

论文成果总结
2025 年度,学术界多个时序数据研究团队围绕时序数据库 IoTDB 进行了多方面的科研创新,在数据库领域 CCF-A 类国际期刊和会议上共发表论文 10 篇,包括:ACM TODS 1 篇、SIGMOD 3 篇、VLDB 2 篇、ICDE 4 篇,涵盖引擎、存储、查询、分析等方面。
在引擎方面,通过原生 TsFile 格式和高效处理引擎,IoTDB 实现了高吞吐写入与低延迟查询。IoTDB 社区还设计了免迁移的弹性分布式存储方案,能够在保障系统容灾能力的同时,实现存储均衡。
在存储方面,通过引入基于离群值分离的位打包技术(BOS)、面向编码数据的 SIMD 向量化聚合管道以及创新的同态压缩框架(CompressIoTDB),IoTDB 社区显著提升了数据压缩比和查询性能。
在查询方面,针对 LSM 树存储结构,IoTDB 社区提出了基于随机摘要的分位数查询方法以降低 I/O 开销,并设计了迭代最大三角形采样算法(ILTS)来优化时序数据的可视化质量与效率。
在分析方面,IoTDB 社区实现了数据库内置的季节性趋势分解方法(OneRoundSTL)和时序聚类方案,并提出了具有收敛性保证的多变量时序协同插补技术,从而为复杂时序分析提供了高效、可靠的原生支持。
这一系列创新性成果,为应对物联网时代海量、高速、多样化的时序数据管理挑战提供了坚实的理论与性能支撑。

引擎
ACM TODS 2025: Apache IoTDB: A Time Series Database for Large Scale IoT Applications
🎯论文名称:Apache IoTDB:面向大规模物联网应用的时序数据库
✍️第一作者:王晨
典型的工业场景涉及成千上万的设备与数百万个传感器,持续生成数以十亿计的数据点。这对时间序列数据管理提出了新的需求,而现有解决方案未能充分应对这些需求,包括:设备定义的持续演进模式、周期性的数据采集、强关联的序列数据、不同程度延迟的数据到达,以及高并发的数据写入。
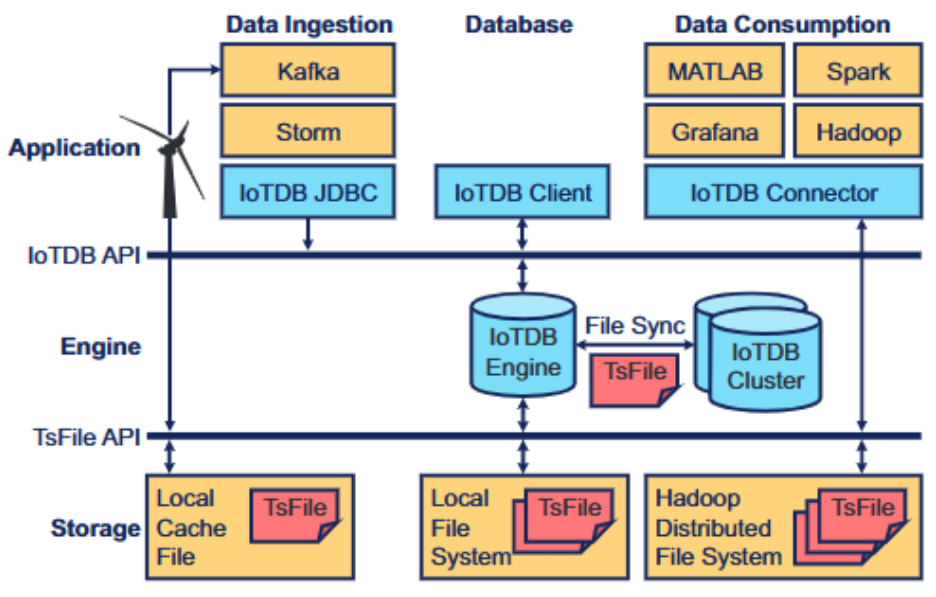
本文详细介绍了一种时间序列数据库管理系统——Apache IoTDB。该系统包含一种原生时间序列文件格式 TsFile,采用专门设计的数据编码方式;以及一个能够高效处理延迟数据到达与查询操作的 IoTDB 引擎。我们介绍了一种原生分布式解决方案,利用并行算子优化分布式查询。同时,我们探索了高效的 TsFile 同步机制,确保无需 ETL 流程即可实现无缝数据整合。
