
窗口函数
窗口函数
IoTDB 针对时序数据的特色分析场景,提供了窗口函数能力,为时序数据的深度挖掘与复杂计算提供了灵活高效的解决方案。下文将对该功能进行详细的介绍。
1. 功能介绍
窗口函数(Window Function) 是一种基于与当前行相关的特定行集合(称为“窗口”) 对每一行进行计算的特殊函数。它将分组操作(PARTITION BY)、排序(ORDER BY)与可定义的计算范围(窗口框架 FRAME)结合,在不折叠原始数据行的前提下实现复杂的跨行计算。常用于数据分析场景,比如排名、累计和、移动平均等操作。
注意:该功能从 V 2.0.5 版本开始提供。
例如,某场景下需要查询不同设备的功耗累加值,即可通过窗口函数来实现。
-- 原始数据
+-----------------------------+------+-----+
| time|device| flow|
+-----------------------------+------+-----+
|1970-01-01T08:00:00.000+08:00| d0| 3|
|1970-01-01T08:00:00.001+08:00| d0| 5|
|1970-01-01T08:00:00.002+08:00| d0| 3|
|1970-01-01T08:00:00.003+08:00| d0| 1|
|1970-01-01T08:00:00.004+08:00| d1| 2|
|1970-01-01T08:00:00.005+08:00| d1| 4|
+-----------------------------+------+-----+
-- 创建表并插入数据
CREATE TABLE device_flow(device String tag, flow INT32 FIELD);
insert into device_flow(time, device ,flow ) values ('1970-01-01T08:00:00.000+08:00','d0',3),('1970-01-01T08:00:01.000+08:00','d0',5),('1970-01-01T08:00:02.000+08:00','d0',3),('1970-01-01T08:00:03.000+08:00','d0',1),('1970-01-01T08:00:04.000+08:00','d1',2),('1970-01-01T08:00:05.000+08:00','d1',4);
--执行窗口函数查询
SELECT *, sum(flow) OVER(PARTITION BY device ORDER BY flow) as sum FROM device_flow;经过分组、排序、计算(步骤拆解如下图所示),
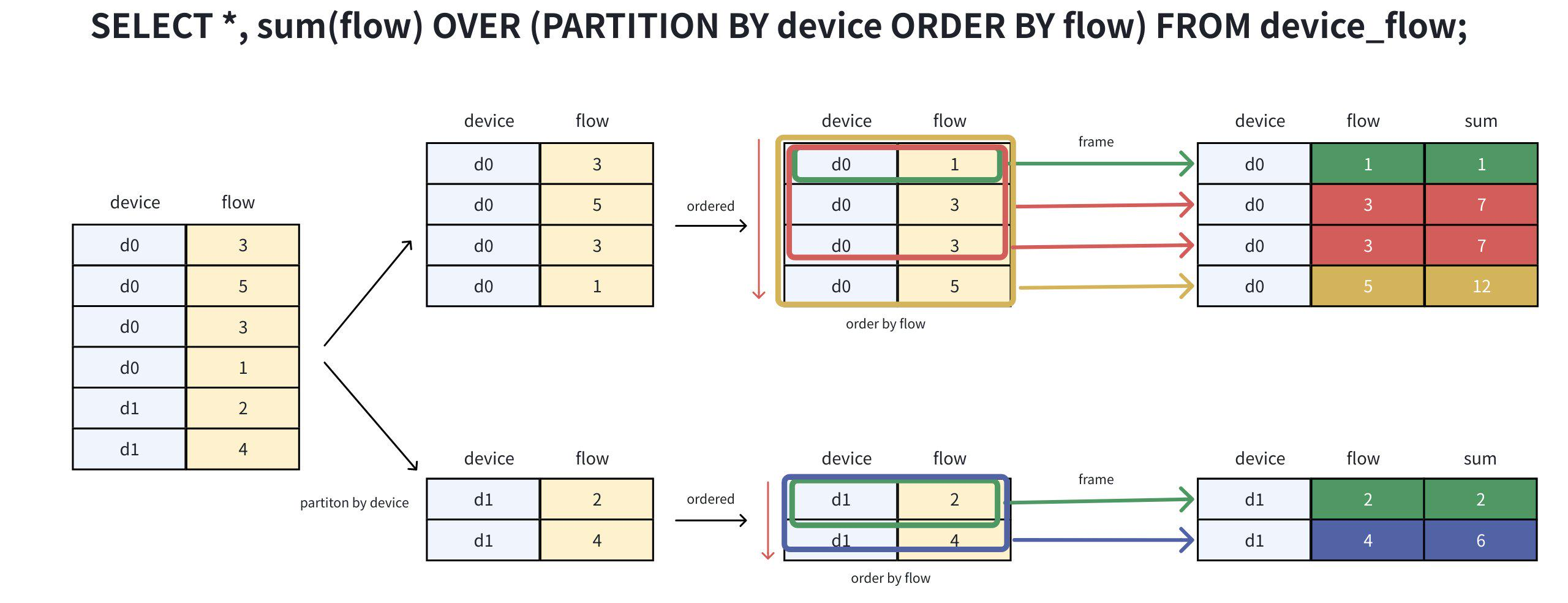
即可得到期望结果:
+-----------------------------+------+----+----+
| time|device|flow| sum|
+-----------------------------+------+----+----+
|1970-01-01T08:00:04.000+08:00| d1| 2| 2.0|
|1970-01-01T08:00:05.000+08:00| d1| 4| 6.0|
|1970-01-01T08:00:03.000+08:00| d0| 1| 1.0|
|1970-01-01T08:00:00.000+08:00| d0| 3| 7.0|
|1970-01-01T08:00:02.000+08:00| d0| 3| 7.0|
|1970-01-01T08:00:01.000+08:00| d0| 5|12.0|
+-----------------------------+------+----+----+2. 功能定义
2.1 SQL 定义
windowDefinition
: name=identifier AS '(' windowSpecification ')'
;
windowSpecification
: (existingWindowName=identifier)?
(PARTITION BY partition+=expression (',' partition+=expression)*)?
(ORDER BY sortItem (',' sortItem)*)?
windowFrame?
;
windowFrame
: frameExtent
;
frameExtent
: frameType=RANGE start=frameBound
| frameType=ROWS start=frameBound
| frameType=GROUPS start=frameBound
| frameType=RANGE BETWEEN start=frameBound AND end=frameBound
| frameType=ROWS BETWEEN start=frameBound AND end=frameBound
| frameType=GROUPS BETWEEN start=frameBound AND end=frameBound
;
frameBound
: UNBOUNDED boundType=PRECEDING #unboundedFrame
