与耗时等;
Disk 监控:统计文件大小、磁盘利用率、磁盘吞吐、磁盘 IOPS 等磁盘核心指标;
Network 监控:展示网络吞吐、网络连接数等网络运行数据。
(3) ConfigNode 面板
ConfigNode 作为 IoTDB 集群的管理者,该面板主要统计集群的基础配置信息,包括数据库个数、数据分区个数及状态、节点运行状态等,同时展示元数据分区与分区 Leader 的分布情况,直观反映集群的配置与分区管理状态。

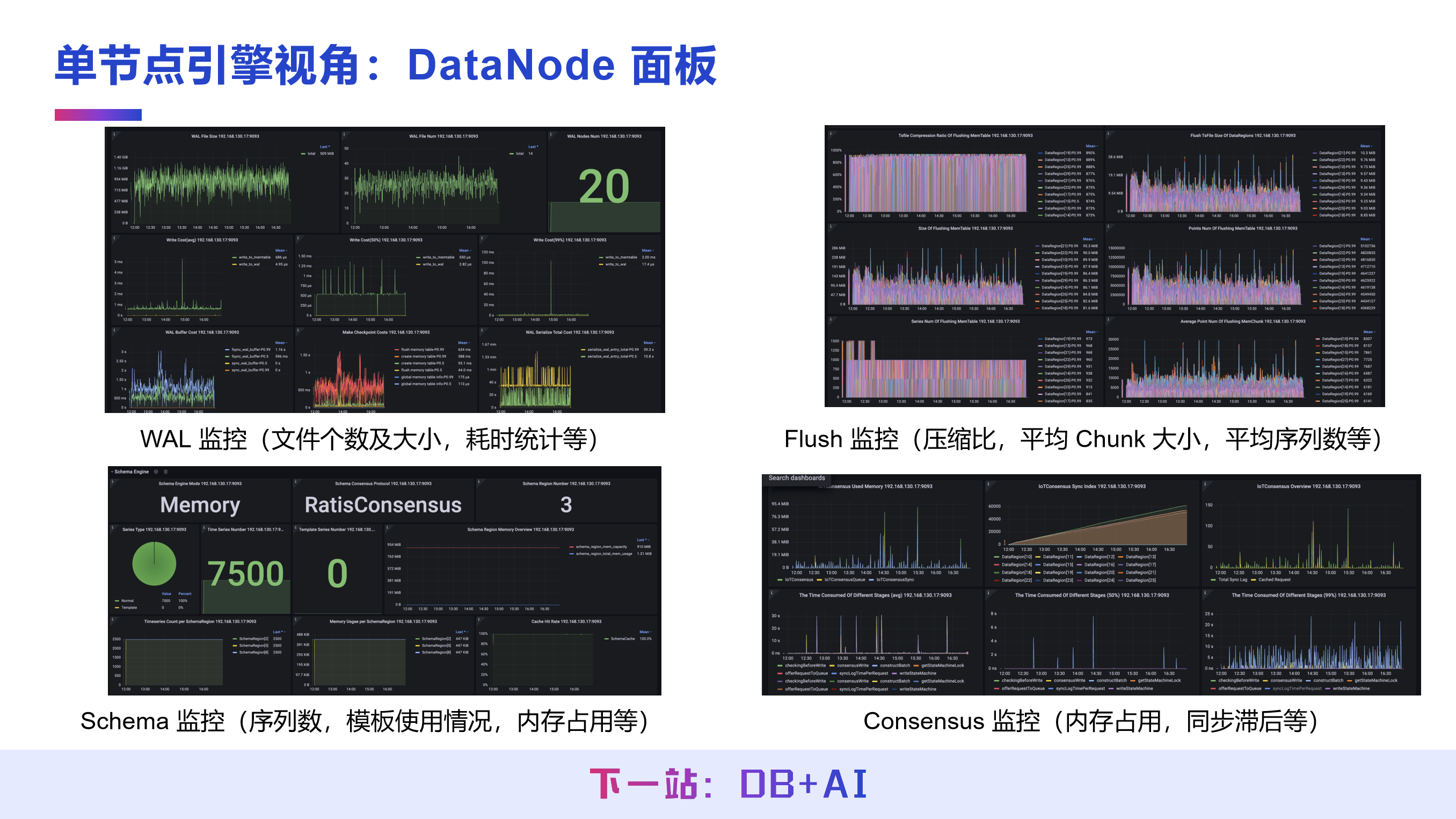
(4) DataNode 面板
DataNode 是与客户端直接交互的核心节点,该面板的监控维度非常细致,核心包括:
WAL 监控:监控写前日志的文件个数、大小、写入耗时等;
Flush 监控:统计内存数据刷盘压缩比、平均 Chunk 大小、平均序列数等;
Schema 监控:展示序列数、模板使用情况、元数据的内存占用等;
