

在大数据时代,高效的数据存储和管理是科研和工业应用成功的关键。HDF5 是一种嵌套的实验数据管理格式,TsFile 作为新型的时序数据存储格式,各自具有独特的特点和优势。本文将深入探讨 HDF5 的起源、应用场景、存在的问题,以及 TsFile 和 HDF5 的异同点。
01 HDF5 起源
HDF5,全称 Hierarchical Data Format 分层数据格式,包含一整套用于存储和管理数据的数据模型、库和二进制文件格式。它起源于 1987 年,由美国国家超级计算应用中心(NCSA)的 GFTF 小组提出。
HDF5 的初衷是为了实现一种架构无关的文件格式,满足 NCSA 在使用多种不同计算平台之间移送科学数据的需求。
02 应用场景
HDF5 的应用场景主要包括在科学计算、工程模拟、气象预测等领域的实验数据管理需求。
场景一:科学数据存储
在科学计算和研究领域,经常需要存储和处理具有复杂结构的多维数据,如多维矩阵和气象网格数据。这些数据集通常包含大量的元数据,需要一个能够提供高效数据组织和访问方式的存储解决方案。
场景二:设备传感器数据存储
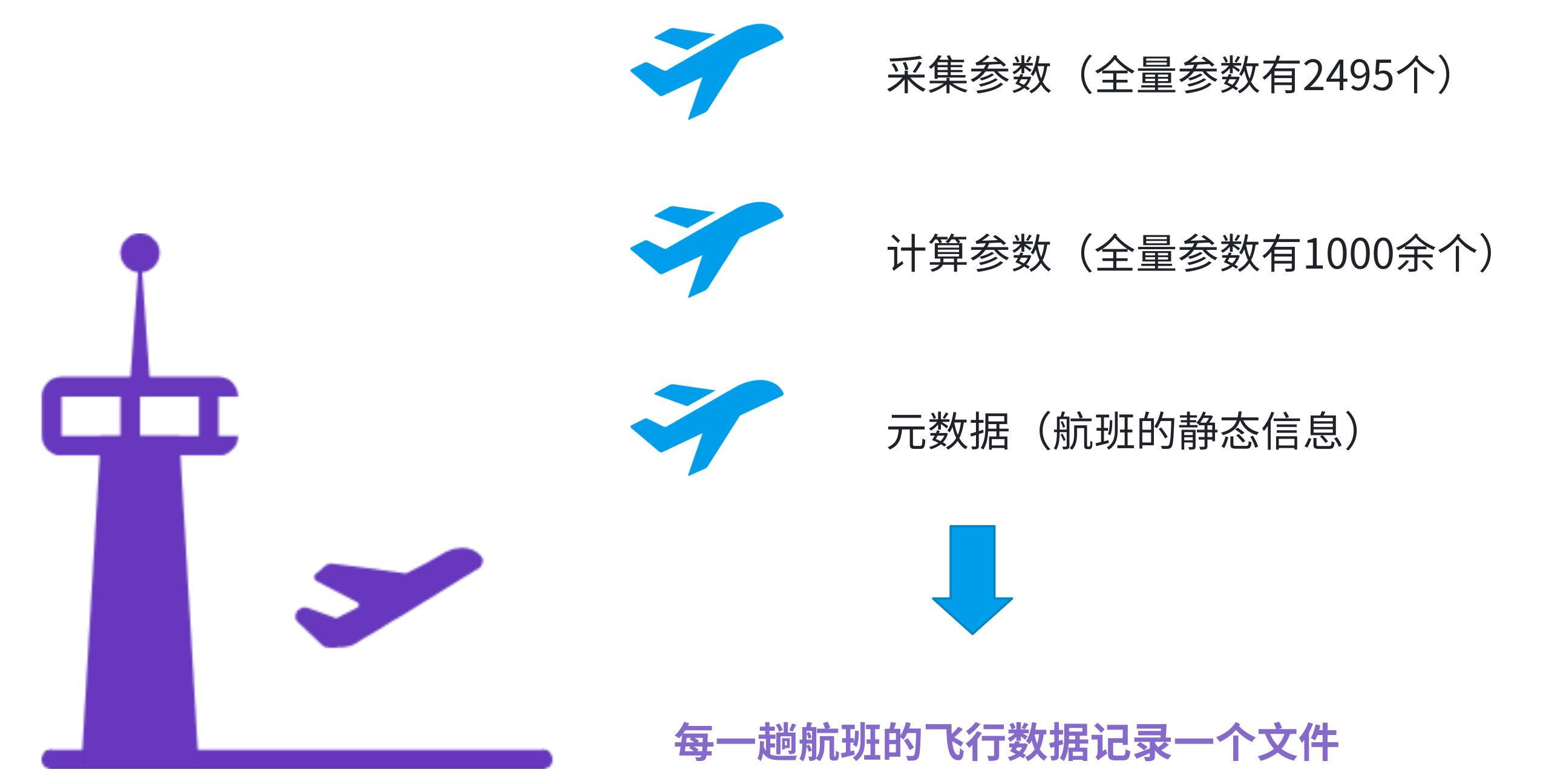
在设备监控和传感器网络中,需要存储来自各种传感器的大量数据。例如,某航空机构的结构健康监测系统的数据,这些数据包括各种传感器采集的振动、温度等信息,对设备的状态监测和故障预测具有重要意义。
场景三:粒子仿真数据存储
在粒子仿真领域,仿真程序可能会产生大量的实验数据,包括粒子的轨迹、能量沉积等信息。这些数据对于理解物理过程和优化仿真参数具有重要意义,需要一个能够高效存储和管理这些数据的系统。
03 TsFile 简介
在 HDF5 的应用场景中,有不少实验数据的格式其实是时序数据,TsFile 则是专为时序数据设计的列式存储文件格式,由清华大学软件学院团队主导研发,并于 2023 年成为 Apache 顶级项目。TsFile 格式的优势为高性能、高压缩比、自解析、支持灵活的时间范围查询。

04 TsFile 与 HDF5 对比
下面从不同维度对 TsFile 与 HDF5 进行详细的对比:
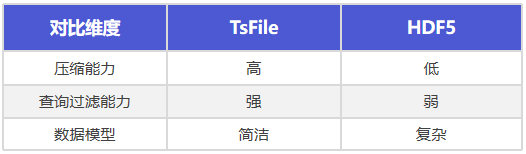
(1) 压缩比