该系统实现了 1000 万数据点/秒的写入吞吐量。对于 10 万个数据点的单日数据查询,以及 1000 万个数据点的三年数据聚合查询,均可在 100 毫秒内完成处理。与 InfluxDB、TimescaleDB、KairosDB、Parquet 及 ORC 基于真实数据负载的对比实验,验证了 IoTDB 与 TsFile 的优越性。
📝全文链接:https://dl.acm.org/doi/10.1145/3726523
VLDB 2025: Migration-Free Elastic Storage of Time Series in Apache IoTDB
🎯论文名称:Apache IoTDB 中免迁移的时间序列弹性存储
✍️第一作者:陈荣钊
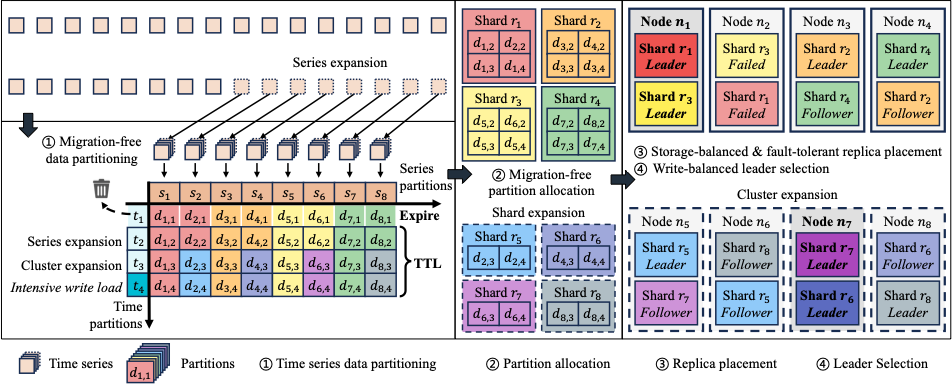
在分布式时序数据库(TSDB)中,时序数据通常按序列和时间进行分区。这些分区随后被分配到分片,分片的副本决定了存储位置,而领导者负责管理写入负载。在物联网(IoT)场景中,随着传感器数量的不断增长,集群也会随之扩展,重新平衡存储的一种常见方法是迁移现有分区,但这会产生额外的开销。
通常,时序数据库会通过生存时间(Time to Live,TTL)来自动卸载过期数据,因此动态扩展分片而不是迁移现有分区也可以恢复存储平衡。同时,集群的容灾能力取决于副本放置方案,而集群的扩展会使这个问题变得更加复杂。物联网场景中的密集写入负载需要平衡的领导者选择,而容灾放置方案使得该选择变得困难。
论文中提出了一种具有可靠容灾能力,且存储均衡的副本放置算法,以及一种写均衡的领导者选择算法,以解决上述问题。该解决方案已在 Apache IoTDB 1.3 版本中成功部署,广泛评估证明了其在可用性和性能方面的卓越性。
📝全文链接:https://dl.acm.org/doi/10.14778/3725688.3725706
存储
ICDE 2025: BOS: Bit-packing with Outlier Separation
🎯论文名称:BOS:基于离群值分离的位打包技术
✍️第一作者:肖今朝
位打包是多种数据编码与压缩方法的基础操作,其核心思想是采用固定位宽来表示序列中所有经过处理的值。然而,某些极大值(称为上界离群值)会显著增加所需位宽,导致大多数较小值存储时的位浪费。值得注意的是,不仅是大值(上界离群值),小值(下界离群值)同样可能引起位宽浪费。
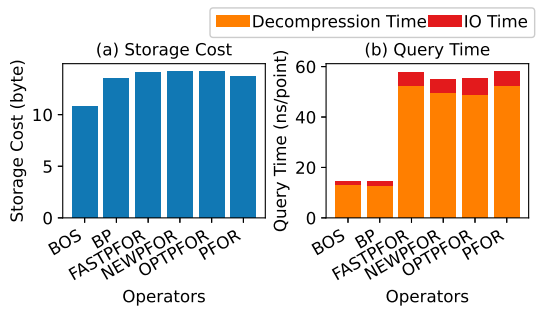
本文提出通过分离上下界离群值来优化存储的方法(BOS):将离群值单独存储后,剩余中心值的分布范围变窄(即压缩位宽),需要额外成本记录离群值位置。该问题的核心在于如何确定最优的上下界离群值分离阈值,以实现最小化存储成本。相较于使用搜索时间为 O(n²) 的全枚举上下界阈值,我们创新性地采用位宽作为分离依据,将搜索时间降至 O(nlogn)。理论分析表明,基于位宽的分离策略在所有可能情况下都能获得与值分离法相同的优化解,并进一步提出结合中位数与位宽的近似分离策略,搜索时间进一步降至 O(n)。