Consensus 监控:监控共识层的内存占用、数据同步滞后情况等。
05 典型调优案例分享
基于 IoTDB 可观测性体系与监控模块,结合实际业务场景中的性能问题,我们通过五个典型案例,梳理了 IoTDB 调优的核心思路与实操方法,验证监控体系在调优工作中的核心作用。
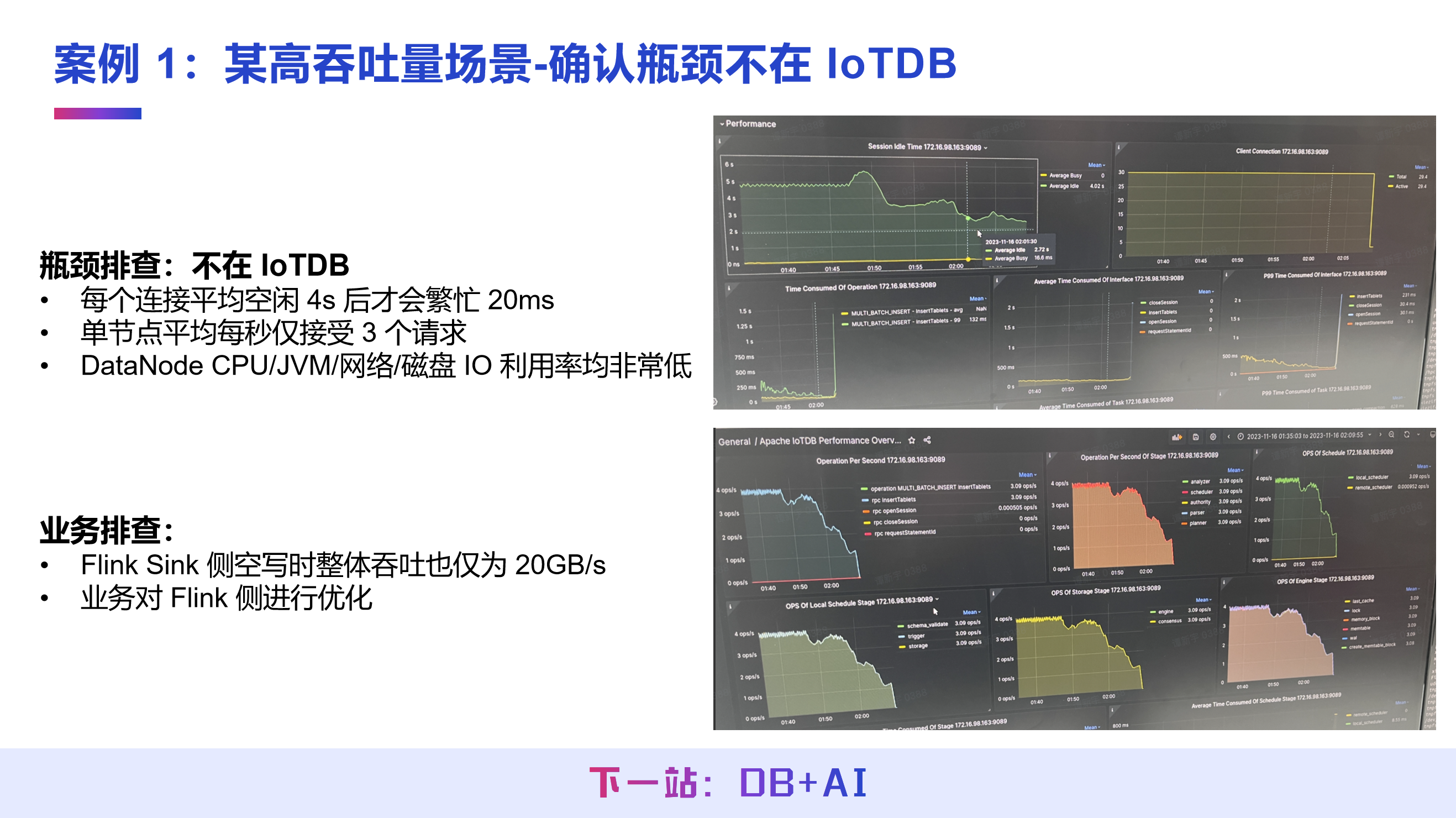
案例 1:高吞吐场景下,定位瓶颈点是否在 IoTDB
场景问题
在某个 96 节点的大规模 IoTDB 集群场景中,业务团队采用 “仿真程序生成数据→写入 Kafka 消息队列→Flink 集群消费消息队列→Flink 将数据写入 IoTDB 集群” 的架构,96 个节点的 IoTDB 集群写入吞吐仅为 15 GB/秒。
调优思路
通过 IoTDB 监控指标分析链路运行状态,发现核心问题并非出在 IoTDB:
1. IoTDB 每个连接平均空闲 4 秒后仅繁忙 20 毫秒,服务端长期处于空闲状态;