TsFile:结合时序专用编码(如 TS_2DIFF 时间戳差值编码、GORILLA 浮点数压缩等)与多种高效压缩算法(如 SNAPPY、ZSTD、LZ4 等),通过协同优化消除数据冗余。对于变长对象,动态分配变长数据空间,避免字节对齐填充;采用紧凑存储策略减少冗余,尤其适配稀疏数据和变长字符串场景。
HDF5:仅依赖通用压缩算法(如 gzip、lzf、szip),缺乏针对时序数据的编码,无法充分利用数据特征进行优化。对于变长对象,采用固定空间分配(如复合数据类型),导致字节对齐浪费和稀疏数据存储冗余高。
(2) 查询过滤能力
TsFile:提供了强大的查询过滤能力,支持根据序列 ID 和时间范围精确读取特定范围的数据,无需读取全量数据。
HDF5:仅支持全量数据读取,无法高效过滤特定范围数据。
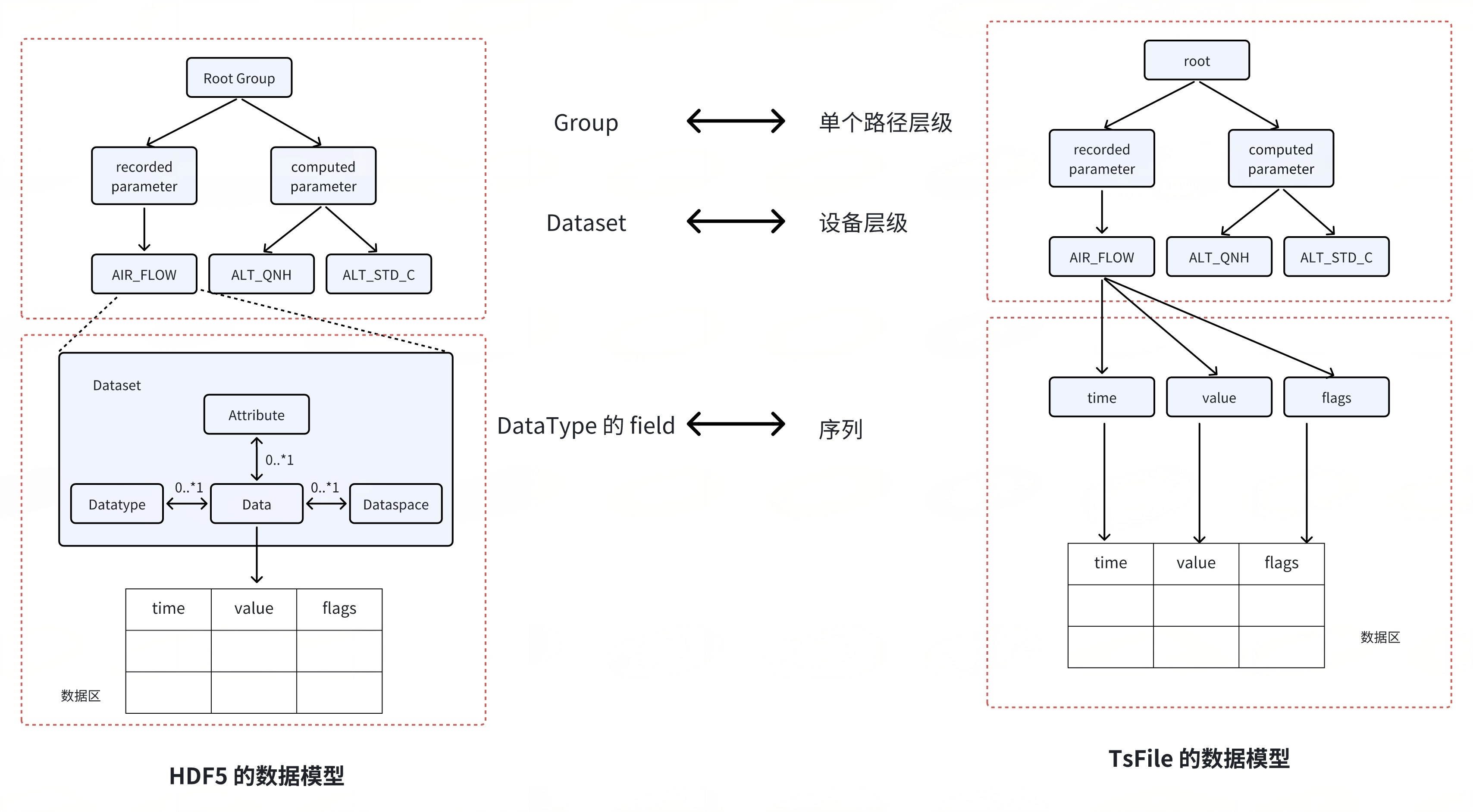
(3) 数据模型
TsFile:专为时序数据设计,数据模型能够更好地适应时间序列数据的特征,采用轻量化的时间戳-数据点的模型,结构简洁高效。
HDF5:支持多维数组、复合类型等复杂结构,但模型复杂度高。
05 使用示例对比
以下两个文件格式接口示例所使用数据的元数据信息为:在一个工厂 factory1 当中的设备 device1 上产生的数据,数据信息含有(时间 time long,值 s1 long)。
(1) TsFile 写入示例
// 创建一个名为test的 tsfile文件
file.create("test.tsfile", O_WRONLY | O_CREAT | O_TRUNC, 0666);
// 创建表元数据来描述在tsfile当中的表信息
auto* schema = new storage::TableSchema(
"factory1",
{
common::ColumnSchema("id", common::STRING, common::LZ4, common::PLAIN, common::ColumnCategory::TAG),
common::ColumnSchema("s1", common::INT64, common::LZ4, common::TS_2DIFF, common::ColumnCategory::FIELD),
});
// 使用文件句柄和表元数据信息,创建表数据的写入器
auto* writer = new storage::TsFileTableWriter(&file, schema);
// 用写入数据的元数据信息构建tablet,用于批量写入数据