| UNBOUNDED boundType=FOLLOWING #unboundedFrame
| CURRENT ROW #currentRowBound
| expression boundType=(PRECEDING | FOLLOWING) #boundedFrame
;2.2 窗口定义
2.2.1 Partition
PARTITION BY 用于将数据分为多个独立、不相关的「组」,窗口函数只能访问并操作其所属分组内的数据,无法访问其它分组。该子句是可选的;如果未显式指定,则默认将所有数据分到同一组。值得注意的是,与 GROUP BY 通过聚合函数将一组数据规约成一行不同,PARTITION BY 的窗口函数并不会影响组内的行数。
- 示例
查询语句:
IoTDB> SELECT *, count(flow) OVER (PARTITION BY device) as count FROM device_flow;拆解步骤:
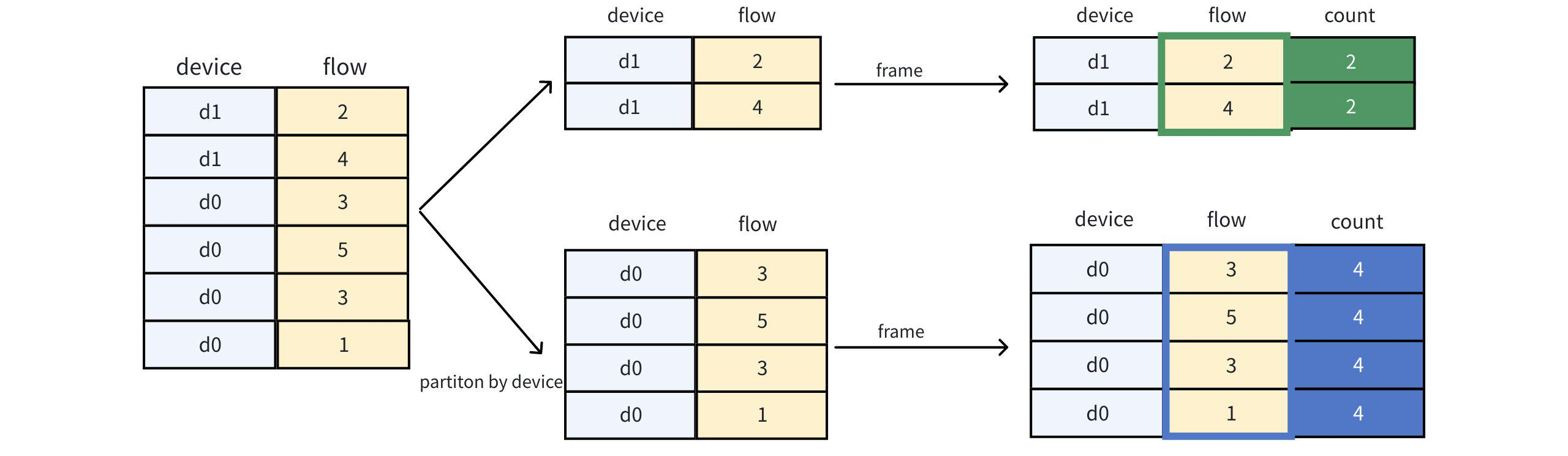
查询结果:
+-----------------------------+------+----+-----+
| time|device|flow|count|
+-----------------------------+------+----+-----+
|1970-01-01T08:00:04.000+08:00| d1| 2| 2|
|1970-01-01T08:00:05.000+08:00| d1| 4| 2|
|1970-01-01T08:00:00.000+08:00| d0| 3| 4|
|1970-01-01T08:00:01.000+08:00| d0| 5| 4|
|1970-01-01T08:00:02.000+08:00| d0| 3| 4|
|1970-01-01T08:00:03.000+08:00| d0| 1| 4|
+-----------------------------+------+----+-----+2.2.2 Ordering
ORDER BY 用于对 partition 内的数据进行排序。排序后,相等的行被称为 peers。peers 会影响窗口函数的行为,例如不同 rank function 对 peers 的处理不同;不同 frame 的划分方式对于 peers 的处理也不同。该子句是可选的。
- 示例
查询语句:
IoTDB> SELECT *, rank() OVER (PARTITION BY device ORDER BY flow) as rank FROM device_flow;拆解步骤:
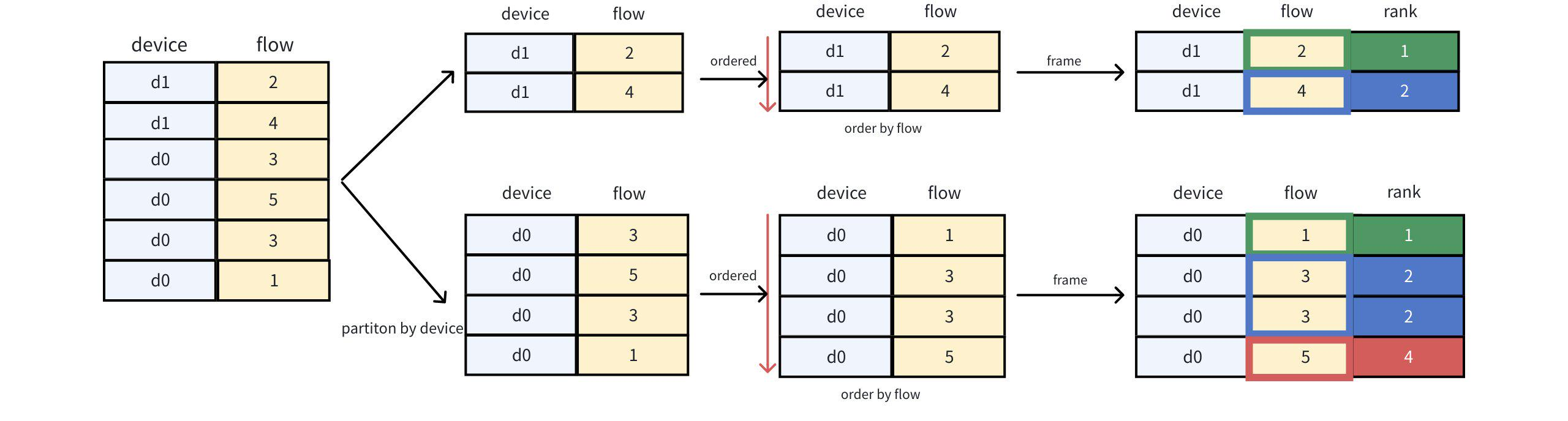
查询结果:
+-----------------------------+------+----+----+
| time|device|flow|rank|
+-----------------------------+------+----+----+
|1970-01-01T08:00:04.000+08:00| d1| 2| 1|
|1970-01-01T08:00:05.000+08:00| d1| 4| 2|
|1970-01-01T08:00:03.000+08:00| d0| 1| 1|
|1970-01-01T08:00:00.000+08:00| d0| 3| 2|
|1970-01-01T08:00:02.000+08:00| d0| 3| 2|
|1970-01-01T08:00:01.000+08:00| d0| 5| 4|
+-----------------------------+------+----+----+2.2.3 Framing
对于 partition 中的每一行,窗口函数都会在相应的一组行上求值,这些行称为 Frame(即 Window Function 在每一行上的输入域)。Frame 可以手动指定,指定时涉及两个属性,具体说明如下。
| Frame 属性 | 属性值 | 值描述 |
|---|---|---|
| 类型 | ROWS | 通过行号来划分 frame |
| GROUPS | 通过 peers 来划分 frame,即值相同的行视为同等的存在。peers 中所有的行分为一个组,叫做 peer group | |
| RANGE | 通过值来划分 frame | |
| 起始和终止位置 | UNBOUNDED PRECEDING | 整个 partition 的第一行 |
| offset PRECEDING | 代表前面和当前行「距离」为 offset 的行 | |
| CURRENT ROW | 当前行 | |
| offset FOLLOWING | 代表后面和当前行「距离」为 offset 的行 | |
| UNBOUNDED FOLLOWING | 整个 partition 的最后一行 |
其中,CURRENT ROW、PRECEDING N 和 FOLLOWING N 的含义随着 frame 种类的不同而不同,如下表所示:
ROWS | GROUPS | RANGE | |
|---|---|---|---|