2. IoTDB 单节点平均每秒仅接收 3 个请求,客户端请求频率过低;
3. DataNode 的 CPU、JVM、网络、磁盘 IO 利用率均处于极低水平,服务端资源未得到充分利用。
业务侧基于该结论验证,将 Flink 写入 IoTDB 的链路断开后,Flink 空跑的整体吞吐仅为 20 GB/秒,确认瓶颈点在 Flink 客户端侧。
调优结果
业务侧对 Flink Sink 侧进行升级改造后,IoTDB 集群整体写入吞吐提升至 62.6 GB/秒,性能提升 4 倍以上,集群线性比达 0.89,性能损耗较低。
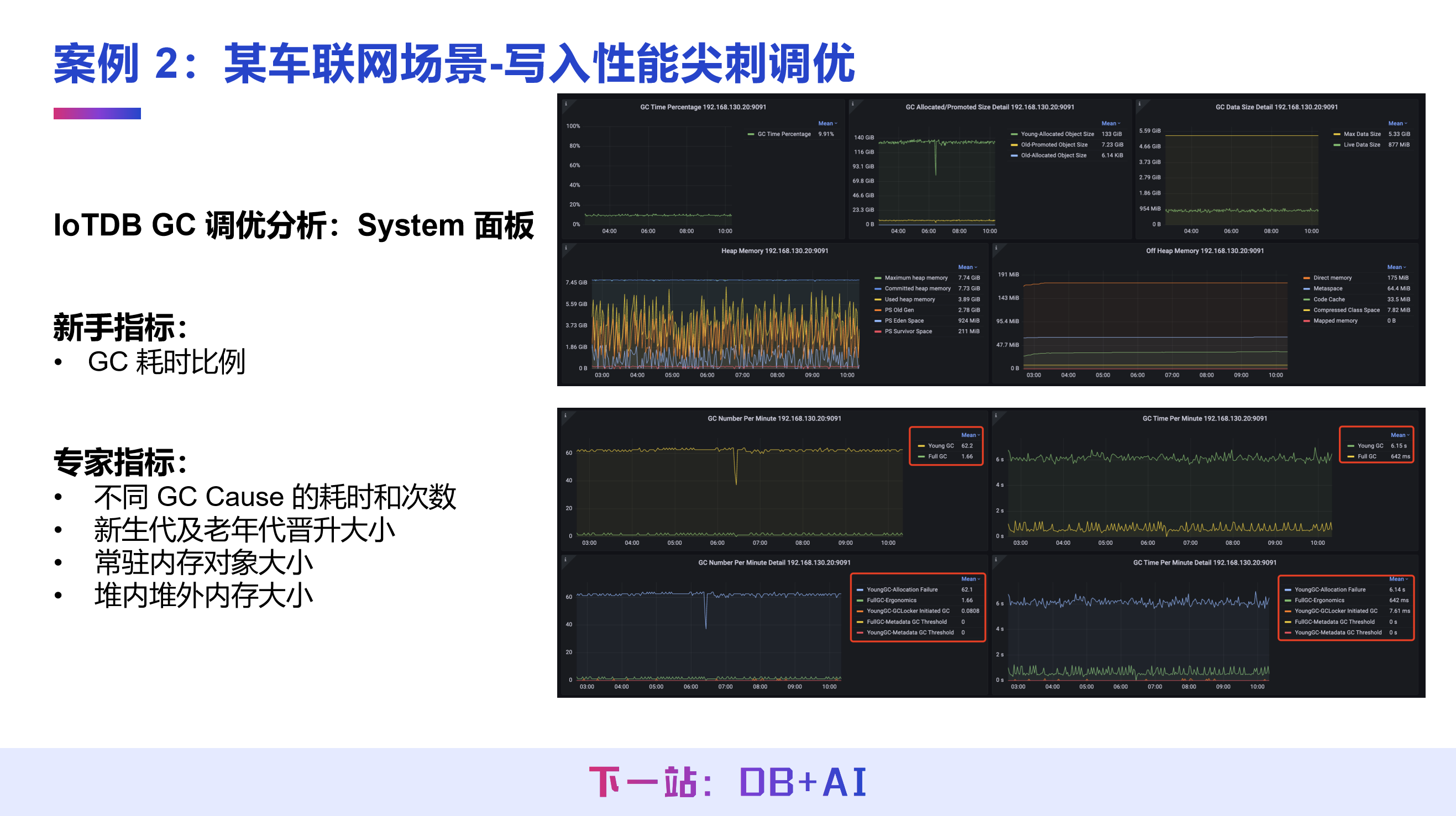
案例 2:车联网场景下,解决写入吞吐尖刺问题
场景问题
某车联网业务采用 “Kafka 消息作为数据源→Flink 集群消费消息队列→Flink 将数据写入 IoTDB 集群” 架构,写入过程中吞吐突然陡降甚至接近 0,出现写入失败的情况,且每 20 分钟触发一次 Full GC,耗时超 1 分钟。