BOS 方案可与现有所有基于位打包的压缩方法兼容,目前已在 Apache IoTDB 和 Apache TsFile 中全面替代传统位打包方法。大量真实数据集实验表明,在各种压缩方法中用 BOS 替代位打包后,压缩比从约 2.75 显著提升至 3.25。
📝全文链接:https://ieeexplore.ieee.org/document/11113092
ICDE 2025: Exploring SIMD Vectorization in Aggregation Pipelines for Encoded IoT Data
🎯论文名称:面向编码物联网数据聚合管道中的 SIMD 向量化技术探索
✍️第一作者:康瑞
时序数据库用于采集和分析工业设备传感器发送的海量数据,在物联网领域至关重要。无论是从网络接收的数据还是数据库存储的数据,都经过高效编码以减少 I/O 占用和延迟。物联网编码器通过组合差分编码、重复值压缩和打包编码算子,实现了比单独使用任一方法更高的压缩比。然而,因为处理查询前必须进行串行解码,高效的压缩反而增加了查询执行难度,而选择性聚合(如降采样)是时序分析查询的核心操作。
本文提出了一套基于编码数据数组的算子体系,用于加速物联网聚合查询处理,可扩展集成线程级和指令级设计,创新性地实现了无需解码即可并行聚合编码数据的能力,并能够利用编码统计信息减少冗余计算。这些算子构建的管道式查询引擎已集成至开源数据库 Apache IoTDB 中。系统评估表明,该方案在选择性聚合查询效率上较现有工作实现了显著提升。
📝全文链接:https://ieeexplore.ieee.org/document/11112860

VLDB 2025: Improving Time Series Data Compression in Apache IoTDB
🎯论文名称:提升 Apache IoTDB 的时间序列数据压缩性能
✍️第一作者:Yuxin Tang
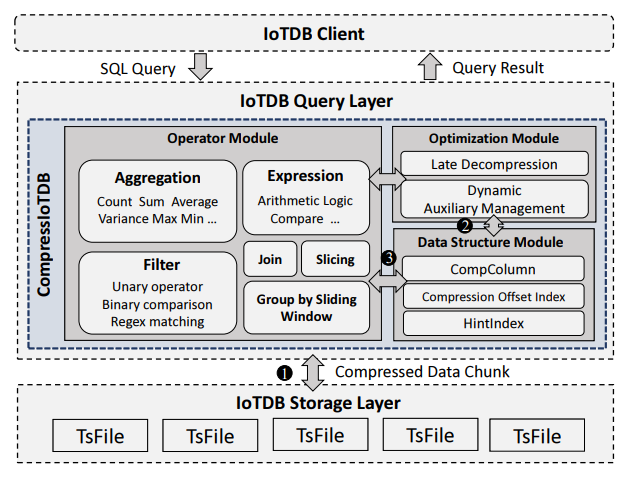
时间序列数据在各领域以前所未有的规模产生。尽管传统压缩技术能降低存储成本,但它们通常需要在查询前完全解压数据,导致查询延迟增加和资源消耗上升。同态压缩(HC)技术允许直接对压缩数据进行计算而无需解压,展现出既能减少存储成本又能提升查询性能的潜力。然而,时间序列数据特有的复杂性给现有的 HC 方法带来了无法充分应对的挑战。