storage::Tablet tablet("factory1", {"id1", "s1"}, {common::STRING, common::INT64}, {common::ColumnCategory::TAG, common::ColumnCategory::FIELD}, 10);
// 遍历数据 将其组织为 tablet
for (int row = 0; row < 5; row++) {
long timestamp = row;
tablet.add_timestamp(row, timestamp);
tablet.add_value(row, "id1", "machine1");
tablet.add_value(row, "s1", static_cast<int64_t>(row));
}
// 将tablet的数据写入磁盘
writer->write_table(tablet);
// 将内存当中剩余的相关数据都写入磁盘
writer->flush();
// 关闭写入器
writer->close();(2) HDF5 写入示例
typedef struct {
long time;
long s1;
} Data;
// 创建一个名为test的hdf5文件,H5F_ACC_TRUNC说明如果文件已经存在,会覆盖原来的文件
file_id = H5Fcreate("test.h5", H5F_ACC_TRUNC, H5P_DEFAULT, H5P_DEFAULT);
// 创建一个group挂载在rootgroup下面
group_id = H5Gcreate2(file_id, "factory1", H5P_DEFAULT, H5P_DEFAULT, H5P_DEFAULT);
// 准备数据维度数组,构建dataspace
hsize_t dims[1] = { (hsize_t)rows };
hid_t dataspace_id = H5Screate_simple(1, dims, NULL);
// 准备数据类型,构建datatype
hid_t datatype_id = H5Tcreate(H5T_COMPOUND, sizeof(Data));
H5Tinsert(filetype, "time", 0, H5T_NATIVE_LONG);
H5Tinsert(filetype, "s1", sizeof(long), H5T_NATIVE_LONG);