CURRENT ROW | 当前行 | 由于 peer group 包含多行,因此这个选项根据作用于 frame_start 和 frame_end 而不同:* frame_start:peer group 的第一行;* frame_end:peer group 的最后一行。 | 和 GROUPS 相同,根据作用于 frame_start 和 frame_end 而不同:* frame_start:peer group 的第一行;* frame_end:peer group 的最后一行。 |
offset PRECEDING | 前 offset 行 | 前 offset 个 peer group; | 前面与当前行的值之差小于等于 offset 就分为一个 frame |
offset FOLLOWING | 后 offset 行 | 后 offset 个 peer group。 | 后面与当前行的值之差小于等于 offset 就分为一个 frame |
语法格式如下:
-- 同时指定 frame_start 和 frame_end
{ RANGE | ROWS | GROUPS } BETWEEN frame_start AND frame_end
-- 仅指定 frame_start,frame_end 为 CURRENT ROW
{ RANGE | ROWS | GROUPS } frame_start若未手动指定 Frame,Frame 的默认划分规则如下:
- 当窗口函数使用 ORDER BY 时:默认 Frame 为 RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW (即从窗口的第一行到当前行)。例如:RANK() OVER(PARTITION BY COL1 0RDER BY COL2) 中,Frame 默认包含分区内当前行及之前的所有行。
- 当窗口函数不使用 ORDER BY 时:默认 Frame 为 RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING (即整个窗口的所有行)。例如:AVG(COL2) OVER(PARTITION BY col1) 中,Frame 默认包含分区内的所有行,计算整个分区的平均值。
需要注意的是,当 Frame 类型为 GROUPS 或 RANGE 时,需要指定 ORDER BY,区别在于 GROUPS 中的 ORDER BY 可以涉及多个字段,而 RANGE 需要计算,所以只能指定一个字段。
- 示例
- Frame 类型为 ROWS
查询语句:
IoTDB> SELECT *, count(flow) OVER(PARTITION BY device ROWS 1 PRECEDING) as count FROM device_flow;拆解步骤:
- 取前一行和当前行作为 Frame
- 对于 partition 的第一行,由于没有前一行,所以整个 Frame 只有它一行,返回 1;
- 对于 partition 的其他行,整个 Frame 包含当前行和它的前一行,返回 2:

查询结果:
+-----------------------------+------+----+-----+
| time|device|flow|count|
+-----------------------------+------+----+-----+
|1970-01-01T08:00:04.000+08:00| d1| 2| 1|
|1970-01-01T08:00:05.000+08:00| d1| 4| 2|
|1970-01-01T08:00:00.000+08:00| d0| 3| 1|
|1970-01-01T08:00:01.000+08:00| d0| 5| 2|
|1970-01-01T08:00:02.000+08:00| d0| 3| 2|
|1970-01-01T08:00:03.000+08:00| d0| 1| 2|
+-----------------------------+------+----+-----+- Frame 类型为 GROUPS
查询语句:
IoTDB> SELECT *, count(flow) OVER(PARTITION BY device ORDER BY flow GROUPS BETWEEN 1 PRECEDING AND CURRENT ROW) as count FROM device_flow;拆解步骤:
- 取前一个 peer group 和当前 peer group 作为 Frame,那么以 device 为 d0 的 partition 为例(d1同理),对于 count 行数:
- 对于 flow 为 1 的 peer group,由于它也没比它小的 peer group 了,所以整个 Frame 就它一行,返回 1;
- 对于 flow 为 3 的 peer group,它本身包含 2 行,前一个 peer group 就是 flow 为 1 的,就一行,因此整个 Frame 三行,返回 3;
- 对于 flow 为 5 的 peer group,它本身包含 1 行,前一个 peer group 就是 flow 为 3 的,共两行,因此整个 Frame 三行,返回 3。

查询结果:
+-----------------------------+------+----+-----+
| time|device|flow|count|
+-----------------------------+------+----+-----+
|1970-01-01T08:00:04.000+08:00| d1| 2| 1|