本文在时序数据领域引入 HC 理论,革新性地实现了时序数据库查询的同态压缩。基于我们的理论,我们开发了 CompressIoTDB:一个集成于 Apache IoTDB 的新型同态压缩框架。通过采用我们提出的 CompColumn 结构,该框架支持广泛的查询算子,包括过滤、聚合和窗口函数,同时全程保持数据的压缩状态。此外,我们还引入了延迟解压和动态辅助管理等系统级优化,进一步提升查询效率。
大量实验表明,CompressIoTDB 显著提升了时间序列数据的查询处理性能,平均吞吐量提高了 53.4%,内存使用降低了 20%。
📝全文链接:https://dl.acm.org/doi/10.14778/3748191.3748204
查询
SIGMOD 2025: Randomized Sketches for Quantile in LSM-tree based Store
🎯论文名称:基于 LSM 树存储的分位数随机摘要
✍️第一作者:陈子陵
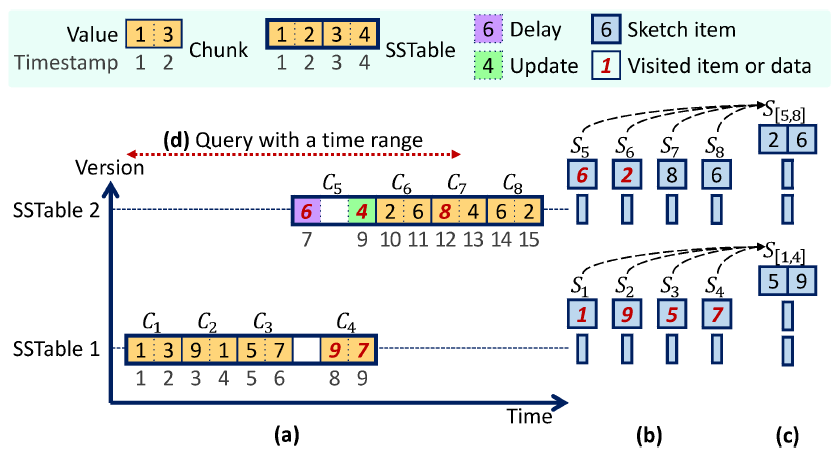
分位数的精确计算代价高昂,但可以通过分位数摘要进行高效估计。现有关于流数据汇总(如 KLL)的研究主要致力于在给定误差控制下最小化内存开销。然而在基于 LSM 树的存储系统中进行分位数估计时,流式处理方法会产生与数据量 N 成线性关系的昂贵 I/O 开销。由于 LSM 树中的磁盘组件(数据块和 SSTable)一旦刷盘就不可改变,可以将分位数摘要作为一种预计算统计信息来降低 I/O 开销并加速查询。若要为查询数据提供确定性的加性误差 εN 保证,所有被查询数据块(单个大小为 Nc)的预计算确定性摘要都必须提供 εNc 误差保证,导致线性 I/O 开销无法改善。
本文提出预计算随机摘要方案以提供随机加性误差保证,主要技术创新包括:(1) 针对刷盘构建的数据块随机摘要(经证明具有最优性,可实现与 √N 成正比的 I/O 开销);(2) 针对压缩构建 SSTable 分层随机摘要,可进一步改善渐进 I/O 开销;(3) 总结预计算的 KLL 摘要比总结流数据的 KLL 摘要更准确,可在与流数据相同的内存复杂度条件下实现次线性 I/O 开销。在合成数据集和真实数据集上的大量实验验证了该技术的优越性,该方案已部署于基于 LSM 树的时序数据库 Apache IoTDB 中。
📝全文链接:https://dl.acm.org/doi/10.1145/3709717
SIGMOD 2025: Largest Triangle Sampling for Visualizing Time Series in Database
🎯论文名称:面向数据库时间序列可视化的最大三角形采样方法
✍️第一作者:芮蕾
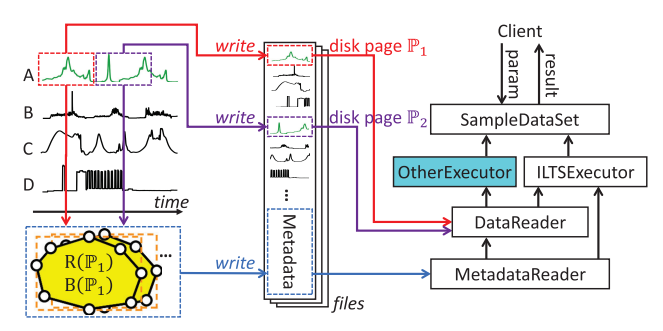