// 设置数据集的chunk块大小以及压缩信息
hid_t dcpl = H5Pcreate(H5P_DATASET_CREATE);
// 设置 chunk 尺寸,chunk 尺寸不能大于数据集尺寸
hsize_t chunk_dims[1] = { (hsize_t)row };
H5Pset_chunk(dcpl, 1, chunk_dims);
// 设置 GZIP 压缩,压缩级别为1
H5Pset_deflate(dcpl, 1);
// 创建一个dataset挂载在前面的“factory1”group下面
dataset_id = H5Dcreate2(group_id, "machine1", datatype_id, dataspace_id, H5P_DEFAULT, dcpl, H5P_DEFAULT);
// 构建数据容器和填充数据
Data *dset = (Data *)malloc(rows * sizeof(Data));
for (int i = 0; i < rows; i++) {
dset[i].time = static_cast<int64_t>(i);
dset[i].s1 = static_cast<int64_t>(i)
}
// 将数据写入到dataset当中
status = H5Dwrite(dataset_id, datatype_id, H5S_ALL, H5S_ALL, H5P_DEFAULT, dset);
// 关闭前面所创建的对象
free(dset);
status = H5Dclose(dataset_id);
status = H5Gclose(group_id);
status = H5Sclose(dataspace_id);
status = H5Fclose(file_id);(3) TsFile 查询示例
// 使用tsfilereader来打开名为test的tsfile文件
storage::TsFileReader reader;
reader.open("test.tsfile");
// 指定想要查询的列名
storage::ResultSet* temp_ret = nullptr;
std::vector<std::string> columns;
columns.emplace_back("id1");
columns.emplace_back("s1");