|1970-01-01T08:00:05.000+08:00| d1| 4| 2|
|1970-01-01T08:00:03.000+08:00| d0| 1| 1|
|1970-01-01T08:00:00.000+08:00| d0| 3| 3|
|1970-01-01T08:00:02.000+08:00| d0| 3| 3|
|1970-01-01T08:00:01.000+08:00| d0| 5| 3|
+-----------------------------+------+----+-----+- Frame 类型为 RANGE
查询语句:
IoTDB> SELECT *,count(flow) OVER(PARTITION BY device ORDER BY flow RANGE BETWEEN 2 PRECEDING AND CURRENT ROW) as count FROM device_flow;拆解步骤:
- 把比当前行数据小于等于 2 的分为同一个 Frame,那么以 device 为 d0 的 partition 为例(d1 同理),对于 count 行数:
- 对于 flow 为 1 的行,由于它是最小的行了,所以整个 Frame 就它一行,返回 1;
- 对于 flow 为 3 的行,注意 CURRENT ROW 是作为 frame_end 存在,因此是整个 peer group 的最后一行,符合要求比它小的共 1 行,然后 peer group 有 2 行,所以整个 Frame 共 3 行,返回 3;
- 对于 flow 为 5 的行,它本身包含 1 行,符合要求的比它小的共 2 行,所以整个 Frame 共 3 行,返回 3。

查询结果:
+-----------------------------+------+----+-----+
| time|device|flow|count|
+-----------------------------+------+----+-----+
|1970-01-01T08:00:04.000+08:00| d1| 2| 1|
|1970-01-01T08:00:05.000+08:00| d1| 4| 2|
|1970-01-01T08:00:03.000+08:00| d0| 1| 1|
|1970-01-01T08:00:00.000+08:00| d0| 3| 3|
|1970-01-01T08:00:02.000+08:00| d0| 3| 3|
|1970-01-01T08:00:01.000+08:00| d0| 5| 3|
+-----------------------------+------+----+-----+3. 内置的窗口函数
| 窗口函数分类 | 窗口函数名 | 函数定义 | 是否支持 FRAME 子句 |
|---|---|---|---|
| Aggregate Function | 所有内置聚合函数 | 对一组值进行聚合计算,得到单个聚合结果。 | 是 |
| Value Function | first_value | 返回 frame 的第一个值,如果指定了 IGNORE NULLS 需要跳过前缀的 NULL | 是 |
| last_value | 返回 frame 的最后一个值,如果指定了 IGNORE NULLS 需要跳过后缀的 NULL | 是 | |
| nth_value | 返回 frame 的第 n 个元素(注意 n 是从 1 开始),如果有 IGNORE NULLS 需要跳过 NULL | 是 | |
| lead | 返回当前行的后 offset 个元素(如果有 IGNORE NULLS 则 NULL 不考虑在内),如果没有这样的元素(超过 partition 范围),则返回 default | 否 | |
| lag | 返回当前行的前 offset 个元素(如果有 IGNORE NULLS 则 NULL 不考虑在内),如果没有这样的元素(超过 partition 范围),则返回 default | 否 | |
| Rank Function | rank | 返回当前行在整个 partition 中的序号,值相同的行序号相同,序号之间可能有 gap | 否 |
| dense_rank | 返回当前行在整个 partition 中的序号,值相同的行序号相同,序号之间没有 gap | 否 | |
| row_number | 返回当前行在整个 partition 中的行号,注意行号从 1 开始 | 否 | |
| percent_rank | 以百分比的形式,返回当前行的值在整个 partition 中的序号;即 (rank() - 1) / (n - 1),其中 n 是整个 partition 的行数 | 否 | |
| cume_dist | 以百分比的形式,返回当前行的值在整个 partition 中的序号;即 (小于等于它的行数) / n | 否 | |
| ntile | 指定 n,给每一行进行 1~n 的编号。 | 否 |
3.1 Aggregate Function
所有内置聚合函数,如 sum()、avg()、min()、max() 都能当作 Window Function 使用。
注意:与 GROUP BY 不同,Window Function 中每一行都有相应的输出
示例:
IoTDB> SELECT *, sum(flow) OVER (PARTITION BY device ORDER BY flow) as sum FROM device_flow;
+-----------------------------+------+----+----+
| time|device|flow| sum|
+-----------------------------+------+----+----+
|1970-01-01T08:00:04.000+08:00| d1| 2| 2.0|
|1970-01-01T08:00:05.000+08:00| d1| 4| 6.0|
|1970-01-01T08:00:03.000+08:00| d0| 1| 1.0|
|1970-01-01T08:00:00.000+08:00| d0| 3| 7.0|
|1970-01-01T08:00:02.000+08:00| d0| 3| 7.0|
|1970-01-01T08:00:01.000+08:00| d0| 5|12.0|
+-----------------------------+------+----+----+3.2 Value Function
first_value
- 函数名:
first_value(value) [IGNORE NULLS] - 定义:返回 frame 的第一个值,如果指定了 IGNORE NULLS 需要跳过前缀的 NULL;
- 示例:
IoTDB> SELECT *, first_value(flow) OVER w as first_value FROM device_flow WINDOW w AS (PARTITION BY device ORDER BY flow ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING);
+-----------------------------+------+----+-----------+
| time|device|flow|first_value|
+-----------------------------+------+----+-----------+
|1970-01-01T08:00:04.000+08:00| d1| 2| 2|
|1970-01-01T08:00:05.000+08:00| d1| 4| 2|
|1970-01-01T08:00:03.000+08:00| d0| 1| 1|
|1970-01-01T08:00:00.000+08:00| d0| 3| 1|
|1970-01-01T08:00:02.000+08:00| d0| 3| 3|
|1970-01-01T08:00:01.000+08:00| d0| 5| 3|
+-----------------------------+------+----+-----------+last_value
- 函数名:
last_value(value) [IGNORE NULLS] - 定义:返回 frame 的最后一个值,如果指定了 IGNORE NULLS 需要跳过后缀的 NULL;
- 示例:
IoTDB> SELECT *, last_value(flow) OVER w as last_value FROM device_flow WINDOW w AS (PARTITION BY device ORDER BY flow ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING);
+-----------------------------+------+----+----------+
| time|device|flow|last_value|
+-----------------------------+------+----+----------+
|1970-01-01T08:00:04.000+08:00| d1| 2| 4|
|1970-01-01T08:00:05.000+08:00| d1| 4| 4|
|1970-01-01T08:00:03.000+08:00| d0| 1| 3|
|1970-01-01T08:00:00.000+08:00| d0| 3| 3|
|1970-01-01T08:00:02.000+08:00| d0| 3| 5|
|1970-01-01T08:00:01.000+08:00| d0| 5| 5|
+-----------------------------+------+----+----------+nth_value
- 函数名:
nth_value(value, n) [IGNORE NULLS] - 定义:返回 frame 的第 n 个元素(注意 n 是从 1 开始),如果有 IGNORE NULLS 需要跳过 NULL;
- 示例:
IoTDB> SELECT *, nth_value(flow, 2) OVER w as nth_values FROM device_flow WINDOW w AS (PARTITION BY device ORDER BY flow ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING);
+-----------------------------+------+----+----------+
| time|device|flow|nth_values|