调优思路
IoTDB 的 System 面板提供了多维度的 GC 监控指标,既包含适合新手的 GC 耗时比例,也有适合专业人员的 GC Cause 耗时/次数、新生代/老年代晋升内存大小、常驻内存对象大小、堆内/堆外内存大小等指标,快速定位 GC 问题。
通过 IoTDB 监控面板发现:
1. 集群写入吞吐监控显示,吞吐陡降为服务端运行问题;
2. 结合 JVM 监控面板,发现吞吐降为 0 的时间点与 Full GC 触发时间完全吻合,确认 Full GC 导致线程暂停,是写入尖刺的核心原因。
调优结果
业务团队将 GC 算法从 PS 更换为 G1,并对 JVM 参数做针对性调优,如延缓并发标记阈值、提升 MixedGC 吞吐、控制单次 GC 耗时软上限等。系统不再触发 Full GC,写入吞吐保持稳定,写入性能提升约 50%。
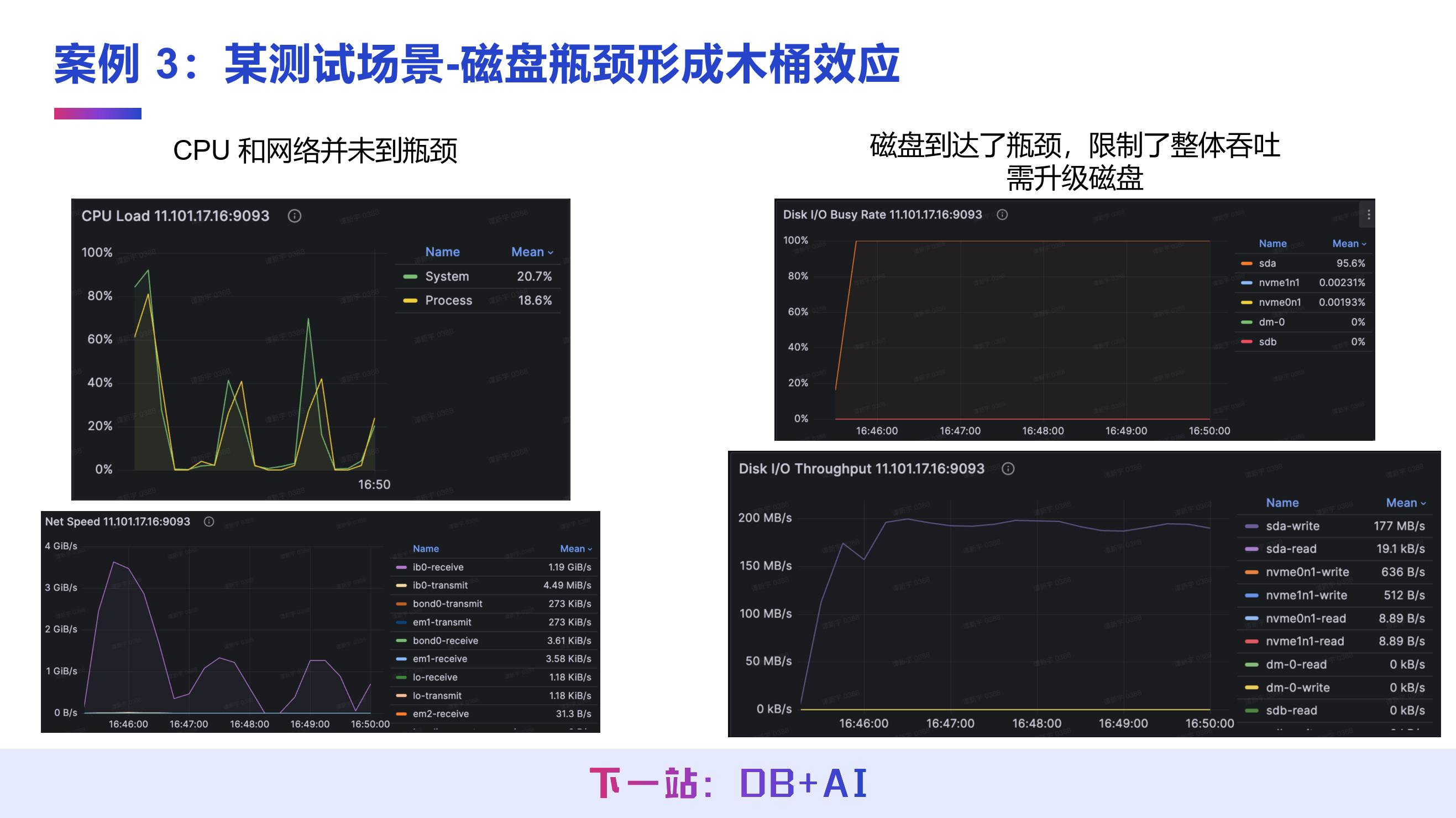
案例 3:测试场景下,解决磁盘瓶颈的木桶效应
场景问题
某单机 IoTDB 集群写入吞吐仅 1.2 GB/秒,需判断硬件升级方向,实现性能提升。
调优思路
通过资源监控面板分析各硬件负载,发现磁盘 I/O 使用率达到 100%,而 CPU、网络资源均未达到瓶颈,确认磁盘是限制吞吐的核心瓶颈。
调优结果
对服务器磁盘进行升级后,集群写入吞吐提升至 2.8 GB/秒,磁盘瓶颈解除。
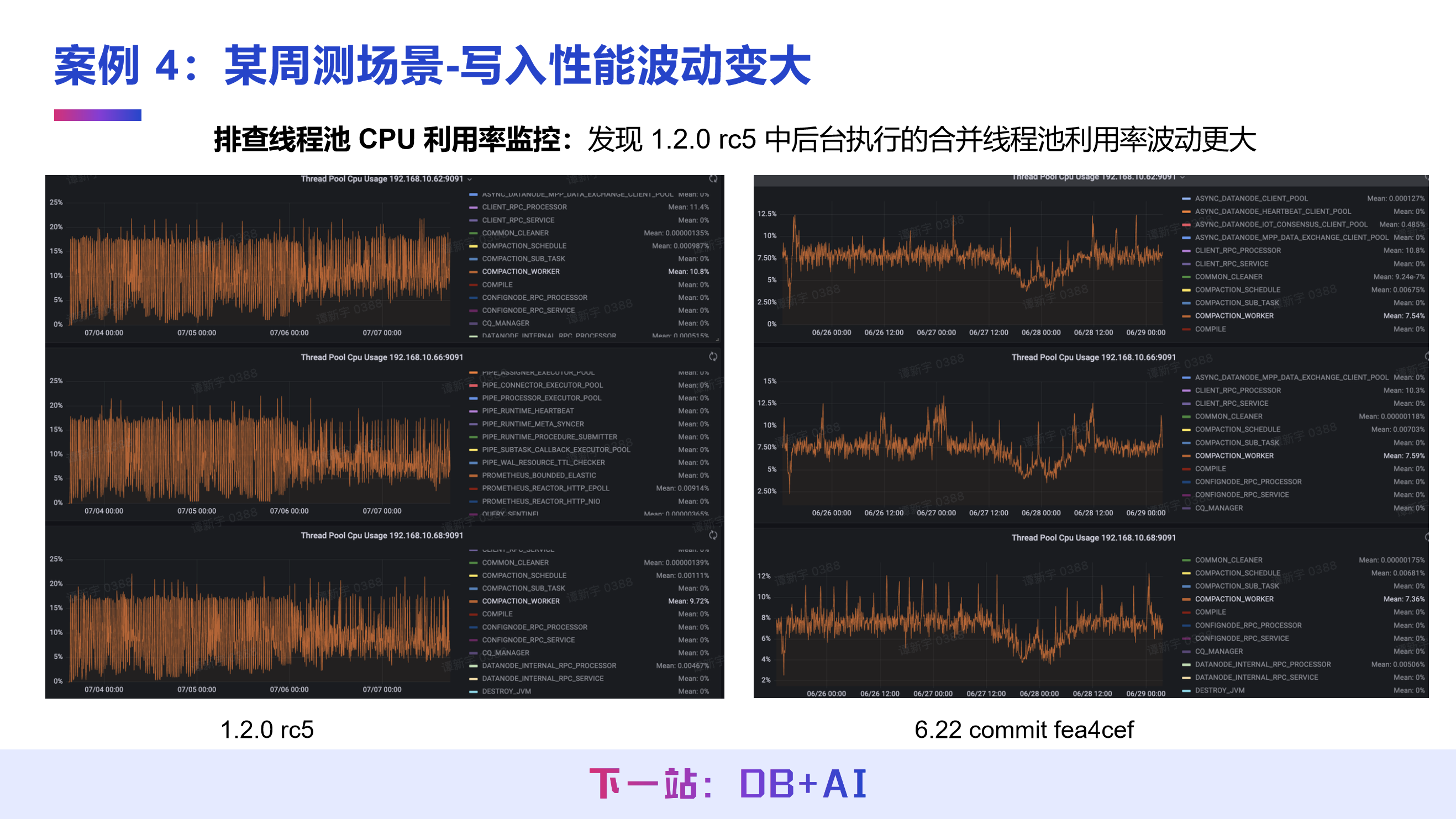
案例 4:周测场景下,解决写入性能波动变大问题
场景问题
IoTDB 版本升级后,写入吞吐出现明显抖动,老版本写入状态平稳,新版本写入波动严重。
调优思路
通过操作系统与进程 CPU 监控,发现新版本 CPU 利用率波动远大于老版本,确认性能抖动与 CPU 资源占用相关。