在时间序列可视化中,降采样技术用于减少数据点数量,并保留原始时间序列的视觉特征。基于面积的最大三角形采样法(LTS)在保留感知关键点方面表现优异。然而,通过顺序采样局部最大三角形面积的点的启发式解决方案(即 LTTB 算法)存在次优解和查询效率低下的问题。
针对这些缺陷,我们提出了一种创新的迭代最大三角形采样算法(ILTS),通过凸包加速技术进行优化。该算法可以迭代优化采样结果,通过在每次迭代中集成更多数据点以获取更广阔的视角。我们证明了在预先计算的凸包中始终可以找到最大的三角形,从而保证了迭代采样过程的高效性。实验结果表明,相较于现有的最优基线,新算法显著提升了视觉质量,与蛮力方法相比,速度有显著提升。
📝全文链接:https://dl.acm.org/doi/10.1145/3709699
分析
ICDE 2025: OneRoundSTL: In-Database Seasonal-Trend Decomposition
🎯论文名称:OneRoundSTL:数据库内置的季节性趋势分解方法
✍️第一作者:陈子杰
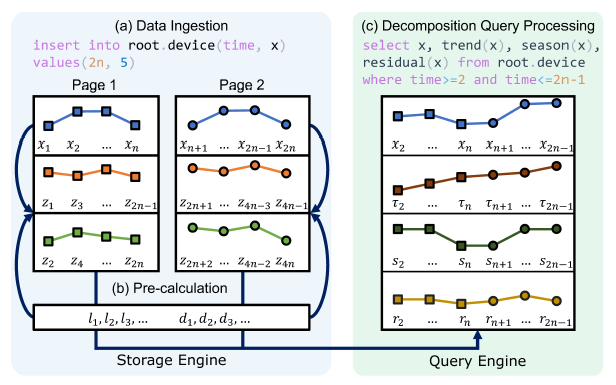
季节性趋势分解方法在时序分析中应用广泛,例如时间序列预测和异常检测。现有的季节性趋势分解方法(如 STL 及其变体)通常假设时间序列是完整且按时间戳排序的。然而,主流时序数据库多采用基于 LSM 树的存储结构,其数据页中的存储顺序往往与时间顺序不一致。此外,数据库中的时序数据常因传感器故障等原因存在数据缺失,进一步破坏了数据的完整性。常规解决思路是先合并排序不同数据页的内容再进行分解,但这会导致沉重的在线计算负担和多次查询时的重复计算,且仍无法处理残留的缺失数据。
本文提出 OneRoundSTL 方法,通过在离线阶段预计算各独立数据页的结果,在查询时拼接这些预计算结果即可获得分解结果。该方案已在开源时序数据库 Apache IoTDB 中实现并作为内置功能部署。系统在合成数据集和真实数据集上的实验表明,OneRoundSTL 在保持分解效果的同时,其执行效率远超现有最优方法。
📝全文链接:https://ieeexplore.ieee.org/document/11112870
SIGMOD 2025: In-Database Time Series Clustering
🎯论文名称:数据库内的时序聚类
✍️第一作者:苏云祥
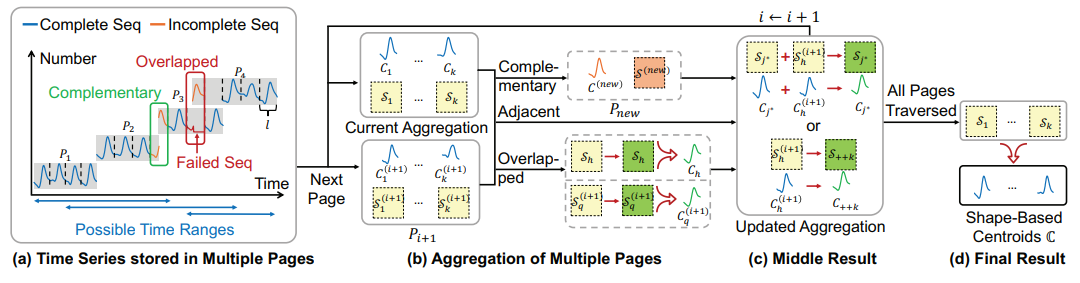