// 指定查询的表名,查询的列,时间范围,查询结果会放置于最后的指针当中
reader.query("factory1", columns, 0, 100, temp_ret);
auto ret = dynamic_cast<storage::TableResultSet*>(temp_ret);
// 检查查询是否异常,并不断next获取结果
bool has_next = false;
while ((code = ret->next(has_next)) == common::E_OK && has_next) {
std::cout << ret->get_value<Timestamp>(1) << std::endl; // 时间戳列是第1列,之后的数值列的索引号从1开始
std::cout << ret->get_value<int64_t>(1) << std::endl;
}
// 关闭查询结果指针和读取器
ret->close();
reader.close();(4) HDF5 查询示例
// 打开已有的hdf文件
file_id = H5Fopen("test.h5", H5F_ACC_RDONLY, H5P_DEFAULT);
// 打开rootgroup下面指定名字的group
group_id = H5Gopen2(file_id, "factory1", H5P_DEFAULT);
// 打开 factory1 这个group下面的指定名字的dataset
dataset_id = H5Dopen2(group_id, "machine1", H5P_DEFAULT);
// 获取dataset的datatype和dataspace,为后续准备结果容器做准备
datatype_id = H5Dget_type(dataset_id);
dataspace_id = H5Dget_space(dataset_id);
// 拿到dataset的维度信息
int ndims = H5Sget_simple_extent_ndims(dataspace_id);
H5Sget_simple_extent_dims(dataspace_id, dims, NULL);
// 根据维度信息构建结果数组容器
int rows = (int)dims[0];
Data *dset = (Data *)malloc(rows * sizeof(Data));