+-----------------------------+------+----+----------+
|1970-01-01T08:00:04.000+08:00| d1| 2| 4|
|1970-01-01T08:00:05.000+08:00| d1| 4| 4|
|1970-01-01T08:00:03.000+08:00| d0| 1| 3|
|1970-01-01T08:00:00.000+08:00| d0| 3| 3|
|1970-01-01T08:00:02.000+08:00| d0| 3| 3|
|1970-01-01T08:00:01.000+08:00| d0| 5| 5|
+-----------------------------+------+----+----------+- lead
- 函数名:
lead(value[, offset[, default]]) [IGNORE NULLS] - 定义:返回当前行的后 offset 个元素(如果有 IGNORE NULLS 则 NULL 不考虑在内),如果没有这样的元素(超过 partition 范围),则返回 default;offset 的默认值为 1,default 的默认值为 NULL。
- lead 函数需要需要一个 ORDER BY 窗口子句
- 示例:
IoTDB> SELECT *, lead(flow) OVER w as lead FROM device_flow WINDOW w AS(PARTITION BY device ORDER BY time);
+-----------------------------+------+----+----+
| time|device|flow|lead|
+-----------------------------+------+----+----+
|1970-01-01T08:00:04.000+08:00| d1| 2| 4|
|1970-01-01T08:00:05.000+08:00| d1| 4|null|
|1970-01-01T08:00:00.000+08:00| d0| 3| 5|
|1970-01-01T08:00:01.000+08:00| d0| 5| 3|
|1970-01-01T08:00:02.000+08:00| d0| 3| 1|
|1970-01-01T08:00:03.000+08:00| d0| 1|null|
+-----------------------------+------+----+----+- lag
- 函数名:
lag(value[, offset[, default]]) [IGNORE NULLS] - 定义:返回当前行的前 offset 个元素(如果有 IGNORE NULLS 则 NULL 不考虑在内),如果没有这样的元素(超过 partition 范围),则返回 default;offset 的默认值为 1,default 的默认值为 NULL。
- lag 函数需要需要一个 ORDER BY 窗口子句
- 示例:
IoTDB> SELECT *, lag(flow) OVER w as lag FROM device_flow WINDOW w AS(PARTITION BY device ORDER BY device);
+-----------------------------+------+----+----+
| time|device|flow| lag|
+-----------------------------+------+----+----+
|1970-01-01T08:00:04.000+08:00| d1| 2|null|
|1970-01-01T08:00:05.000+08:00| d1| 4| 2|
|1970-01-01T08:00:00.000+08:00| d0| 3|null|
|1970-01-01T08:00:01.000+08:00| d0| 5| 3|
|1970-01-01T08:00:02.000+08:00| d0| 3| 5|
|1970-01-01T08:00:03.000+08:00| d0| 1| 3|
+-----------------------------+------+----+----+3.3 Rank Function
- rank
- 函数名:
rank() - 定义:返回当前行在整个 partition 中的序号,值相同的行序号相同,序号之间可能有 gap;
- 示例:
IoTDB> SELECT *, rank() OVER w as rank FROM device_flow WINDOW w AS (PARTITION BY device ORDER BY flow);
+-----------------------------+------+----+----+
| time|device|flow|rank|
+-----------------------------+------+----+----+
|1970-01-01T08:00:04.000+08:00| d1| 2| 1|
|1970-01-01T08:00:05.000+08:00| d1| 4| 2|
|1970-01-01T08:00:03.000+08:00| d0| 1| 1|