时序数据常需在不同时间范围内反复聚类,以挖掘不同时段频繁出现的子序列模式,从而为下游应用提供支持。当前最先进的时序聚类方法(如 K-Shape)能有效根据形态特征进行聚类,但在数据量庞大、效率要求高的物联网场景中,数据库内的时序聚类问题始终未被充分研究。多数时序数据库采用基于 LSM 树的存储架构应对高频写入,但这会导致底层数据点产生乱序时间戳。因此,若直接应用现有的数据库外时序聚类方法,必须将所有数据完全加载到内存中,并重新按时间排序,且每次处理跨不同时间范围的查询时都需从头开始聚类,效率低下。
本文提出数据库内适配的时序聚类方法 K-Shape 改进方案,并针对长时序数据处理问题,提出 Medoid-Shape 方法及其数据库内适配方案,以进一步提升使用速度。大量实验证明,该方案在同等效果下显著提升了效率。所有技术已在开源商用时序数据库 Apache IoTDB 中实现。
📝全文链接:https://dl.acm.org/doi/10.1145/3709696
ICDE 2025: Collaborative Imputation for Multivariate Time Series with Convergence Guarantee
🎯论文名称:具有收敛性保证的多变量时间序列协同插补
✍️第一作者:孙宇
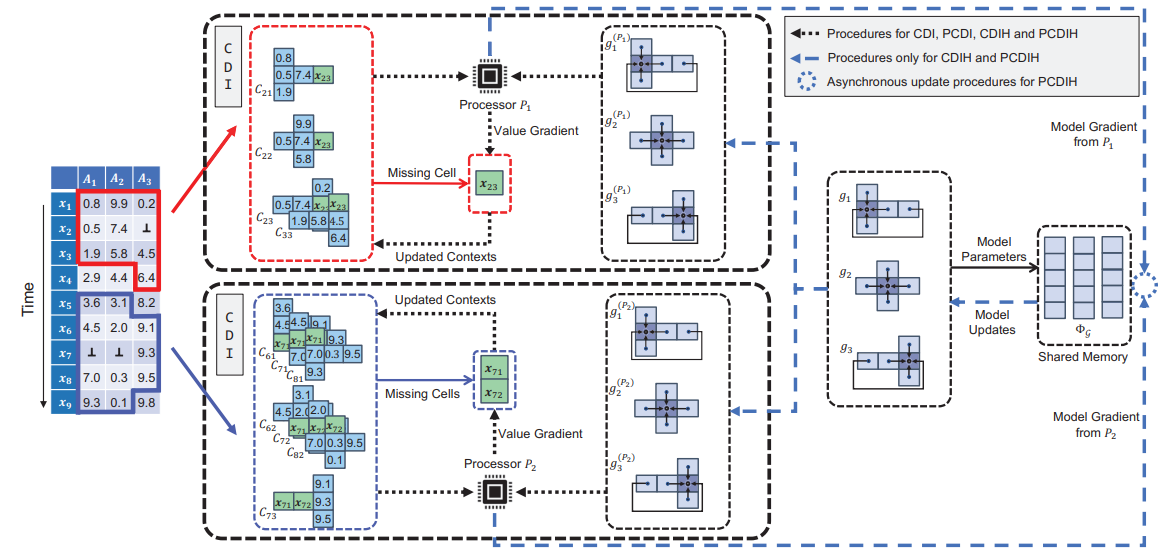
缺失值在多变量时间序列中经常出现,这影响了数据分析和应用。现有研究通常使用完整数据来训练插补模型,然后用其填补缺失值。然而在实践中,缺失值可能出现在不同的单元格中,这种多样性阻碍了插补模型的性能,甚至在缺乏收敛保证(即无法确保在迭代趋于无穷时获得最优解)的情况下使填补无法进行。原因在于:(1) 多个单元格的插补值在满足模型一致性方面可能相互影响;(2) 从完整数据中获得的依赖关系可能不足以准确插补大量未观测值,这给收敛性带来了更严峻的挑战。
本论文中,我们研究了具有收敛性保证的协同插补方法。所谓“协同”,我们指的是:(1) 所有缺失单元格能够以协同方式被插补,并保证符合模型一致性;(2) 插补模型也能根据填补值实现优化。我们的主要技术亮点包括:(1) 引入基于似然最大化的、具有统计可解释性的协同插补方法;(2) 设计一种针对多个缺失单元格的协同插补算法,并将其等效扩展为并行版本;(3) 以协同方式并行优化插补值和模型,并在此过程中保证算法的收敛性;(4) 设计流式插补和自适应参数确定策略。
在真实不完整数据集上的实验表明,我们的方法在插补准确性和下游应用性能上均优于十二种基线方法。
📝全文链接:https://ieeexplore.ieee.org/document/11112895
添加欧欧小助手(微信号:apache_iotdb),并发送“2025 论文”,可免费获得“2025 IoTDB 论文合集”!
更多内容推荐:
• 下载开源时序数据库 IoTDB
• 咨询企业版