// 根据维度信息和数据类型,从dataset当中读取出结果
status = H5Dread(dataset_id, filetype, H5S_ALL, H5S_ALL, H5P_DEFAULT, dset);
// 遍历输出所有数据
for (int i = 0; i < rows; i++) {
printf("Row %d: time: %ld, s1: %ld", i, dset[i].time, dset[i].value);
}
// 关闭所有打开的资源
free(dset);
status = H5Dclose(dataset_id);
status = H5Gclose(group_id);
status = H5Sclose(dataspace_id);
status = H5Fclose(file_id);(5) 接口对比
写入方面
元数据组织:
由于 TsFile 的数据逻辑结构是二维的 table,因此构建 writer 仅需 table 的名字以及列的数据类型信息。
而 HDF5 的最底层的数据逻辑结构是 dataset,其支持复杂数据类型以及多维数据,在构建的时候,需要数据的维度信息以及复杂数据类型信息。
数据组织:
TsFile 需要将数据组织为其独有的 tablet 结构,其中会将时间列数据进行单独的组织,从而实现数据的批量写入。
而 HDF5 当中则是将数据组织为多维数组,所有的数据类型都是一视同仁的,其接口内部会根据数组当中的偏移量直接将数据序列化到磁盘。
查询方面
数据复杂查询:
HDF5 当中更加确切的描述为数据的读取,因为其读取是一个 chunk 的数据或者全部数据,数据的处理工作则是与 HDF5 分离。
相比之下,TsFile 所支持的是一种数据查询的工作,在数据获取上是并不全量的读取,而是可以支持仅读取一个 table 当中的部分列数据,同时还支持对读取的列数据进行时间戳或者数值的过滤,这种过滤下推到文件层级,可以有效的减少传输的数据流量。
结果组织:
由于 TsFile 的结构固定为二维的 table,所以仅需获取列的数据类型就可以完成读取的准备工作,同时,TsFile 的数据按批获取的,对于较大数据量的读取工作,可以大大减轻内存的负载。
相比之下,HDF5 的 dataset 由于维度和数据类型相对较为复杂,需要根据维度和类型准备好数据结果的数组容器,才能开展数据的读取。在数据的读取上,HDF5 会将数据一次读取到内存当中,在全量读取上可能会有更好的表现,但是也造成了短时内存负载较高,需要更多的内存资源才能完成相同的数据读取工作。