|1970-01-01T08:00:00.000+08:00| d0| 3| 2|
|1970-01-01T08:00:02.000+08:00| d0| 3| 2|
|1970-01-01T08:00:01.000+08:00| d0| 5| 4|
+-----------------------------+------+----+----+- dense_rank
- 函数名:
dense_rank() - 定义:返回当前行在整个 partition 中的序号,值相同的行序号相同,序号之间没有 gap。
- 示例:
IoTDB> SELECT *, dense_rank() OVER w as dense_rank FROM device_flow WINDOW w AS (PARTITION BY device ORDER BY flow);
+-----------------------------+------+----+----------+
| time|device|flow|dense_rank|
+-----------------------------+------+----+----------+
|1970-01-01T08:00:04.000+08:00| d1| 2| 1|
|1970-01-01T08:00:05.000+08:00| d1| 4| 2|
|1970-01-01T08:00:03.000+08:00| d0| 1| 1|
|1970-01-01T08:00:00.000+08:00| d0| 3| 2|
|1970-01-01T08:00:02.000+08:00| d0| 3| 2|
|1970-01-01T08:00:01.000+08:00| d0| 5| 3|
+-----------------------------+------+----+----------+- row_number
- 函数名:
row_number() - 定义:返回当前行在整个 partition 中的行号,注意行号从 1 开始;
- 示例:
IoTDB> SELECT *, row_number() OVER w as row_number FROM device_flow WINDOW w AS (PARTITION BY device ORDER BY flow);
+-----------------------------+------+----+----------+
| time|device|flow|row_number|
+-----------------------------+------+----+----------+
|1970-01-01T08:00:04.000+08:00| d1| 2| 1|
|1970-01-01T08:00:05.000+08:00| d1| 4| 2|
|1970-01-01T08:00:03.000+08:00| d0| 1| 1|
|1970-01-01T08:00:00.000+08:00| d0| 3| 2|
|1970-01-01T08:00:02.000+08:00| d0| 3| 3|
|1970-01-01T08:00:01.000+08:00| d0| 5| 4|
+-----------------------------+------+----+----------+- percent_rank
- 函数名:
percent_rank() - 定义:以百分比的形式,返回当前行的值在整个 partition 中的序号;即 (rank() - 1) / (n - 1),其中 n 是整个 partition 的行数;
- 示例:
IoTDB> SELECT *, percent_rank() OVER w as percent_rank FROM device_flow WINDOW w AS (PARTITION BY device ORDER BY flow);
+-----------------------------+------+----+------------------+
| time|device|flow| percent_rank|
+-----------------------------+------+----+------------------+
|1970-01-01T08:00:04.000+08:00| d1| 2| 0.0|
|1970-01-01T08:00:05.000+08:00| d1| 4| 1.0|
|1970-01-01T08:00:03.000+08:00| d0| 1| 0.0|
|1970-01-01T08:00:00.000+08:00| d0| 3|0.3333333333333333|
|1970-01-01T08:00:02.000+08:00| d0| 3|0.3333333333333333|
|1970-01-01T08:00:01.000+08:00| d0| 5| 1.0|
+-----------------------------+------+----+------------------+- cume_dist
- 函数名:cume_dist
- 定义:以百分比的形式,返回当前行的值在整个 partition 中的序号;即 (小于等于它的行数) / n。
- 示例:
IoTDB> SELECT *, cume_dist() OVER w as cume_dist FROM device_flow WINDOW w AS (PARTITION BY device ORDER BY flow);
+-----------------------------+------+----+---------+
| time|device|flow|cume_dist|
+-----------------------------+------+----+---------+
|1970-01-01T08:00:04.000+08:00| d1| 2| 0.5|
|1970-01-01T08:00:05.000+08:00| d1| 4| 1.0|
|1970-01-01T08:00:03.000+08:00| d0| 1| 0.25|
|1970-01-01T08:00:00.000+08:00| d0| 3| 0.75|
|1970-01-01T08:00:02.000+08:00| d0| 3| 0.75|
|1970-01-01T08:00:01.000+08:00| d0| 5| 1.0|
+-----------------------------+------+----+---------+- ntile
- 函数名:ntile
- 定义:指定 n,给每一行进行 1~n 的编号。
- 整个 partition 行数比 n 小,那么编号就是行号 index;
- 整个 partition 行数比 n 大:
- 如果行数能除尽 n,那么比较完美,比如行数为 4,n 为 2,那么编号为 1、1、2、2、;
- 如果行数不能除尽 n,那么就分给开头几组,比如行数为 5,n 为 3,那么编号为 1、1、2、2、3;
- 示例:
IoTDB> SELECT *, ntile(2) OVER w as ntile FROM device_flow WINDOW w AS (PARTITION BY device ORDER BY flow);
+-----------------------------+------+----+-----+
| time|device|flow|ntile|
+-----------------------------+------+----+-----+
|1970-01-01T08:00:04.000+08:00| d1| 2| 1|
|1970-01-01T08:00:05.000+08:00| d1| 4| 2|
|1970-01-01T08:00:03.000+08:00| d0| 1| 1|
|1970-01-01T08:00:00.000+08:00| d0| 3| 1|
|1970-01-01T08:00:02.000+08:00| d0| 3| 2|
|1970-01-01T08:00:01.000+08:00| d0| 5| 2|
+-----------------------------+------+----+-----+4. 场景示例
- 多设备 diff 函数
对于每个设备的每一行,与前一行求差值:
SELECT
*,
measurement - lag(measurement) OVER (PARTITION BY device ORDER BY time)
FROM data
WHERE timeCondition;对于每个设备的每一行,与后一行求差值:
SELECT
*,
measurement - lead(measurement) OVER (PARTITION BY device ORDER BY time)
FROM data
WHERE timeCondition;对于单个设备的每一行,与前一行求差值(后一行同理):
SELECT
*,
measurement - lag(measurement) OVER (ORDER BY time)
FROM data
where device='d1'
WHERE timeCondition;- 多设备 TOP_K/BOTTOM_K
利用 rank 获取序号,然后在外部的查询中保留想要的顺序。
(注意, window function 的执行顺序在 HAVING 子句之后,所以这里需要子查询)
SELECT *
FROM(
SELECT
*,
rank() OVER (PARTITION BY device ORDER BY time DESC)
FROM data
WHERE timeCondition
)
WHERE rank <= 3;除了按照时间排序之外,还可以按照测点的值进行排序:
SELECT *
FROM(
SELECT
*,
rank() OVER (PARTITION BY device ORDER BY measurement DESC)
FROM data
WHERE timeCondition
)
WHERE rank <= 3;- 多设备 CHANGE_POINTS
这个 sql 用来去除输入序列中连续相同值,可以用 lead + 子查询实现:
SELECT
time,
device,
measurement
FROM(
SELECT
time,
device,
measurement,
LEAD(measurement) OVER (PARTITION BY device ORDER BY time) AS next
FROM data
WHERE timeCondition
)
WHERE measurement != next OR next IS NULL;