借助 IoTDB 精细化的 CPU 监控,分析进程内部不同模块、线程池的 CPU 占用,发现合并线程的 CPU 使用率抖动明显增加,确认合并线程的运行状态是导致写入性能波动的核心原因。
调优结果
新版本中已优化该问题,目前新版本写入状态恢复平稳。
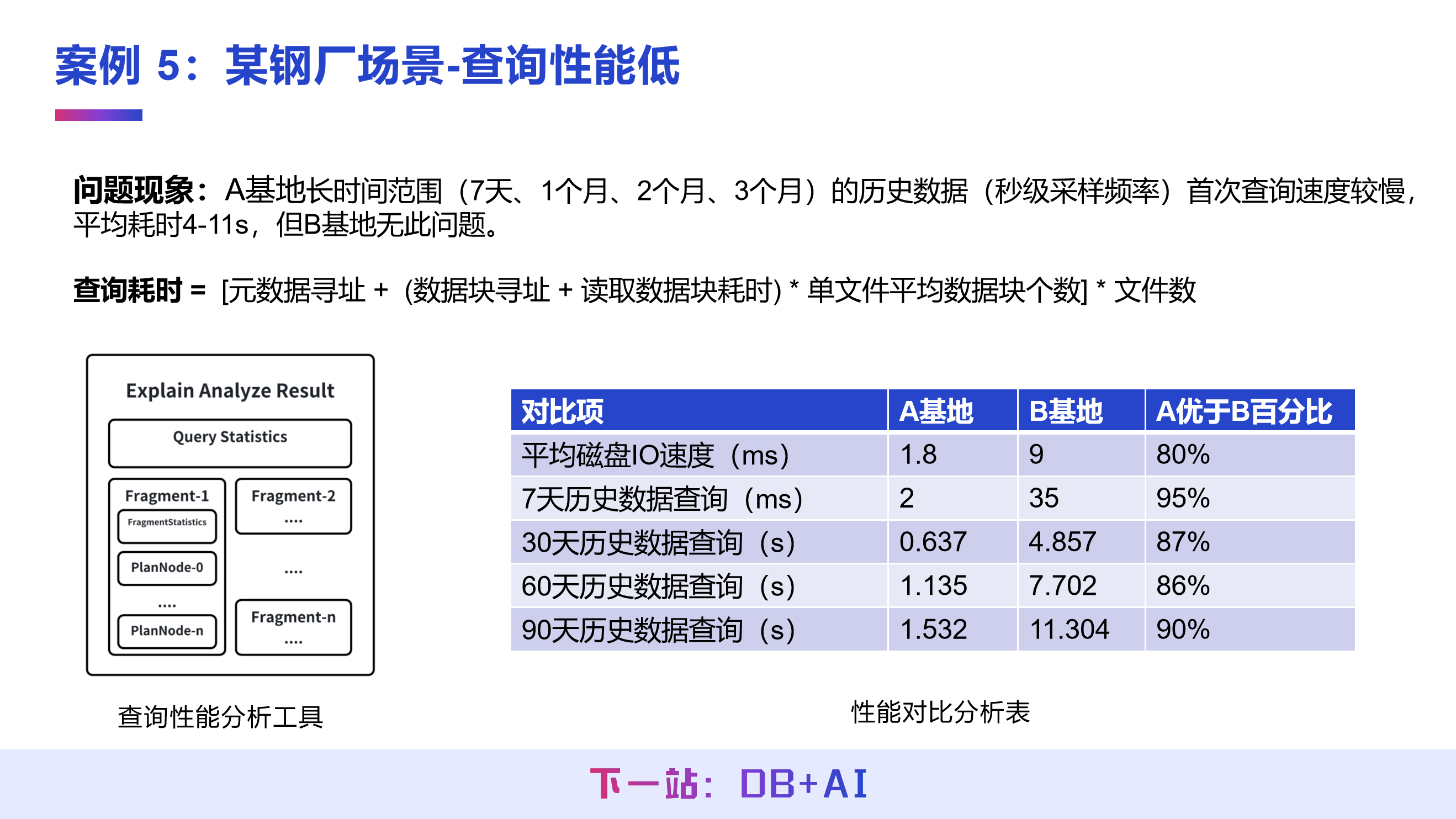
案例 5:钢厂场景下,优化长时间范围的查询性能
场景问题
某钢厂 A、B 两个基地采集的数据量相近,均需查询长时间范围(7 天、1 个月、2 个月、3 个月)的秒级历史数据,但 A 基地查询耗时 4~11 秒,B 基地可保持秒级查询,二者性能差异显著。
调优思路
对该场景的查询耗时拆解为公式表达:查询耗时 = [元数据寻址耗时 +(数据块寻址耗时 + 读取数据块耗时)× 扫描块个数] × 文件个数。通过拆解发现,查询耗时主要由磁盘文件读取决定。
进一步监控磁盘性能,发现 A 基地磁盘一次 I/O 耗时约 10 毫秒,B 基地仅为 1 毫秒,二者磁盘性能相差数倍,是查询性能差异的核心原因。
调优结果
业务团队将 A 基地的机械盘更换为固态硬盘后,查询耗时降至 1 秒以内,查询性能得到质的提升。
06 总结
IoTDB 系统调优的效果,取决于三大关键要点:可观测性工具的有效支撑、贴合业务的场景化调优策略落地,以及根据实际瓶颈的资源优先级调整。
在实际业务中,针对 IoTDB 硬件环境与业务负载开展的针对性调优,往往能实现 50% 甚至 1000% 的性能提升。结合 IoTDB 的可观测性体系与监控模块,能够让 IoTDB 更好地适配各类业务场景,发挥出更优的性能。
以上提到的 IoTDB 调优方法与实践案例,我们在去年的 2025 时序数据库技术创新大会上分享过,有兴趣的朋友可以点击视频观看!
更多内容推荐:
• 下载开源时序数据库 IoTDB
• 咨询Apache IoTDB 专家服务