06 应用案例
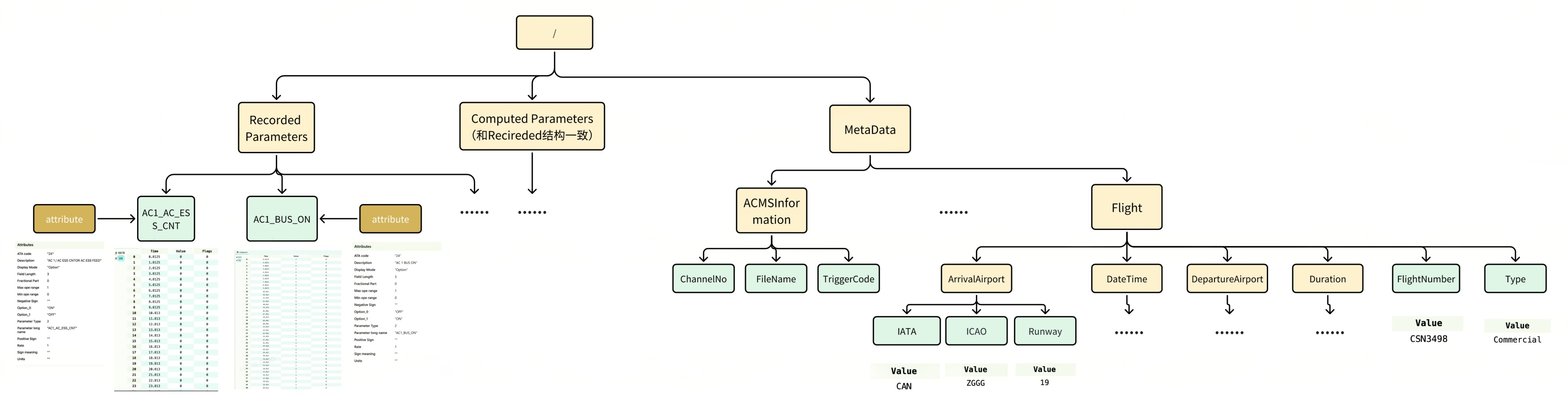
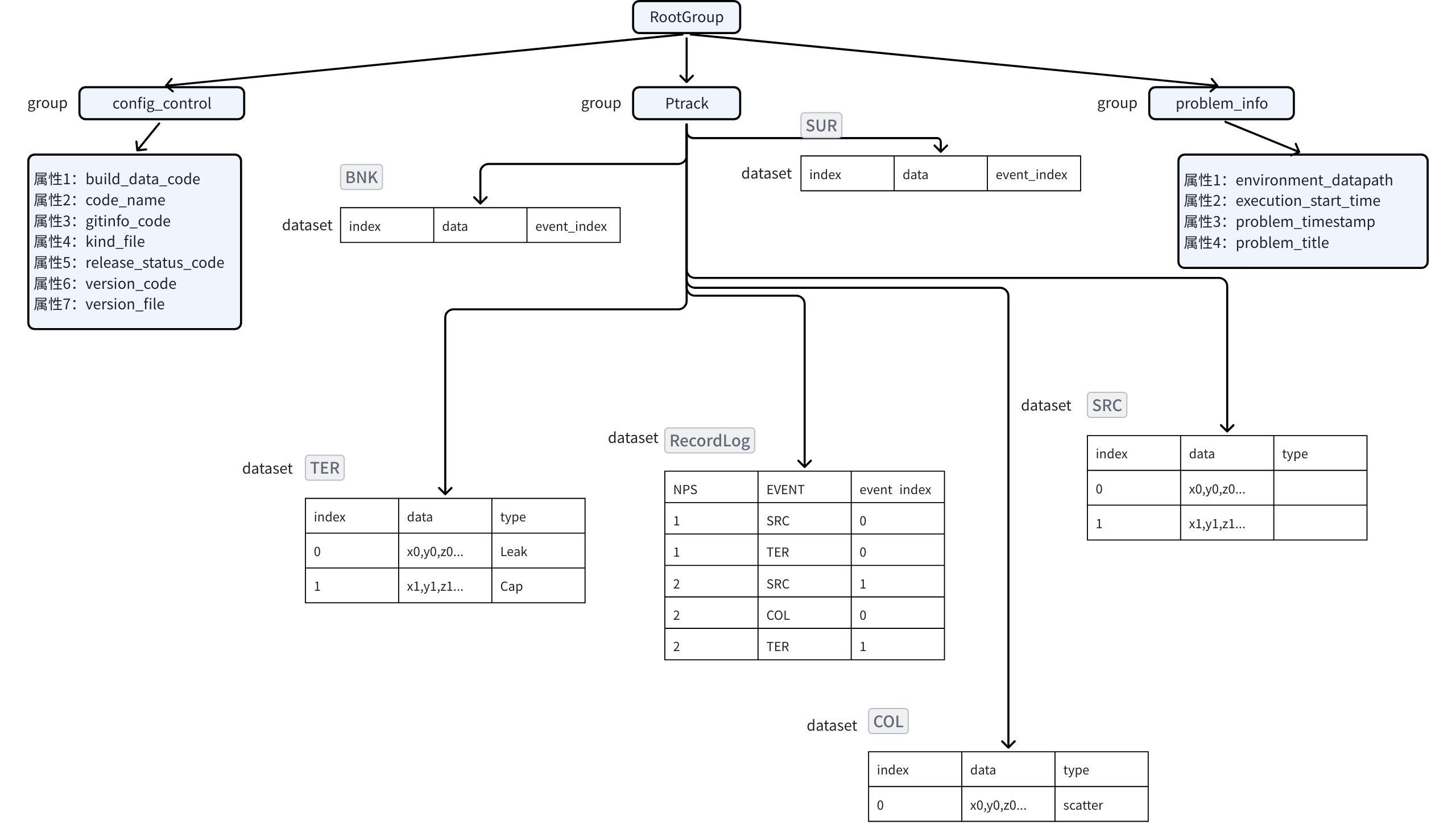
在某航空项目中,数据主要来源于飞机上的传感器。每年大约有上千次飞行,每次飞行约有三到四千个传感器,这些传感器采集了多种类型的参数,每个参数的采样频率和数据长度各不相同。
由于数据量庞大,对存储空间的要求也相应较高。在 HDF5 文件格式中,数据采用组(Group)和数据集(Dataset)的树形结构进行组织,支持通过属性(Attribute)存储元数据。每个参数都单独存储为一个数据集,每个数据集是一个二维表格,包含时间列(time)和值列(value)。HDF5 采用多级 B+树结构,每个组到其所有子组或数据集的映射通过一个 B+ 树记录。
在专为时序数据设计的 TsFile 文件格式中,数据按“设备-测点”的树形结构组织,同一设备的所有测点数据在文件中连续存储,并支持列式压缩。其索引结构为两级 B 树,从根节点到设备,再到时间序列。TsFile 将时间戳(time)和值(value)整合在单个文件中,无需分离存储时间和值列,通过内置索引支持快速数据检索。
在实际应用中,真实飞参数据在 TsFile 格式中的写入和查询性能均优于 HDF5 格式,且相同数据集存储在 HDF5 中压缩后约为 18TB,而在 TsFile 中压缩后仅为 2.2TB。在默认配置下,TsFile 的大小仅为 HDF5 的 14.31%,即 TsFile 的压缩率是 HDF5 的 8 倍。
07 结语
TsFile 在时序模型、编码压缩、查询过滤能力等方面具备优势,且 TsFile 的使用代码也更为简洁,大大降低了学习成本,提升了开发效率,这使得 TsFile 成为处理大规模时间序列数据的理想选择之一。
目前,Apache TsFile 已成为继时序数据库 Apache IoTDB 之后,Apache 时序数据领域第二个 Top-Level 项目,并已在 GitHub 开源:https://github.com/apache/tsfile。我们诚邀更多朋友参与试用,并提供宝贵意见!
更多内容推荐:
• 下载时序数据库 IoTDB 开源版
• 下载时序数据文件格式 TsFile


